 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDDLGym: A Tool for Studying Multi-Agent Hierarchical Problems Defined in HDDL with OpenAI Gym
May 28, 2025In recent years, reinforcement learning (RL) methods have been widely tested using tools like OpenAI Gym, though many tasks in these environments could also benefit from hierarchical planning. However, there is a lack of a tool that enables seamless integration of hierarchical planning with RL. Hierarchical Domain Definition Language (HDDL), used in classical planning, introduces a structured approach well-suited for model-based RL to address this gap. To bridge this integration, we introduce HDDLGym, a Python-based tool that automatically generates OpenAI Gym environments from HDDL domains and problems. HDDLGym serves as a link between RL and hierarchical planning, supporting multi-agent scenarios and enabling collaborative planning among agents. This paper provides an overview of HDDLGym's design and implementation, highlighting the challenges and design choices involved in integrating HDDL with the Gym interface, and applying RL policies to support hierarchical planning. We also provide detailed instructions and demonstrations for using the HDDLGym framework, including how to work with existing HDDL domains and problems from International Planning Competitions, exemplified by the Transport domain. Additionally, we offer guidance on creating new HDDL domains for multi-agent scenarios and demonstrate the practical use of HDDLGym in the Overcooked domain. By leveraging the advantages of HDDL and Gym, HDDLGym aims to be a valuable tool for studying RL in hierarchical planning, particularly in multi-agent contexts.
Partner Modelling Emerges in Recurrent Agents (But Only When It Matters)
May 22, 2025Humans are remarkably adept at collaboration, able to infer the strengths and weaknesses of new partners in order to work successfully towards shared goals. To build AI systems with this capability, we must first understand its building blocks: does such flexibility require explicit, dedicated mechanisms for modelling others -- or can it emerge spontaneously from the pressures of open-ended cooperative interaction? To investigate this question, we train simple model-free RNN agents to collaborate with a population of diverse partners. Using the `Overcooked-AI' environment, we collect data from thousands of collaborative teams, and analyse agents' internal hidden states. Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. We investigated these internal models through probing techniques, and large-scale behavioural analysis. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation. Our results show that partner modelling can arise spontaneously in model-free agents -- but only under environmental conditions that impose the right kind of social pressure.
Predicting Multi-Agent Specialization via Task Parallelizability
Mar 19, 2025Multi-agent systems often rely on specialized agents with distinct roles rather than general-purpose agents that perform the entire task independently. However, the conditions that govern the optimal degree of specialization remain poorly understood. In this work, we propose that specialist teams outperform generalist ones when environmental constraints limit task parallelizability -- the potential to execute task components concurrently. Drawing inspiration from distributed systems, we introduce a heuristic to predict the relative efficiency of generalist versus specialist teams by estimating the speed-up achieved when two agents perform a task in parallel rather than focus on complementary subtasks. We validate this heuristic through three multi-agent reinforcement learning (MARL) experiments in Overcooked-AI, demonstrating that key factors limiting task parallelizability influence specialization. We also observe that as the state space expands, agents tend to converge on specialist strategies, even when generalist ones are theoretically more efficient, highlighting potential biases in MARL training algorithms. Our findings provide a principled framework for interpreting specialization given the task and environment, and introduce a novel benchmark for evaluating whether MARL finds optimal strategies.
