 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Truly Embody Human Personality? Analyzing AI and Human Behavior Alignment in Dispute Resolution
Feb 07, 2026Large language models (LLMs) are increasingly used to simulate human behavior in social settings such as legal mediation, negotiation, and dispute resolution. However, it remains unclear whether these simulations reproduce the personality-behavior patterns observed in humans. Human personality, for instance, shapes how individuals navigate social interactions, including strategic choices and behaviors in emotionally charged interactions. This raises the question: Can LLMs, when prompted with personality traits, reproduce personality-driven differences in human conflict behavior? To explore this, we introduce an evaluation framework that enables direct comparison of human-human and LLM-LLM behaviors in dispute resolution dialogues with respect to Big Five Inventory (BFI) personality traits. This framework provides a set of interpretable metrics related to strategic behavior and conflict outcomes. We additionally contribute a novel dataset creation methodology for LLM dispute resolution dialogues with matched scenarios and personality traits with respect to human conversations. Finally, we demonstrate the use of our evaluation framework with three contemporary closed-source LLMs and show significant divergences in how personality manifests in conflict across different LLMs compared to human data, challenging the assumption that personality-prompted agents can serve as reliable behavioral proxies in socially impactful applications. Our work highlights the need for psychological grounding and validation in AI simulations before real-world use.
Personality Expression Across Contexts: Linguistic and Behavioral Variation in LLM Agents
Feb 01, 2026Large Language Models (LLMs) can be conditioned with explicit personality prompts, yet their behavioral realization often varies depending on context. This study examines how identical personality prompts lead to distinct linguistic, behavioral, and emotional outcomes across four conversational settings: ice-breaking, negotiation, group decision, and empathy tasks. Results show that contextual cues systematically influence both personality expression and emotional tone, suggesting that the same traits are expressed differently depending on social and affective demands. This raises an important question for LLM-based dialogue agents: whether such variations reflect inconsistency or context-sensitive adaptation akin to human behavior. Viewed through the lens of Whole Trait Theory, these findings highlight that LLMs exhibit context-sensitive rather than fixed personality expression, adapting flexibly to social interaction goals and affective conditions.
Sparks of Rationality: Do Reasoning LLMs Align with Human Judgment and Choice?
Jan 29, 2026Large Language Models (LLMs) are increasingly positioned as decision engines for hiring, healthcare, and economic judgment, yet real-world human judgment reflects a balance between rational deliberation and emotion-driven bias. If LLMs are to participate in high-stakes decisions or serve as models of human behavior, it is critical to assess whether they exhibit analogous patterns of (ir)rationalities and biases. To this end, we evaluate multiple LLM families on (i) benchmarks testing core axioms of rational choice and (ii) classic decision domains from behavioral economics and social norms where emotions are known to shape judgment and choice. Across settings, we show that deliberate "thinking" reliably improves rationality and pushes models toward expected-value maximization. To probe human-like affective distortions and their interaction with reasoning, we use two emotion-steering methods: in-context priming (ICP) and representation-level steering (RLS). ICP induces strong directional shifts that are often extreme and difficult to calibrate, whereas RLS produces more psychologically plausible patterns but with lower reliability. Our results suggest that the same mechanisms that improve rationality also amplify sensitivity to affective interventions, and that different steering methods trade off controllability against human-aligned behavior. Overall, this points to a tension between reasoning and affective steering, with implications for both human simulation and the safe deployment of LLM-based decision systems.
Psychological Steering in LLMs: An Evaluation of Effectiveness and Trustworthiness
Oct 06, 2025The ability to control LLMs' emulated emotional states and personality traits is essential for enabling rich, human-centered interactions in socially interactive settings. We introduce PsySET, a Psychologically-informed benchmark to evaluate LLM Steering Effectiveness and Trustworthiness across the emotion and personality domains. Our study spans four models from different LLM families paired with various steering strategies, including prompting, fine-tuning, and representation engineering. Our results indicate that prompting is consistently effective but limited in intensity control, whereas vector injections achieve finer controllability while slightly reducing output quality. Moreover, we explore the trustworthiness of steered LLMs by assessing safety, truthfulness, fairness, and ethics, highlighting potential side effects and behavioral shifts. Notably, we observe idiosyncratic effects; for instance, even a positive emotion like joy can degrade robustness to adversarial factuality, lower privacy awareness, and increase preferential bias. Meanwhile, anger predictably elevates toxicity yet strengthens leakage resistance. Our framework establishes the first holistic evaluation of emotion and personality steering, offering insights into its interpretability and reliability for socially interactive applications.
