 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
Jan 27, 2026Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in vision-language representation learning, powering diverse downstream tasks and serving as the default vision backbone in multimodal large language models (MLLMs). Despite its success, CLIP's dense and opaque latent representations pose significant interpretability challenges. A common assumption is that interpretability and performance are in tension: enforcing sparsity during training degrades accuracy, motivating recent post-hoc approaches such as Sparse Autoencoders (SAEs). However, these post-hoc approaches often suffer from degraded downstream performance and loss of CLIP's inherent multimodal capabilities, with most learned features remaining unimodal. We propose a simple yet effective approach that integrates sparsity directly into CLIP training, yielding representations that are both interpretable and performant. Compared to SAEs, our Sparse CLIP representations preserve strong downstream task performance, achieve superior interpretability, and retain multimodal capabilities. We show that multimodal sparse features enable straightforward semantic concept alignment and reveal training dynamics of how cross-modal knowledge emerges. Finally, as a proof of concept, we train a vision-language model on sparse CLIP representations that enables interpretable, vision-based steering capabilities. Our findings challenge conventional wisdom that interpretability requires sacrificing accuracy and demonstrate that interpretability and performance can be co-optimized, offering a promising design principle for future models.
Accelerating Look-ahead in Bayesian Optimization: Multilevel Monte Carlo is All you Need
Feb 03, 2024We leverage multilevel Monte Carlo (MLMC) to improve the performance of multi-step look-ahead Bayesian optimization (BO) methods that involve nested expectations and maximizations. The complexity rate of naive Monte Carlo degrades for nested operations, whereas MLMC is capable of achieving the canonical Monte Carlo convergence rate for this type of problem, independently of dimension and without any smoothness assumptions. Our theoretical study focuses on the approximation improvements for one- and two-step look-ahead acquisition functions, but, as we discuss, the approach is generalizable in various ways, including beyond the context of BO. Findings are verified numerically and the benefits of MLMC for BO are illustrated on several benchmark examples. Code is available here https://github.com/Shangda-Yang/MLMCBO.
Improving Selective Visual Question Answering by Learning from Your Peers
Jun 14, 2023



Despite advances in Visual Question Answering (VQA), the ability of models to assess their own correctness remains underexplored. Recent work has shown that VQA models, out-of-the-box, can have difficulties abstaining from answering when they are wrong. The option to abstain, also called Selective Prediction, is highly relevant when deploying systems to users who must trust the system's output (e.g., VQA assistants for users with visual impairments). For such scenarios, abstention can be especially important as users may provide out-of-distribution (OOD) or adversarial inputs that make incorrect answers more likely. In this work, we explore Selective VQA in both in-distribution (ID) and OOD scenarios, where models are presented with mixtures of ID and OOD data. The goal is to maximize the number of questions answered while minimizing the risk of error on those questions. We propose a simple yet effective Learning from Your Peers (LYP) approach for training multimodal selection functions for making abstention decisions. Our approach uses predictions from models trained on distinct subsets of the training data as targets for optimizing a Selective VQA model. It does not require additional manual labels or held-out data and provides a signal for identifying examples that are easy/difficult to generalize to. In our extensive evaluations, we show this benefits a number of models across different architectures and scales. Overall, for ID, we reach 32.92% in the selective prediction metric coverage at 1% risk of error (C@1%) which doubles the previous best coverage of 15.79% on this task. For mixed ID/OOD, using models' softmax confidences for abstention decisions performs very poorly, answering <5% of questions at 1% risk of error even when faced with only 10% OOD examples, but a learned selection function with LYP can increase that to 25.38% C@1%.
