 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Many-to-Many Mapping Between Concordance Correlation Coefficient and Mean Square Error
Paper and Code
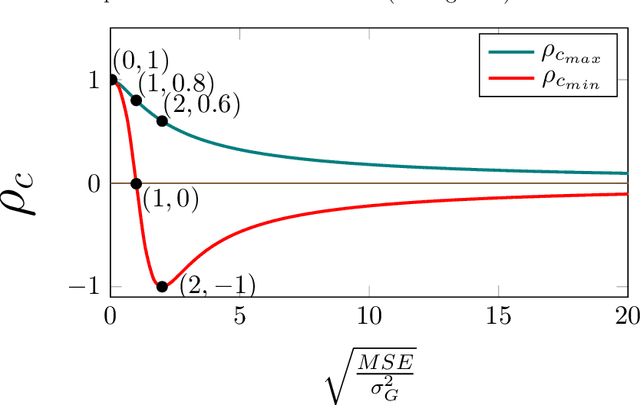
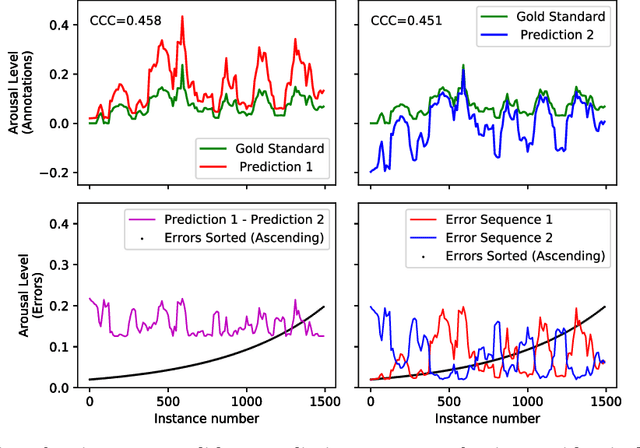
The concordance correlation coefficient (CCC) is one of the most widely used reproducibility indices, introduced by Lin in 1989. In addition to its extensive use in assay validation, CCC serves various different purposes in other multivariate population-related tasks. For example, it is often used as a metric to quantify an inter-rater agreement. It is also often used as a performance metric for prediction problems. In terms of the cost function, however, there has been hardly any attempt to design one to train the predictive deep learning models. In this paper, we present a family of lightweight cost functions that aim to also maximise CCC, when minimising the prediction errors. To this end, we first reformulate CCC in terms of the errors in the prediction; and then as a logical next step, in terms of the sequence of the fixed set of errors. To elucidate our motivation and the results we obtain through these error rearrangements, the data we use is the set of gold standard annotations from a well-known database called `Automatic Sentiment Analysis in the Wild' (SEWA), popular thanks to its use in the latest Audio/Visual Emotion Challenges (\textsc{AVEC'17} and \textsc{AVEC'18}). We also present some new and interesting mathematical paradoxes we have discovered through this CCC reformulation endeavour.