 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling robots to follow abstract instructions and complete complex dynamic tasks
Jun 17, 2024



Completing complex tasks in unpredictable settings like home kitchens challenges robotic systems. These challenges include interpreting high-level human commands, such as "make me a hot beverage" and performing actions like pouring a precise amount of water into a moving mug. To address these challenges, we present a novel framework that combines Large Language Models (LLMs), a curated Knowledge Base, and Integrated Force and Visual Feedback (IFVF). Our approach interprets abstract instructions, performs long-horizon tasks, and handles various uncertainties. It utilises GPT-4 to analyse the user's query and surroundings, then generates code that accesses a curated database of functions during execution. It translates abstract instructions into actionable steps. Each step involves generating custom code by employing retrieval-augmented generalisation to pull IFVF-relevant examples from the Knowledge Base. IFVF allows the robot to respond to noise and disturbances during execution. We use coffee making and plate decoration to demonstrate our approach, including components ranging from pouring to drawer opening, each benefiting from distinct feedback types and methods. This novel advancement marks significant progress toward a scalable, efficient robotic framework for completing complex tasks in uncertain environments. Our findings are illustrated in an accompanying video and supported by an open-source GitHub repository (released upon paper acceptance).
Universal Marginaliser for Deep Amortised Inference for Probabilistic Programs
Oct 16, 2019
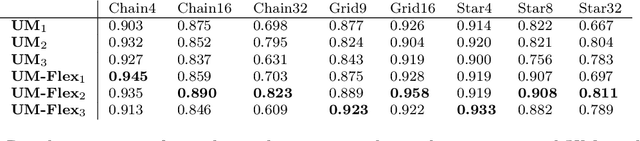
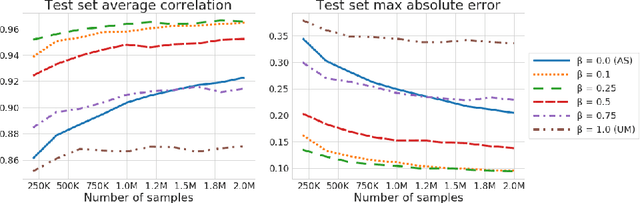
Probabilistic programming languages (PPLs) are powerful modelling tools which allow to formalise our knowledge about the world and reason about its inherent uncertainty. Inference methods used in PPL can be computationally costly due to significant time burden and/or storage requirements; or they can lack theoretical guarantees of convergence and accuracy when applied to large scale graphical models. To this end, we present the Universal Marginaliser (UM), a novel method for amortised inference, in PPL. We show how combining samples drawn from the original probabilistic program prior with an appropriate augmentation method allows us to train one neural network to approximate any of the corresponding conditional marginal distributions, with any separation into latent and observed variables, and thus amortise the cost of inference. Finally, we benchmark the method on multiple probabilistic programs, in Pyro, with different model structure.
A Universal Marginalizer for Amortized Inference in Generative Models
Nov 02, 2017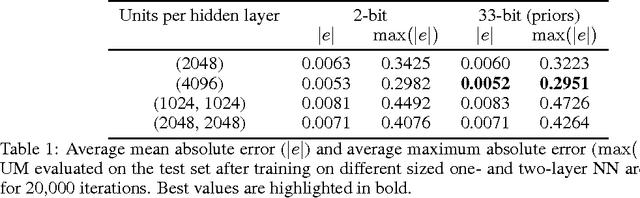
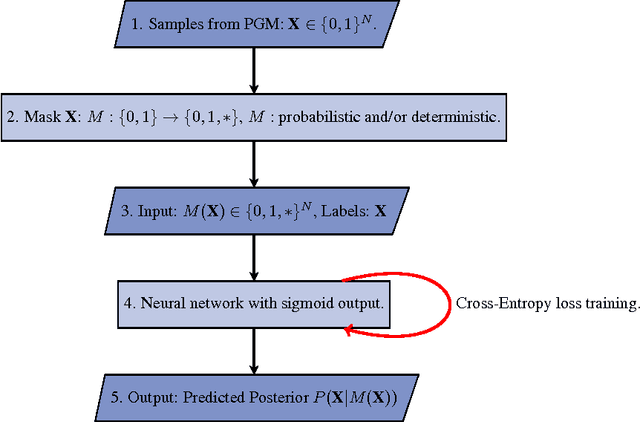
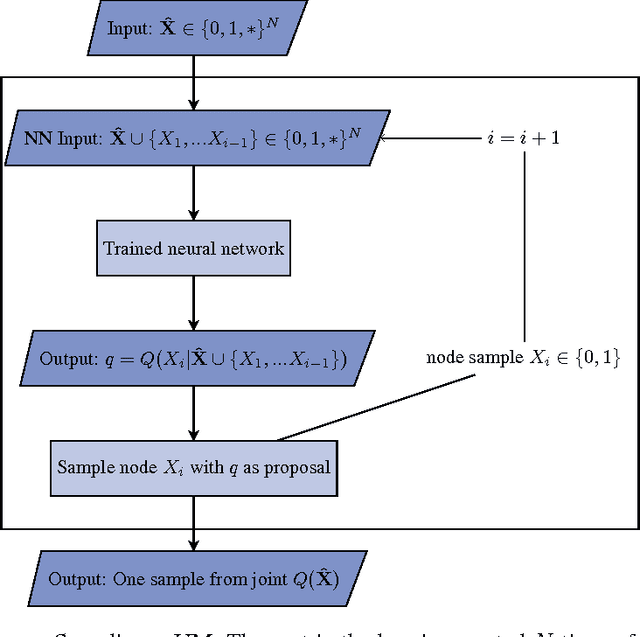
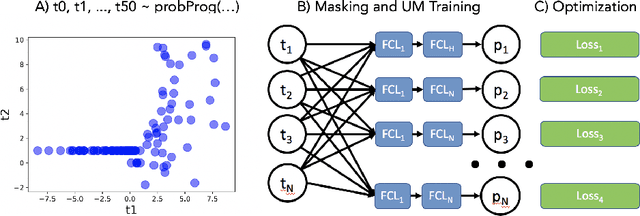
We consider the problem of inference in a causal generative model where the set of available observations differs between data instances. We show how combining samples drawn from the graphical model with an appropriate masking function makes it possible to train a single neural network to approximate all the corresponding conditional marginal distributions and thus amortize the cost of inference. We further demonstrate that the efficiency of importance sampling may be improved by basing proposals on the output of the neural network. We also outline how the same network can be used to generate samples from an approximate joint posterior via a chain decomposition of the graph.