 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Marginaliser for Deep Amortised Inference for Probabilistic Programs
Oct 16, 2019
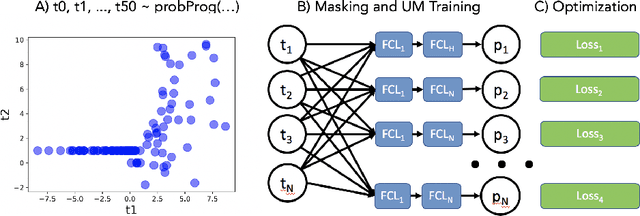
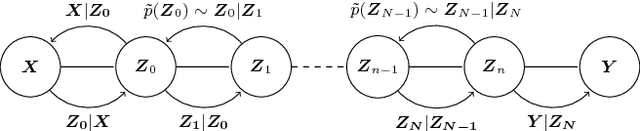
Probabilistic programming languages (PPLs) are powerful modelling tools which allow to formalise our knowledge about the world and reason about its inherent uncertainty. Inference methods used in PPL can be computationally costly due to significant time burden and/or storage requirements; or they can lack theoretical guarantees of convergence and accuracy when applied to large scale graphical models. To this end, we present the Universal Marginaliser (UM), a novel method for amortised inference, in PPL. We show how combining samples drawn from the original probabilistic program prior with an appropriate augmentation method allows us to train one neural network to approximate any of the corresponding conditional marginal distributions, with any separation into latent and observed variables, and thus amortise the cost of inference. Finally, we benchmark the method on multiple probabilistic programs, in Pyro, with different model structure.
SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Jan 09, 2019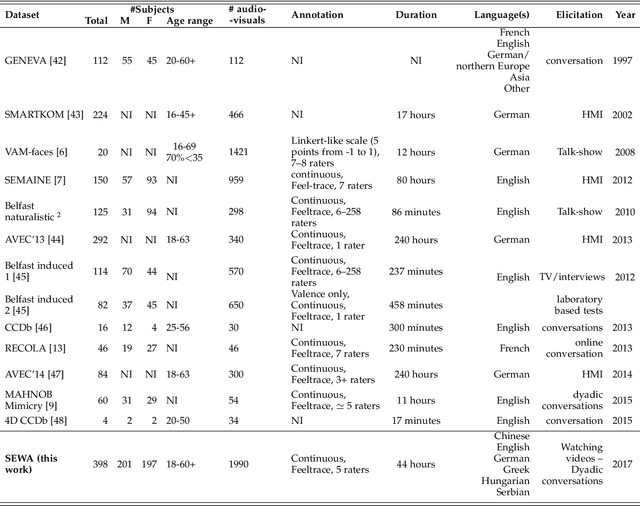
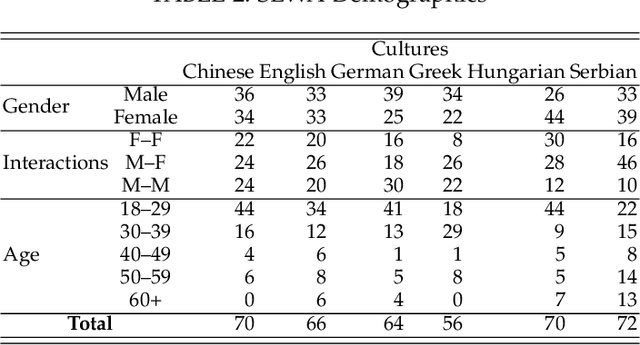

Natural human-computer interaction and audio-visual human behaviour sensing systems, which would achieve robust performance in-the-wild are more needed than ever as digital devices are becoming indispensable part of our life more and more. Accurately annotated real-world data are the crux in devising such systems. However, existing databases usually consider controlled settings, low demographic variability, and a single task. In this paper, we introduce the SEWA database of more than 2000 minutes of audio-visual data of 398 people coming from six cultures, 50% female, and uniformly spanning the age range of 18 to 65 years old. Subjects were recorded in two different contexts: while watching adverts and while discussing adverts in a video chat. The database includes rich annotations of the recordings in terms of facial landmarks, facial action units (FAU), various vocalisations, mirroring, and continuously valued valence, arousal, liking, agreement, and prototypic examples of (dis)liking. This database aims to be an extremely valuable resource for researchers in affective computing and automatic human sensing and is expected to push forward the research in human behaviour analysis, including cultural studies. Along with the database, we provide extensive baseline experiments for automatic FAU detection and automatic valence, arousal and (dis)liking intensity estimation.
