 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Latent Variable Models for Semi-supervised Paraphrase Generation
Jan 05, 2023



This paper explores deep latent variable models for semi-supervised paraphrase generation, where the missing target pair is modelled as a latent paraphrase sequence. We present a novel unsupervised model named variational sequence auto-encoding reconstruction (VSAR), which performs latent sequence inference given an observed text. To leverage information from text pairs, we introduce a supervised model named dual directional learning (DDL). Combining VSAR with DDL (DDL+VSAR) enables us to conduct semi-supervised learning; however, the combined model suffers from a cold-start problem. To combat this issue, we propose to deal with better weight initialisation, leading to a two-stage training scheme named knowledge reinforced training. Our empirical evaluations suggest that the combined model yields competitive performance against the state-of-the-art supervised baselines on complete data. Furthermore, in scenarios where only a fraction of the labelled pairs are available, our combined model consistently outperforms the strong supervised model baseline (DDL and Transformer) by a significant margin.
Religion and Spirituality on Social Media in the Aftermath of the Global Pandemic
Dec 11, 2022
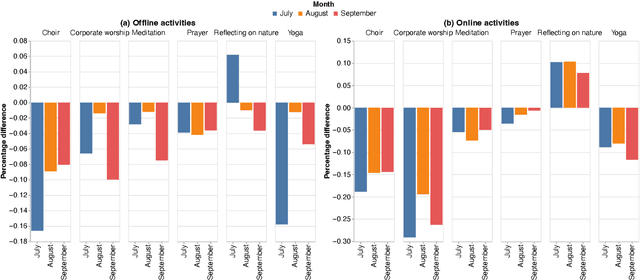
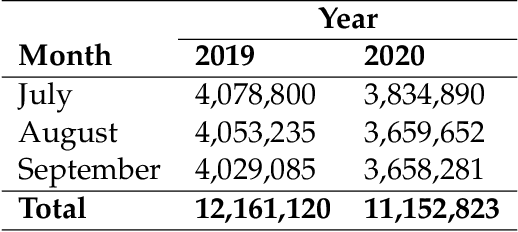
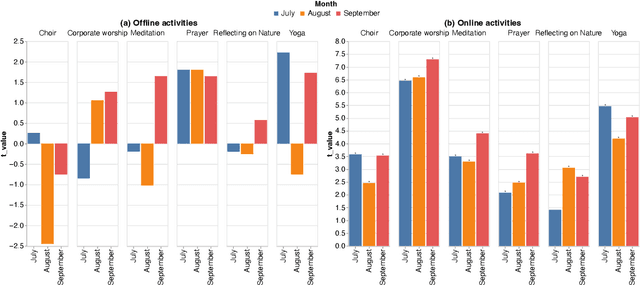
During the COVID-19 pandemic, the Church closed its physical doors for the first time in about 800 years, which is, arguably, a cataclysmic event. Other religions have found themselves in a similar situation, and they were practically forced to move online, which is an unprecedented occasion. In this paper, we analyse this sudden change in religious activities twofold: we create and deliver a questionnaire, as well as analyse Twitter data, to understand people's perceptions and activities related to religious activities online. Importantly, we also analyse the temporal variations in this process by analysing a period of 3 months: July-September 2020. Additionally to the separate analysis of the two data sources, we also discuss the implications from triangulating the results.