Social and Emotional Skills Training with Embodied Moxie
Apr 27, 2020
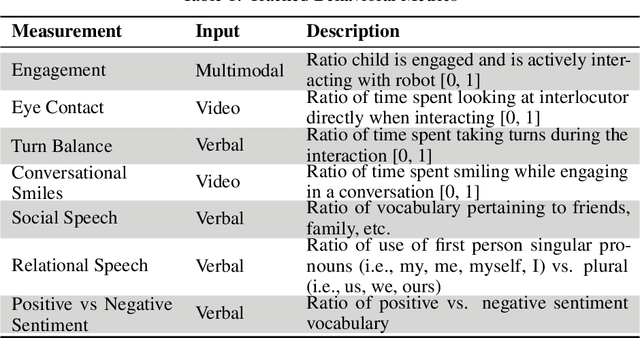
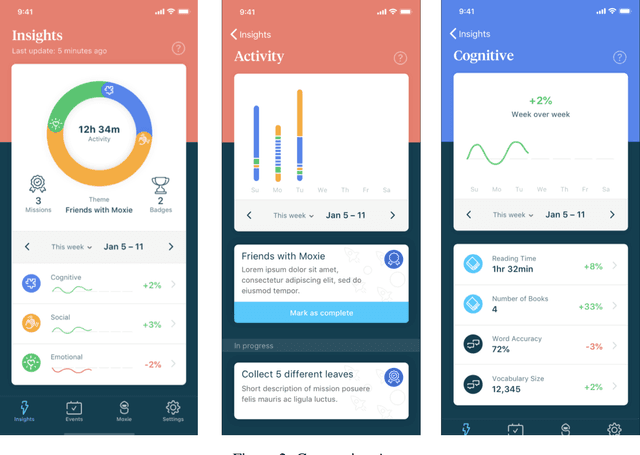
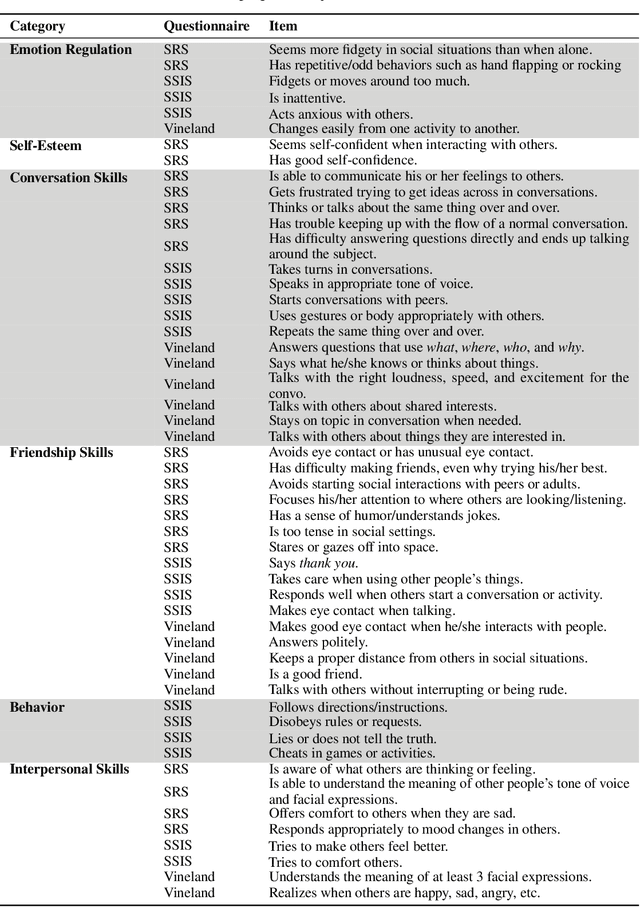
We present a therapeutic framework, namely STAR Framework, that leverages established and evidence-based therapeutic strategies delivered by the Embodied Moxie, an animate companion to support children with mental behavioral developmental disorders (MBDDs). This therapeutic framework jointly with Moxie aims to provide an engaging, safe, and secure environment for children aged five to ten years old. Moxie delivers content informed by therapeutic strategies including but not limited to naturalistic Applied Behavior Analysis, graded cueing, and Cognitive Behavior Therapy. Leveraging multimodal input from a camera and microphones, Moxie is uniquely positioned to be a first-hand witness of a child's progress and struggles alike. Moxie measures skills captured in state-of-the-art assessment scales, such as the Social Responsiveness Scale and Social Skill Improvement Scale, and augments those measures with quantitatively measured behavior skills, such as eye contact and language skills. While preliminary, the present study (N=12) also provides evidence that a six-week intervention using the STAR Framework and Moxie had significant impact on the children's abilities. We present our research in detail and provide an overview of the STAR Framework and all related components, such as Moxie and the companion app for parents.
