 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023



The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.
Predicting MOOCs Dropout Using Only Two Easily Obtainable Features from the First Week's Activities
Aug 12, 2020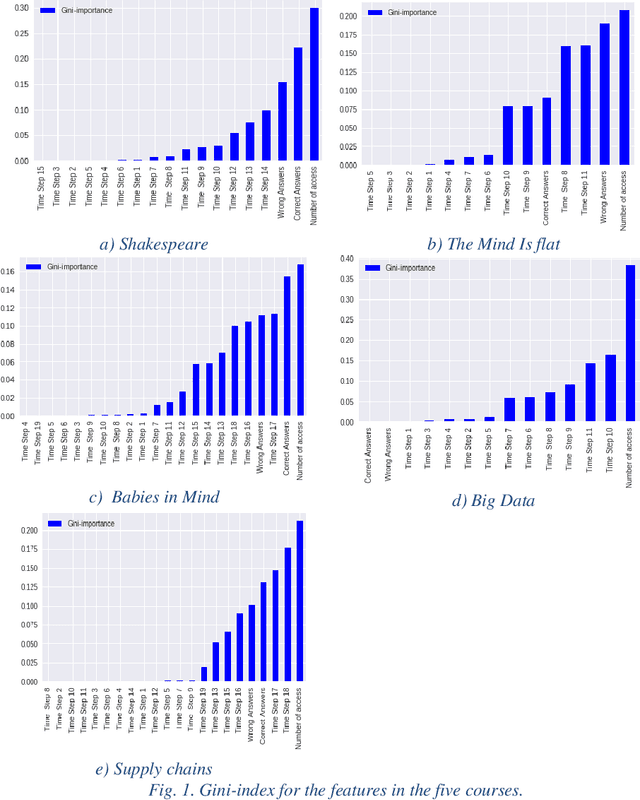
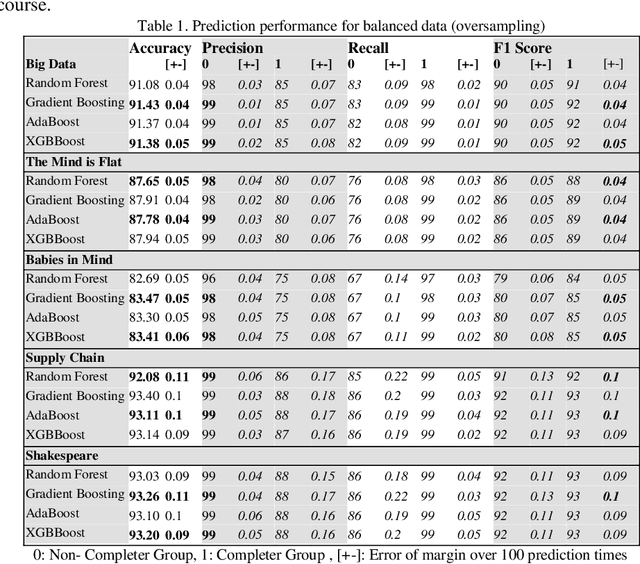
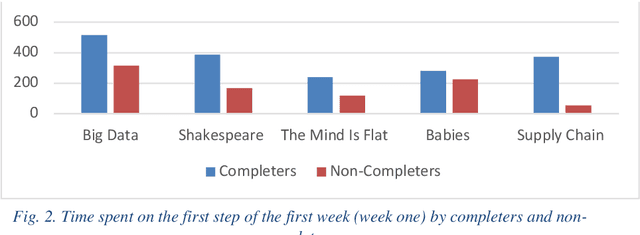
While Massive Open Online Course (MOOCs) platforms provide knowledge in a new and unique way, the very high number of dropouts is a significant drawback. Several features are considered to contribute towards learner attrition or lack of interest, which may lead to disengagement or total dropout. The jury is still out on which factors are the most appropriate predictors. However, the literature agrees that early prediction is vital to allow for a timely intervention. Whilst feature-rich predictors may have the best chance for high accuracy, they may be unwieldy. This study aims to predict learner dropout early-on, from the first week, by comparing several machine-learning approaches, including Random Forest, Adaptive Boost, XGBoost and GradientBoost Classifiers. The results show promising accuracies (82%-94%) using as little as 2 features. We show that the accuracies obtained outperform state of the art approaches, even when the latter deploy several features.