Learning Precise Affordances from Egocentric Videos for Robotic Manipulation
Aug 19, 2024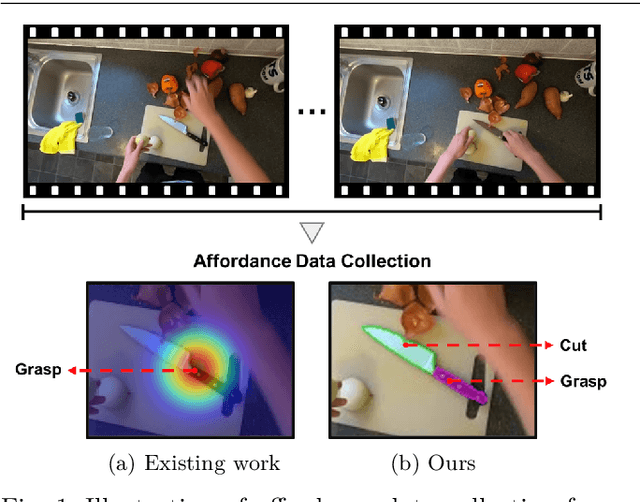

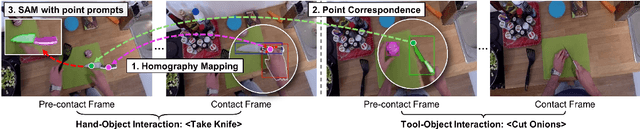
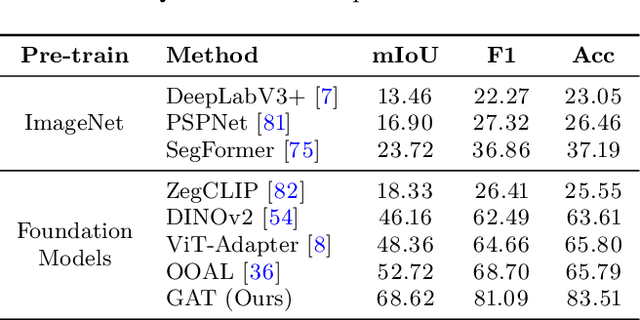
Affordance, defined as the potential actions that an object offers, is crucial for robotic manipulation tasks. A deep understanding of affordance can lead to more intelligent AI systems. For example, such knowledge directs an agent to grasp a knife by the handle for cutting and by the blade when passing it to someone. In this paper, we present a streamlined affordance learning system that encompasses data collection, effective model training, and robot deployment. First, we collect training data from egocentric videos in an automatic manner. Different from previous methods that focus only on the object graspable affordance and represent it as coarse heatmaps, we cover both graspable (e.g., object handles) and functional affordances (e.g., knife blades, hammer heads) and extract data with precise segmentation masks. We then propose an effective model, termed Geometry-guided Affordance Transformer (GKT), to train on the collected data. GKT integrates an innovative Depth Feature Injector (DFI) to incorporate 3D shape and geometric priors, enhancing the model's understanding of affordances. To enable affordance-oriented manipulation, we further introduce Aff-Grasp, a framework that combines GKT with a grasp generation model. For comprehensive evaluation, we create an affordance evaluation dataset with pixel-wise annotations, and design real-world tasks for robot experiments. The results show that GKT surpasses the state-of-the-art by 15.9% in mIoU, and Aff-Grasp achieves high success rates of 95.5% in affordance prediction and 77.1% in successful grasping among 179 trials, including evaluations with seen, unseen objects, and cluttered scenes.
Enabling robots to follow abstract instructions and complete complex dynamic tasks
Jun 17, 2024



Completing complex tasks in unpredictable settings like home kitchens challenges robotic systems. These challenges include interpreting high-level human commands, such as "make me a hot beverage" and performing actions like pouring a precise amount of water into a moving mug. To address these challenges, we present a novel framework that combines Large Language Models (LLMs), a curated Knowledge Base, and Integrated Force and Visual Feedback (IFVF). Our approach interprets abstract instructions, performs long-horizon tasks, and handles various uncertainties. It utilises GPT-4 to analyse the user's query and surroundings, then generates code that accesses a curated database of functions during execution. It translates abstract instructions into actionable steps. Each step involves generating custom code by employing retrieval-augmented generalisation to pull IFVF-relevant examples from the Knowledge Base. IFVF allows the robot to respond to noise and disturbances during execution. We use coffee making and plate decoration to demonstrate our approach, including components ranging from pouring to drawer opening, each benefiting from distinct feedback types and methods. This novel advancement marks significant progress toward a scalable, efficient robotic framework for completing complex tasks in uncertain environments. Our findings are illustrated in an accompanying video and supported by an open-source GitHub repository (released upon paper acceptance).