Affect-LM: A Neural Language Model for Customizable Affective Text Generation
Apr 22, 2017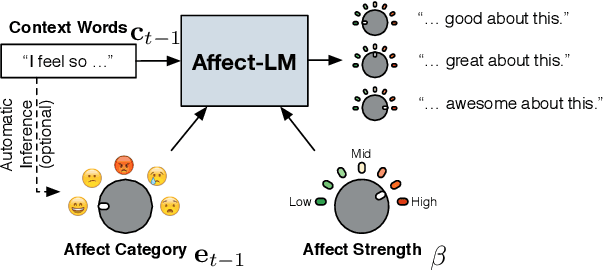
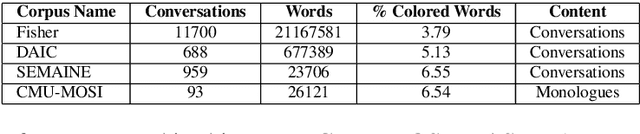

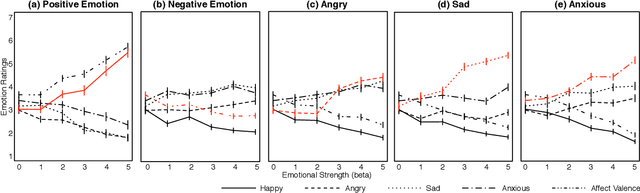
Human verbal communication includes affective messages which are conveyed through use of emotionally colored words. There has been a lot of research in this direction but the problem of integrating state-of-the-art neural language models with affective information remains an area ripe for exploration. In this paper, we propose an extension to an LSTM (Long Short-Term Memory) language model for generating conversational text, conditioned on affect categories. Our proposed model, Affect-LM enables us to customize the degree of emotional content in generated sentences through an additional design parameter. Perception studies conducted using Amazon Mechanical Turk show that Affect-LM generates naturally looking emotional sentences without sacrificing grammatical correctness. Affect-LM also learns affect-discriminative word representations, and perplexity experiments show that additional affective information in conversational text can improve language model prediction.
Learning Representations of Emotional Speech with Deep Convolutional Generative Adversarial Networks
Apr 22, 2017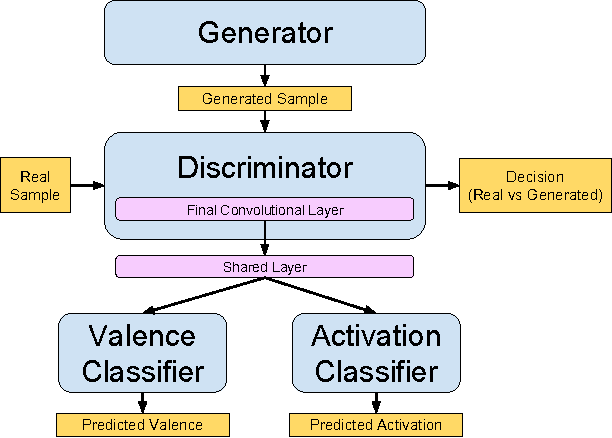
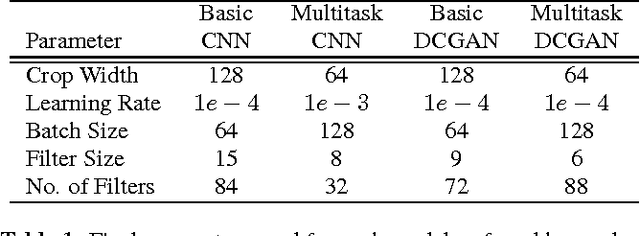
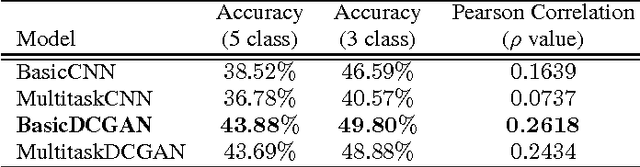
Automatically assessing emotional valence in human speech has historically been a difficult task for machine learning algorithms. The subtle changes in the voice of the speaker that are indicative of positive or negative emotional states are often "overshadowed" by voice characteristics relating to emotional intensity or emotional activation. In this work we explore a representation learning approach that automatically derives discriminative representations of emotional speech. In particular, we investigate two machine learning strategies to improve classifier performance: (1) utilization of unlabeled data using a deep convolutional generative adversarial network (DCGAN), and (2) multitask learning. Within our extensive experiments we leverage a multitask annotated emotional corpus as well as a large unlabeled meeting corpus (around 100 hours). Our speaker-independent classification experiments show that in particular the use of unlabeled data in our investigations improves performance of the classifiers and both fully supervised baseline approaches are outperformed considerably. We improve the classification of emotional valence on a discrete 5-point scale to 43.88% and on a 3-point scale to 49.80%, which is competitive to state-of-the-art performance.