Universal Marginalizer for Amortised Inference and Embedding of Generative Models
Nov 12, 2018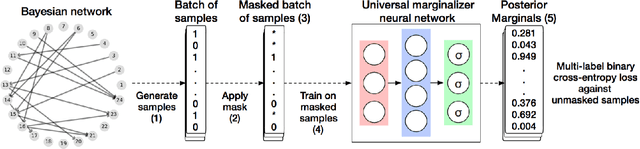


Probabilistic graphical models are powerful tools which allow us to formalise our knowledge about the world and reason about its inherent uncertainty. There exist a considerable number of methods for performing inference in probabilistic graphical models; however, they can be computationally costly due to significant time burden and/or storage requirements; or they lack theoretical guarantees of convergence and accuracy when applied to large scale graphical models. To this end, we propose the Universal Marginaliser Importance Sampler (UM-IS) -- a hybrid inference scheme that combines the flexibility of a deep neural network trained on samples from the model and inherits the asymptotic guarantees of importance sampling. We show how combining samples drawn from the graphical model with an appropriate masking function allows us to train a single neural network to approximate any of the corresponding conditional marginal distributions, and thus amortise the cost of inference. We also show that the graph embeddings can be applied for tasks such as: clustering, classification and interpretation of relationships between the nodes. Finally, we benchmark the method on a large graph (>1000 nodes), showing that UM-IS outperforms sampling-based methods by a large margin while being computationally efficient.
DeepCoder: Semi-parametric Variational Autoencoders for Automatic Facial Action Coding
Aug 05, 2017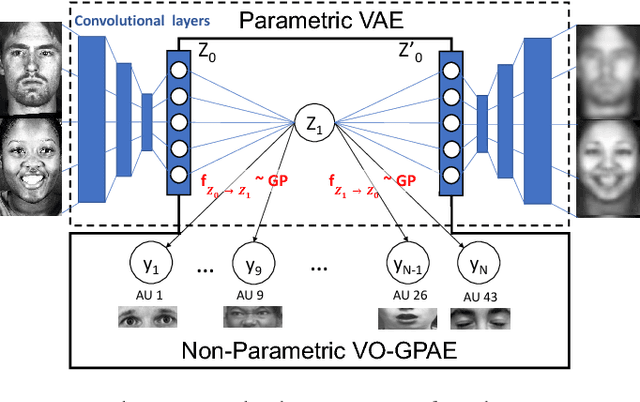
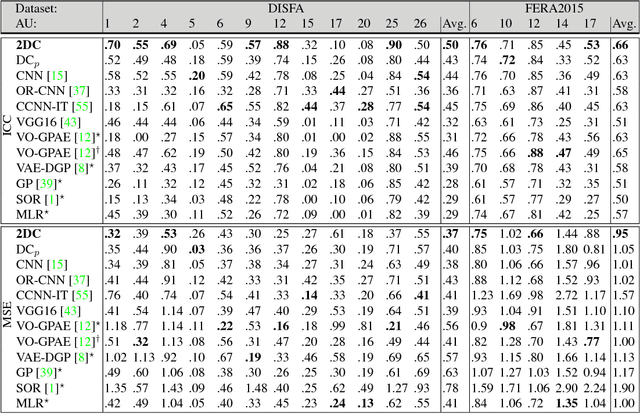
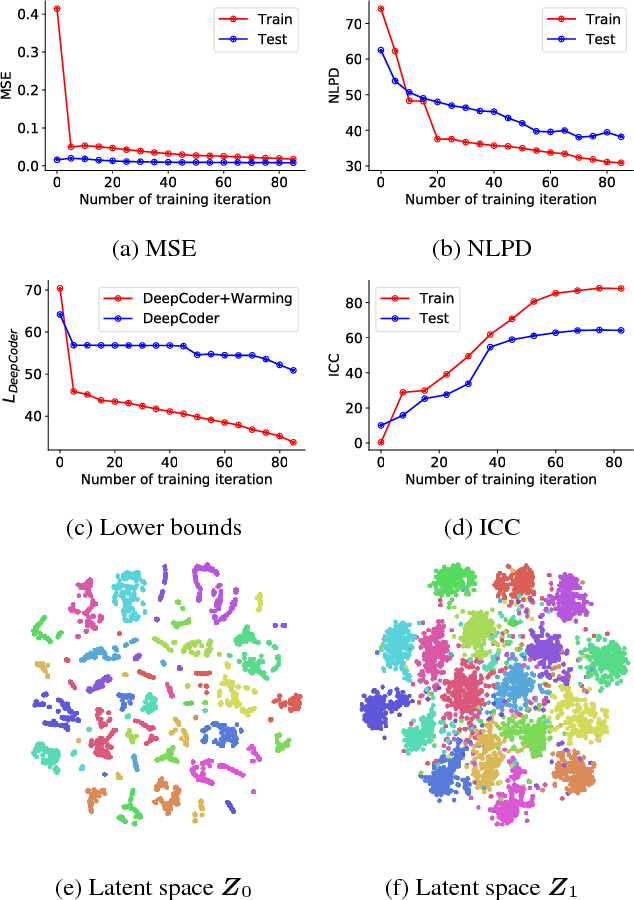
Human face exhibits an inherent hierarchy in its representations (i.e., holistic facial expressions can be encoded via a set of facial action units (AUs) and their intensity). Variational (deep) auto-encoders (VAE) have shown great results in unsupervised extraction of hierarchical latent representations from large amounts of image data, while being robust to noise and other undesired artifacts. Potentially, this makes VAEs a suitable approach for learning facial features for AU intensity estimation. Yet, most existing VAE-based methods apply classifiers learned separately from the encoded features. By contrast, the non-parametric (probabilistic) approaches, such as Gaussian Processes (GPs), typically outperform their parametric counterparts, but cannot deal easily with large amounts of data. To this end, we propose a novel VAE semi-parametric modeling framework, named DeepCoder, which combines the modeling power of parametric (convolutional) and nonparametric (ordinal GPs) VAEs, for joint learning of (1) latent representations at multiple levels in a task hierarchy1, and (2) classification of multiple ordinal outputs. We show on benchmark datasets for AU intensity estimation that the proposed DeepCoder outperforms the state-of-the-art approaches, and related VAEs and deep learning models.
