 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgehierarchical network with decoupled knowledge distillation for speech emotion recognition
Mar 09, 2023The goal of Speech Emotion Recognition (SER) is to enable computers to recognize the emotion category of a given utterance in the same way that humans do. The accuracy of SER is strongly dependent on the validity of the utterance-level representation obtained by the model. Nevertheless, the ``dark knowledge" carried by non-target classes is always ignored by previous studies. In this paper, we propose a hierarchical network, called DKDFMH, which employs decoupled knowledge distillation in a deep convolutional neural network with a fused multi-head attention mechanism. Our approach applies logit distillation to obtain higher-level semantic features from different scales of attention sets and delve into the knowledge carried by non-target classes, thus guiding the model to focus more on the differences between sentiment features. To validate the effectiveness of our model, we conducted experiments on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved competitive performance, with 79.1% weighted accuracy (WA) and 77.1% unweighted accuracy (UA). To the best of our knowledge, this is the first time since 2015 that logit distillation has been returned to state-of-the-art status.
Multi-modal Active Learning From Human Data: A Deep Reinforcement Learning Approach
Jun 07, 2019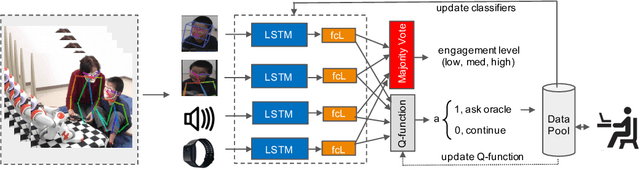


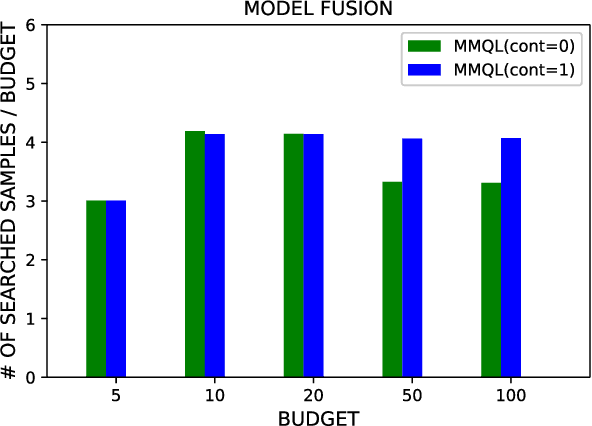
Human behavior expression and experience are inherently multi-modal, and characterized by vast individual and contextual heterogeneity. To achieve meaningful human-computer and human-robot interactions, multi-modal models of the users states (e.g., engagement) are therefore needed. Most of the existing works that try to build classifiers for the users states assume that the data to train the models are fully labeled. Nevertheless, data labeling is costly and tedious, and also prone to subjective interpretations by the human coders. This is even more pronounced when the data are multi-modal (e.g., some users are more expressive with their facial expressions, some with their voice). Thus, building models that can accurately estimate the users states during an interaction is challenging. To tackle this, we propose a novel multi-modal active learning (AL) approach that uses the notion of deep reinforcement learning (RL) to find an optimal policy for active selection of the users data, needed to train the target (modality-specific) models. We investigate different strategies for multi-modal data fusion, and show that the proposed model-level fusion coupled with RL outperforms the feature-level and modality-specific models, and the naive AL strategies such as random sampling, and the standard heuristics such as uncertainty sampling. We show the benefits of this approach on the task of engagement estimation from real-world child-robot interactions during an autism therapy. Importantly, we show that the proposed multi-modal AL approach can be used to efficiently personalize the engagement classifiers to the target user using a small amount of actively selected users data.
SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Jan 09, 2019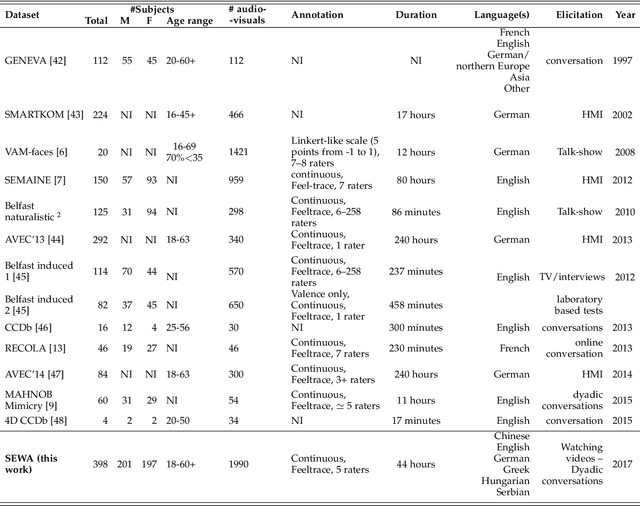
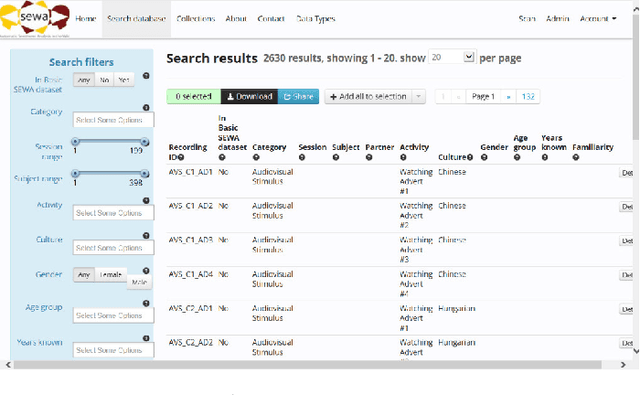
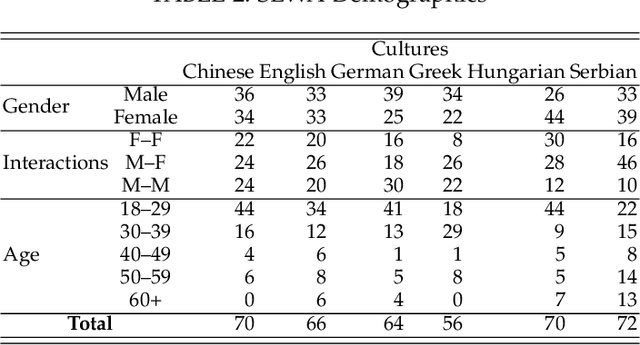

Natural human-computer interaction and audio-visual human behaviour sensing systems, which would achieve robust performance in-the-wild are more needed than ever as digital devices are becoming indispensable part of our life more and more. Accurately annotated real-world data are the crux in devising such systems. However, existing databases usually consider controlled settings, low demographic variability, and a single task. In this paper, we introduce the SEWA database of more than 2000 minutes of audio-visual data of 398 people coming from six cultures, 50% female, and uniformly spanning the age range of 18 to 65 years old. Subjects were recorded in two different contexts: while watching adverts and while discussing adverts in a video chat. The database includes rich annotations of the recordings in terms of facial landmarks, facial action units (FAU), various vocalisations, mirroring, and continuously valued valence, arousal, liking, agreement, and prototypic examples of (dis)liking. This database aims to be an extremely valuable resource for researchers in affective computing and automatic human sensing and is expected to push forward the research in human behaviour analysis, including cultural studies. Along with the database, we provide extensive baseline experiments for automatic FAU detection and automatic valence, arousal and (dis)liking intensity estimation.
Personalized Machine Learning for Robot Perception of Affect and Engagement in Autism Therapy
Jun 19, 2018Robots have great potential to facilitate future therapies for children on the autism spectrum. However, existing robots lack the ability to automatically perceive and respond to human affect, which is necessary for establishing and maintaining engaging interactions. Moreover, their inference challenge is made harder by the fact that many individuals with autism have atypical and unusually diverse styles of expressing their affective-cognitive states. To tackle the heterogeneity in behavioral cues of children with autism, we use the latest advances in deep learning to formulate a personalized machine learning (ML) framework for automatic perception of the childrens affective states and engagement during robot-assisted autism therapy. The key to our approach is a novel shift from the traditional ML paradigm - instead of using 'one-size-fits-all' ML models, our personalized ML framework is optimized for each child by leveraging relevant contextual information (demographics and behavioral assessment scores) and individual characteristics of each child. We designed and evaluated this framework using a dataset of multi-modal audio, video and autonomic physiology data of 35 children with autism (age 3-13) and from 2 cultures (Asia and Europe), participating in a 25-minute child-robot interaction (~500k datapoints). Our experiments confirm the feasibility of the robot perception of affect and engagement, showing clear improvements due to the model personalization. The proposed approach has potential to improve existing therapies for autism by offering more efficient monitoring and summarization of the therapy progress.