Incorporating Emotions into Health Mention Classification Task on Social Media
Dec 09, 2022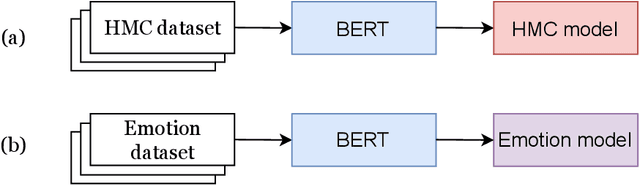



The health mention classification (HMC) task is the process of identifying and classifying mentions of health-related concepts in text. This can be useful for identifying and tracking the spread of diseases through social media posts. However, this is a non-trivial task. Here we build on recent studies suggesting that using emotional information may improve upon this task. Our study results in a framework for health mention classification that incorporates affective features. We present two methods, an intermediate task fine-tuning approach (implicit) and a multi-feature fusion approach (explicit) to incorporate emotions into our target task of HMC. We evaluated our approach on 5 HMC-related datasets from different social media platforms including three from Twitter, one from Reddit and another from a combination of social media sources. Extensive experiments demonstrate that our approach results in statistically significant performance gains on HMC tasks. By using the multi-feature fusion approach, we achieve at least a 3% improvement in F1 score over BERT baselines across all datasets. We also show that considering only negative emotions does not significantly affect performance on the HMC task. Additionally, our results indicate that HMC models infused with emotional knowledge are an effective alternative, especially when other HMC datasets are unavailable for domain-specific fine-tuning. The source code for our models is freely available at https://github.com/tahirlanre/Emotion_PHM.
Multi-task Learning for Personal Health Mention Detection on Social Media
Dec 09, 2022


Detecting personal health mentions on social media is essential to complement existing health surveillance systems. However, annotating data for detecting health mentions at a large scale is a challenging task. This research employs a multitask learning framework to leverage available annotated data from a related task to improve the performance on the main task to detect personal health experiences mentioned in social media texts. Specifically, we focus on incorporating emotional information into our target task by using emotion detection as an auxiliary task. Our approach significantly improves a wide range of personal health mention detection tasks compared to a strong state-of-the-art baseline.
INTERACTION: A Generative XAI Framework for Natural Language Inference Explanations
Sep 02, 2022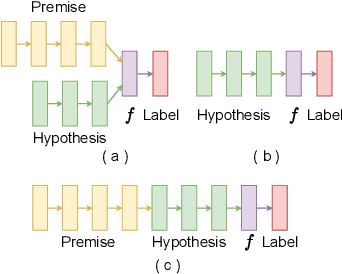
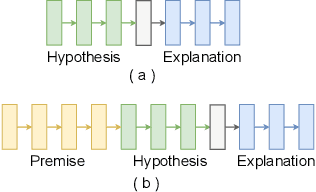
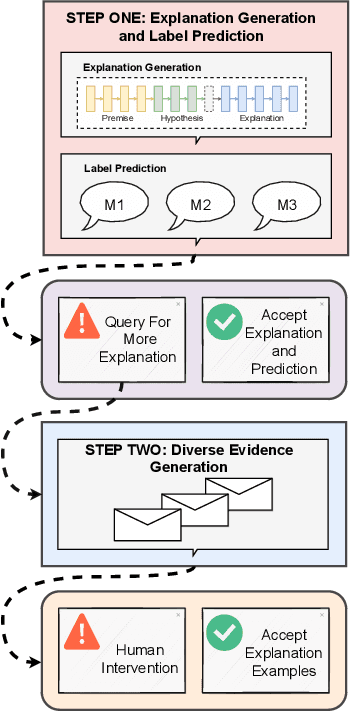

XAI with natural language processing aims to produce human-readable explanations as evidence for AI decision-making, which addresses explainability and transparency. However, from an HCI perspective, the current approaches only focus on delivering a single explanation, which fails to account for the diversity of human thoughts and experiences in language. This paper thus addresses this gap, by proposing a generative XAI framework, INTERACTION (explaIn aNd predicT thEn queRy with contextuAl CondiTional varIational autO-eNcoder). Our novel framework presents explanation in two steps: (step one) Explanation and Label Prediction; and (step two) Diverse Evidence Generation. We conduct intensive experiments with the Transformer architecture on a benchmark dataset, e-SNLI. Our method achieves competitive or better performance against state-of-the-art baseline models on explanation generation (up to 4.7% gain in BLEU) and prediction (up to 4.4% gain in accuracy) in step one; it can also generate multiple diverse explanations in step two.