A behavioural transformer for effective collaboration between a robot and a non-stationary human
Jul 25, 2023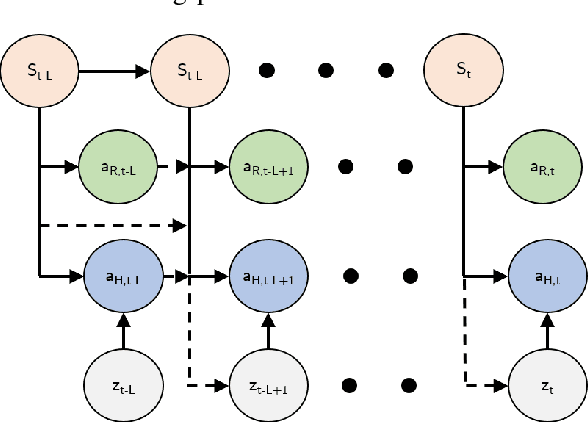
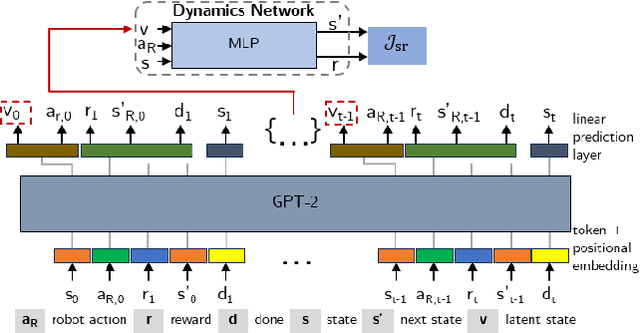
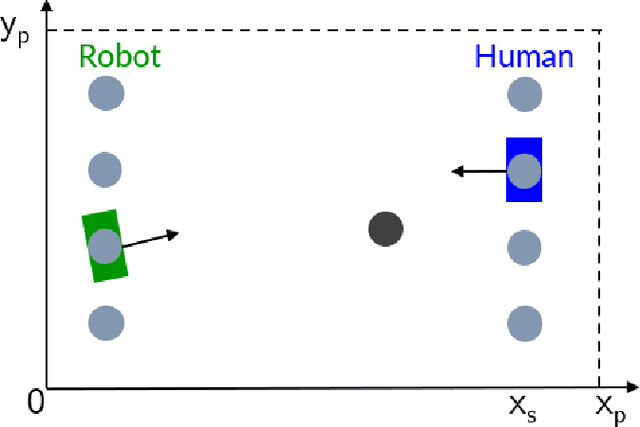
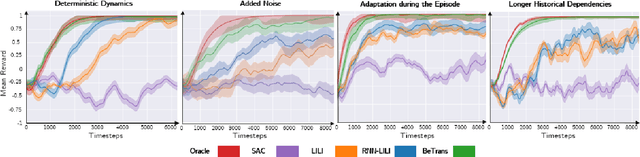
A key challenge in human-robot collaboration is the non-stationarity created by humans due to changes in their behaviour. This alters environmental transitions and hinders human-robot collaboration. We propose a principled meta-learning framework to explore how robots could better predict human behaviour, and thereby deal with issues of non-stationarity. On the basis of this framework, we developed Behaviour-Transform (BeTrans). BeTrans is a conditional transformer that enables a robot agent to adapt quickly to new human agents with non-stationary behaviours, due to its notable performance with sequential data. We trained BeTrans on simulated human agents with different systematic biases in collaborative settings. We used an original customisable environment to show that BeTrans effectively collaborates with simulated human agents and adapts faster to non-stationary simulated human agents than SOTA techniques.