Variable-state Latent Conditional Random Fields for Facial Expression Recognition and Action Unit Detection
Oct 13, 2015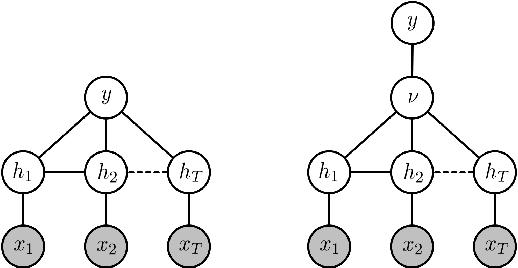

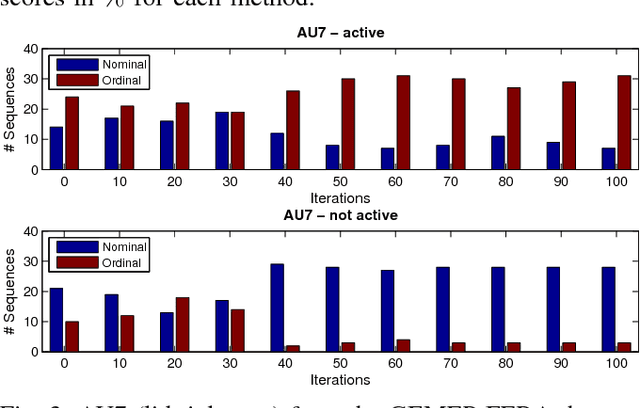
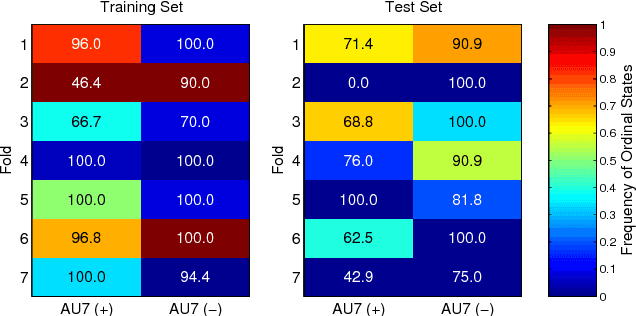
Automated recognition of facial expressions of emotions, and detection of facial action units (AUs), from videos depends critically on modeling of their dynamics. These dynamics are characterized by changes in temporal phases (onset-apex-offset) and intensity of emotion expressions and AUs, the appearance of which may vary considerably among target subjects, making the recognition/detection task very challenging. The state-of-the-art Latent Conditional Random Fields (L-CRF) framework allows one to efficiently encode these dynamics through the latent states accounting for the temporal consistency in emotion expression and ordinal relationships between its intensity levels, these latent states are typically assumed to be either unordered (nominal) or fully ordered (ordinal). Yet, such an approach is often too restrictive. For instance, in the case of AU detection, the goal is to discriminate between the segments of an image sequence in which this AU is active or inactive. While the sequence segments containing activation of the target AU may better be described using ordinal latent states, the inactive segments better be described using unordered (nominal) latent states, as no assumption can be made about their underlying structure (since they can contain either neutral faces or activations of non-target AUs). To address this, we propose the variable-state L-CRF (VSL-CRF) model that automatically selects the optimal latent states for the target image sequence. To reduce the model overfitting either the nominal or ordinal latent states, we propose a novel graph-Laplacian regularization of the latent states. Our experiments on three public expression databases show that the proposed model achieves better generalization performance compared to traditional L-CRFs and other related state-of-the-art models.