KODIS: A Multicultural Dispute Resolution Dialogue Corpus
Apr 17, 2025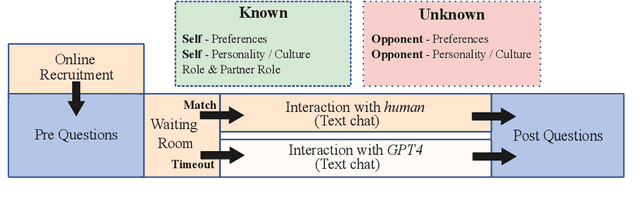
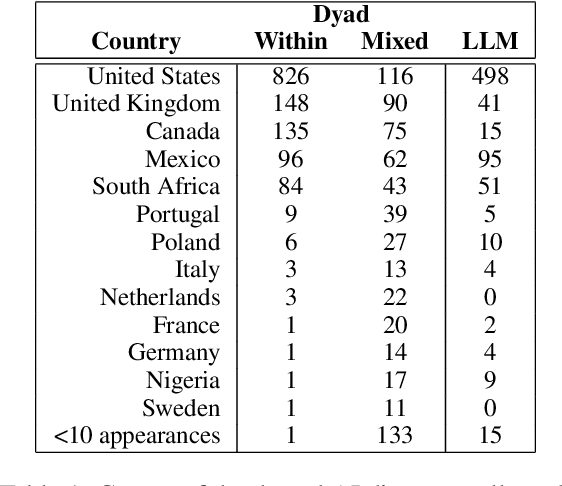

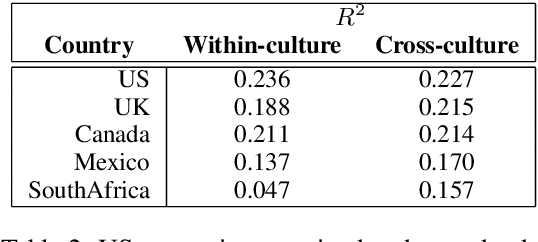
We present KODIS, a dyadic dispute resolution corpus containing thousands of dialogues from over 75 countries. Motivated by a theoretical model of culture and conflict, participants engage in a typical customer service dispute designed by experts to evoke strong emotions and conflict. The corpus contains a rich set of dispositional, process, and outcome measures. The initial analysis supports theories of how anger expressions lead to escalatory spirals and highlights cultural differences in emotional expression. We make this corpus and data collection framework available to the community.
ASTRA: A Negotiation Agent with Adaptive and Strategic Reasoning through Action in Dynamic Offer Optimization
Mar 10, 2025



Negotiation requires dynamically balancing self-interest and cooperation to maximize one's own utility. Yet, existing agents struggle due to bounded rationality in human data, low adaptability to counterpart behavior, and limited strategic reasoning. To address this, we introduce principle-driven negotiation agents, powered by ASTRA, a novel framework for turn-level offer optimization grounded in two core principles: opponent modeling and Tit-for-Tat reciprocity. ASTRA operates in three stages: (1) interpreting counterpart behavior, (2) optimizing counteroffers via a linear programming (LP) solver, and (3) selecting offers based on negotiation tactics and the partner's acceptance probability. Through simulations and human evaluations, our agent effectively adapts to an opponent's shifting stance and achieves favorable outcomes through enhanced adaptability and strategic reasoning. Beyond improving negotiation performance, it also serves as a powerful coaching tool, offering interpretable strategic feedback and optimal offer recommendations.
Exploring Emotion-Sensitive LLM-Based Conversational AI
Feb 13, 2025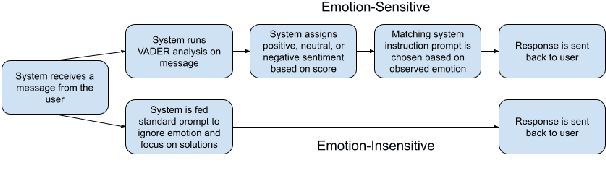
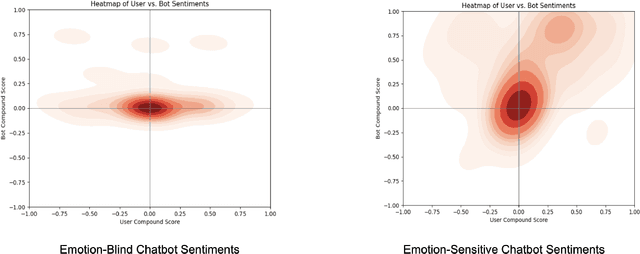
Conversational AI chatbots have become increasingly common within the customer service industry. Despite improvements in their emotional development, they often lack the authenticity of real customer service interactions or the competence of service providers. By comparing emotion-sensitive and emotion-insensitive LLM-based chatbots across 30 participants, we aim to explore how emotional sensitivity in chatbots influences perceived competence and overall customer satisfaction in service interactions. Additionally, we employ sentiment analysis techniques to analyze and interpret the emotional content of user inputs. We highlight that perceptions of chatbot trustworthiness and competence were higher in the case of the emotion-sensitive chatbot, even if issue resolution rates were not affected. We discuss implications of improved user satisfaction from emotion-sensitive chatbots and potential applications in support services.