AVEC 2016 - Depression, Mood, and Emotion Recognition Workshop and Challenge
Nov 22, 2016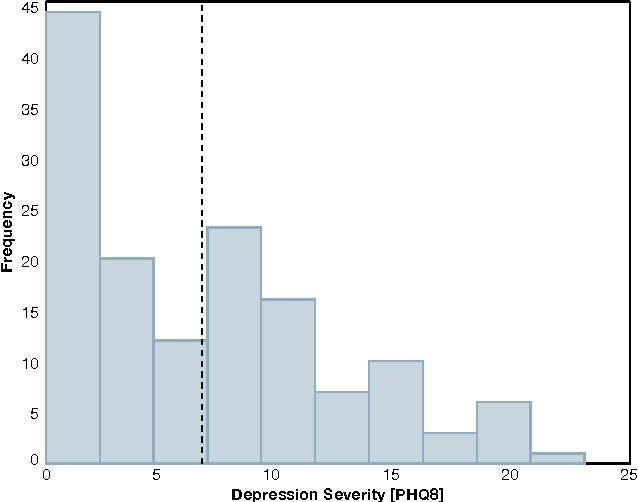
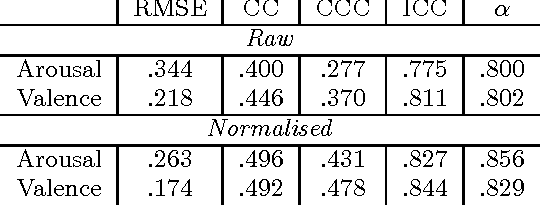
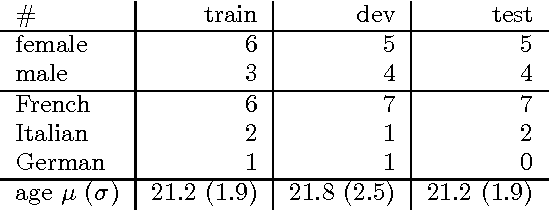
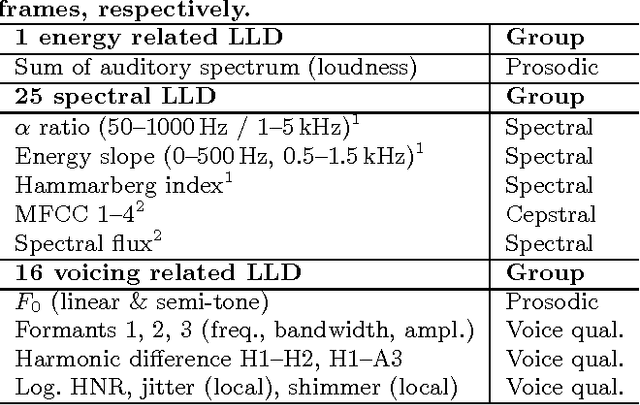
The Audio/Visual Emotion Challenge and Workshop (AVEC 2016) "Depression, Mood and Emotion" will be the sixth competition event aimed at comparison of multimedia processing and machine learning methods for automatic audio, visual and physiological depression and emotion analysis, with all participants competing under strictly the same conditions. The goal of the Challenge is to provide a common benchmark test set for multi-modal information processing and to bring together the depression and emotion recognition communities, as well as the audio, video and physiological processing communities, to compare the relative merits of the various approaches to depression and emotion recognition under well-defined and strictly comparable conditions and establish to what extent fusion of the approaches is possible and beneficial. This paper presents the challenge guidelines, the common data used, and the performance of the baseline system on the two tasks.