 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Many-to-Many Mapping Between Concordance Correlation Coefficient and Mean Square Error
Feb 14, 2019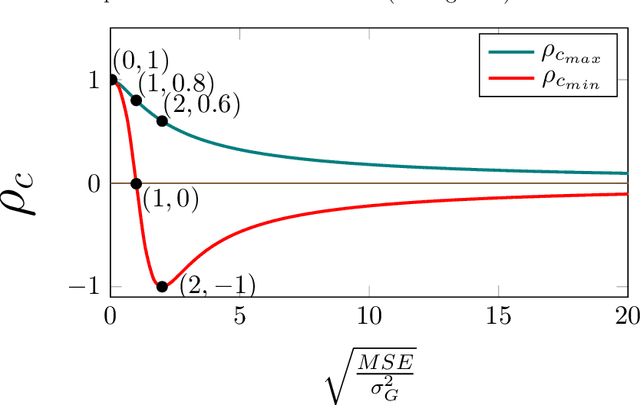
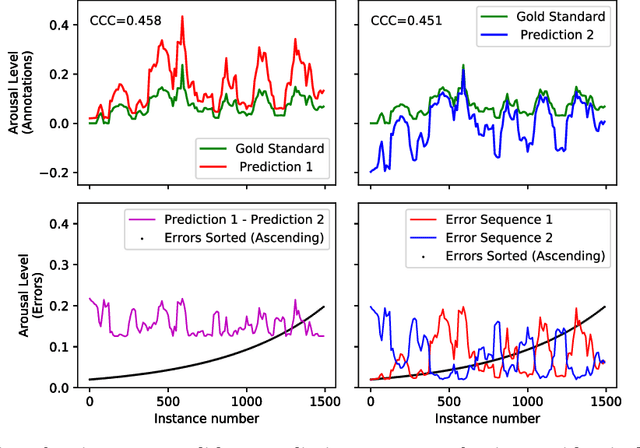
The concordance correlation coefficient (CCC) is one of the most widely used reproducibility indices, introduced by Lin in 1989. In addition to its extensive use in assay validation, CCC serves various different purposes in other multivariate population-related tasks. For example, it is often used as a metric to quantify an inter-rater agreement. It is also often used as a performance metric for prediction problems. In terms of the cost function, however, there has been hardly any attempt to design one to train the predictive deep learning models. In this paper, we present a family of lightweight cost functions that aim to also maximise CCC, when minimising the prediction errors. To this end, we first reformulate CCC in terms of the errors in the prediction; and then as a logical next step, in terms of the sequence of the fixed set of errors. To elucidate our motivation and the results we obtain through these error rearrangements, the data we use is the set of gold standard annotations from a well-known database called `Automatic Sentiment Analysis in the Wild' (SEWA), popular thanks to its use in the latest Audio/Visual Emotion Challenges (\textsc{AVEC'17} and \textsc{AVEC'18}). We also present some new and interesting mathematical paradoxes we have discovered through this CCC reformulation endeavour.
SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Jan 09, 2019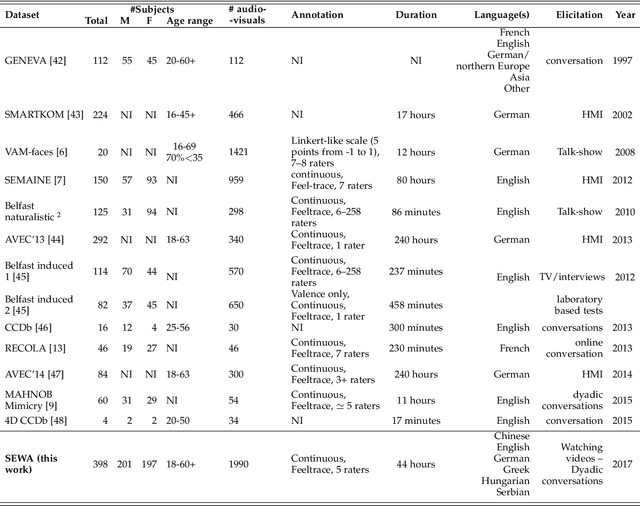
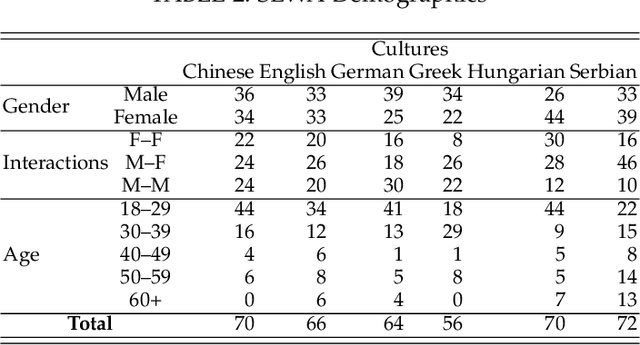

Natural human-computer interaction and audio-visual human behaviour sensing systems, which would achieve robust performance in-the-wild are more needed than ever as digital devices are becoming indispensable part of our life more and more. Accurately annotated real-world data are the crux in devising such systems. However, existing databases usually consider controlled settings, low demographic variability, and a single task. In this paper, we introduce the SEWA database of more than 2000 minutes of audio-visual data of 398 people coming from six cultures, 50% female, and uniformly spanning the age range of 18 to 65 years old. Subjects were recorded in two different contexts: while watching adverts and while discussing adverts in a video chat. The database includes rich annotations of the recordings in terms of facial landmarks, facial action units (FAU), various vocalisations, mirroring, and continuously valued valence, arousal, liking, agreement, and prototypic examples of (dis)liking. This database aims to be an extremely valuable resource for researchers in affective computing and automatic human sensing and is expected to push forward the research in human behaviour analysis, including cultural studies. Along with the database, we provide extensive baseline experiments for automatic FAU detection and automatic valence, arousal and (dis)liking intensity estimation.