AVEC 2016 - Depression, Mood, and Emotion Recognition Workshop and Challenge
Nov 22, 2016
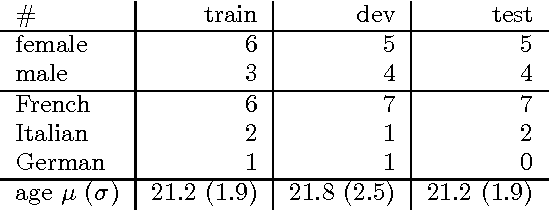
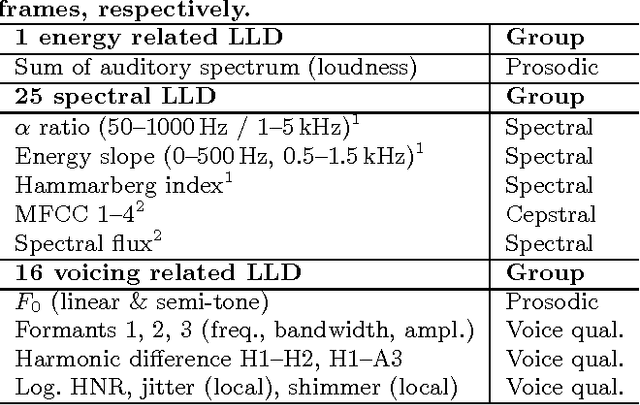
The Audio/Visual Emotion Challenge and Workshop (AVEC 2016) "Depression, Mood and Emotion" will be the sixth competition event aimed at comparison of multimedia processing and machine learning methods for automatic audio, visual and physiological depression and emotion analysis, with all participants competing under strictly the same conditions. The goal of the Challenge is to provide a common benchmark test set for multi-modal information processing and to bring together the depression and emotion recognition communities, as well as the audio, video and physiological processing communities, to compare the relative merits of the various approaches to depression and emotion recognition under well-defined and strictly comparable conditions and establish to what extent fusion of the approaches is possible and beneficial. This paper presents the challenge guidelines, the common data used, and the performance of the baseline system on the two tasks.
Learning Representations of Affect from Speech
Feb 14, 2016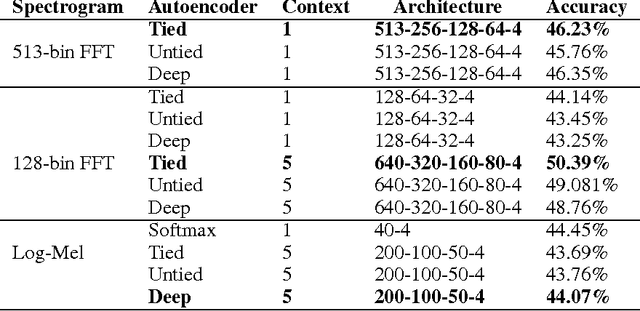

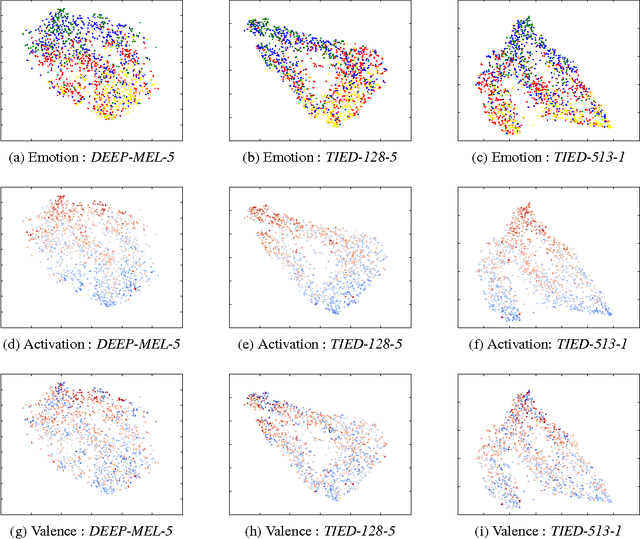
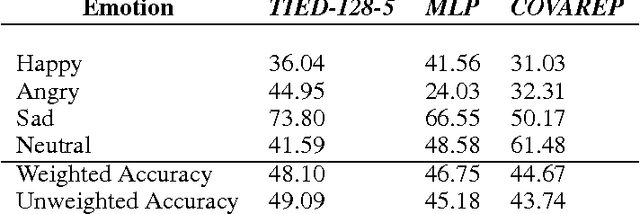
There has been a lot of prior work on representation learning for speech recognition applications, but not much emphasis has been given to an investigation of effective representations of affect from speech, where the paralinguistic elements of speech are separated out from the verbal content. In this paper, we explore denoising autoencoders for learning paralinguistic attributes i.e. categorical and dimensional affective traits from speech. We show that the representations learnt by the bottleneck layer of the autoencoder are highly discriminative of activation intensity and at separating out negative valence (sadness and anger) from positive valence (happiness). We experiment with different input speech features (such as FFT and log-mel spectrograms with temporal context windows), and different autoencoder architectures (such as stacked and deep autoencoders). We also learn utterance specific representations by a combination of denoising autoencoders and BLSTM based recurrent autoencoders. Emotion classification is performed with the learnt temporal/dynamic representations to evaluate the quality of the representations. Experiments on a well-established real-life speech dataset (IEMOCAP) show that the learnt representations are comparable to state of the art feature extractors (such as voice quality features and MFCCs) and are competitive with state-of-the-art approaches at emotion and dimensional affect recognition.