Mechanistic Interpretability of Emotion Inference in Large Language Models
Feb 08, 2025Large language models (LLMs) show promising capabilities in predicting human emotions from text. However, the mechanisms through which these models process emotional stimuli remain largely unexplored. Our study addresses this gap by investigating how autoregressive LLMs infer emotions, showing that emotion representations are functionally localized to specific regions in the model. Our evaluation includes diverse model families and sizes and is supported by robustness checks. We then show that the identified representations are psychologically plausible by drawing on cognitive appraisal theory, a well-established psychological framework positing that emotions emerge from evaluations (appraisals) of environmental stimuli. By causally intervening on construed appraisal concepts, we steer the generation and show that the outputs align with theoretical and intuitive expectations. This work highlights a novel way to causally intervene and precisely shape emotional text generation, potentially benefiting safety and alignment in sensitive affective domains.
Are LLMs Effective Negotiators? Systematic Evaluation of the Multifaceted Capabilities of LLMs in Negotiation Dialogues
Feb 21, 2024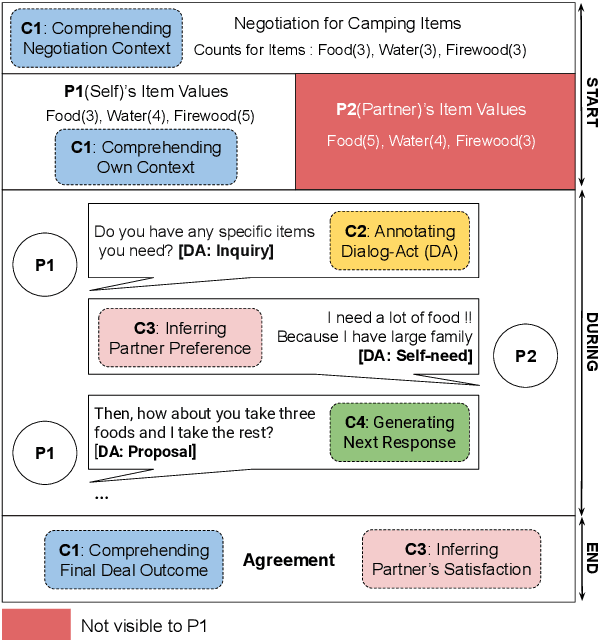

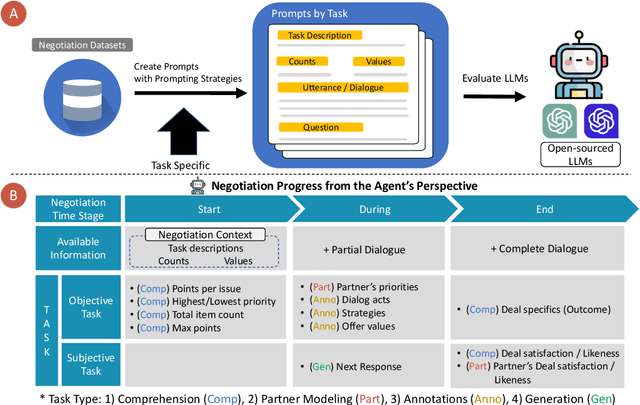
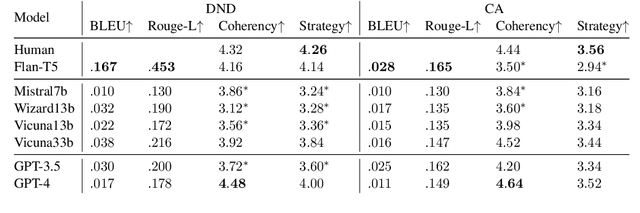
A successful negotiation demands a deep comprehension of the conversation context, Theory-of-Mind (ToM) skills to infer the partner's motives, as well as strategic reasoning and effective communication, making it challenging for automated systems. Given the remarkable performance of LLMs across a variety of NLP tasks, in this work, we aim to understand how LLMs can advance different aspects of negotiation research, ranging from designing dialogue systems to providing pedagogical feedback and scaling up data collection practices. To this end, we devise a methodology to analyze the multifaceted capabilities of LLMs across diverse dialogue scenarios covering all the time stages of a typical negotiation interaction. Our analysis adds to the increasing evidence for the superiority of GPT-4 across various tasks while also providing insights into specific tasks that remain difficult for LLMs. For instance, the models correlate poorly with human players when making subjective assessments about the negotiation dialogues and often struggle to generate responses that are contextually appropriate as well as strategically advantageous.
Can Language Model Moderators Improve the Health of Online Discourse?
Nov 16, 2023



Human moderation of online conversation is essential to maintaining civility and focus in a dialogue, but is challenging to scale and harmful to moderators. The inclusion of sophisticated natural language generation modules as a force multiplier aid moderators is a tantalizing prospect, but adequate evaluation approaches have so far been elusive. In this paper, we establish a systematic definition of conversational moderation effectiveness through a multidisciplinary lens that incorporates insights from social science. We then propose a comprehensive evaluation framework that uses this definition to asses models' moderation capabilities independently of human intervention. With our framework, we conduct the first known study of conversational dialogue models as moderators, finding that appropriately prompted models can provide specific and fair feedback on toxic behavior but struggle to influence users to increase their levels of respect and cooperation.