Exploring Bayesian Deep Learning for Urgent Instructor Intervention Need in MOOC Forums
Apr 26, 2021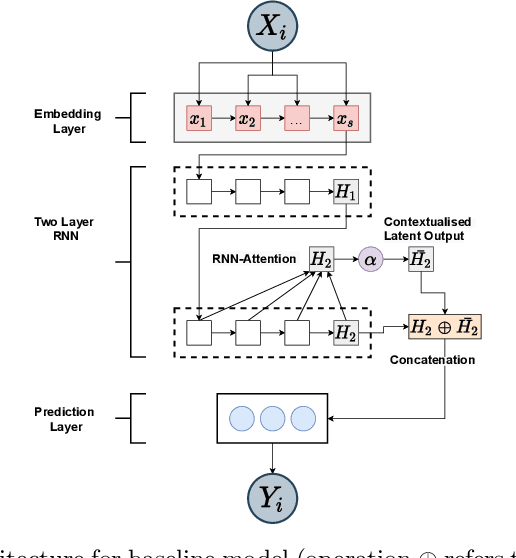
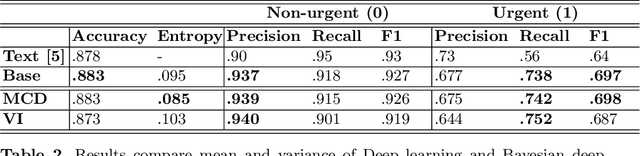
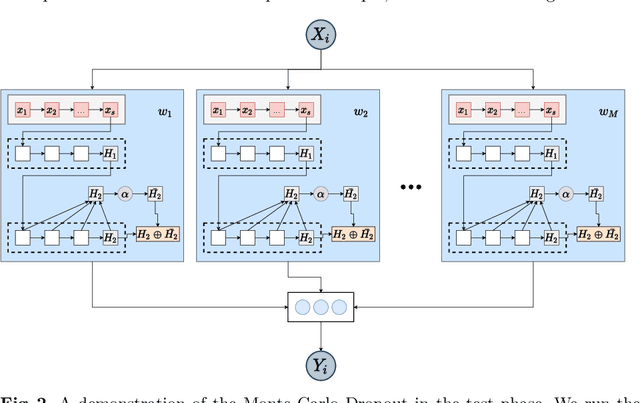
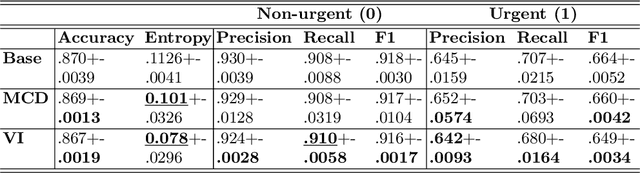
Massive Open Online Courses (MOOCs) have become a popular choice for e-learning thanks to their great flexibility. However, due to large numbers of learners and their diverse backgrounds, it is taxing to offer real-time support. Learners may post their feelings of confusion and struggle in the respective MOOC forums, but with the large volume of posts and high workloads for MOOC instructors, it is unlikely that the instructors can identify all learners requiring intervention. This problem has been studied as a Natural Language Processing (NLP) problem recently, and is known to be challenging, due to the imbalance of the data and the complex nature of the task. In this paper, we explore for the first time Bayesian deep learning on learner-based text posts with two methods: Monte Carlo Dropout and Variational Inference, as a new solution to assessing the need of instructor interventions for a learner's post. We compare models based on our proposed methods with probabilistic modelling to its baseline non-Bayesian models under similar circumstances, for different cases of applying prediction. The results suggest that Bayesian deep learning offers a critical uncertainty measure that is not supplied by traditional neural networks. This adds more explainability, trust and robustness to AI, which is crucial in education-based applications. Additionally, it can achieve similar or better performance compared to non-probabilistic neural networks, as well as grant lower variance.
Predicting MOOCs Dropout Using Only Two Easily Obtainable Features from the First Week's Activities
Aug 12, 2020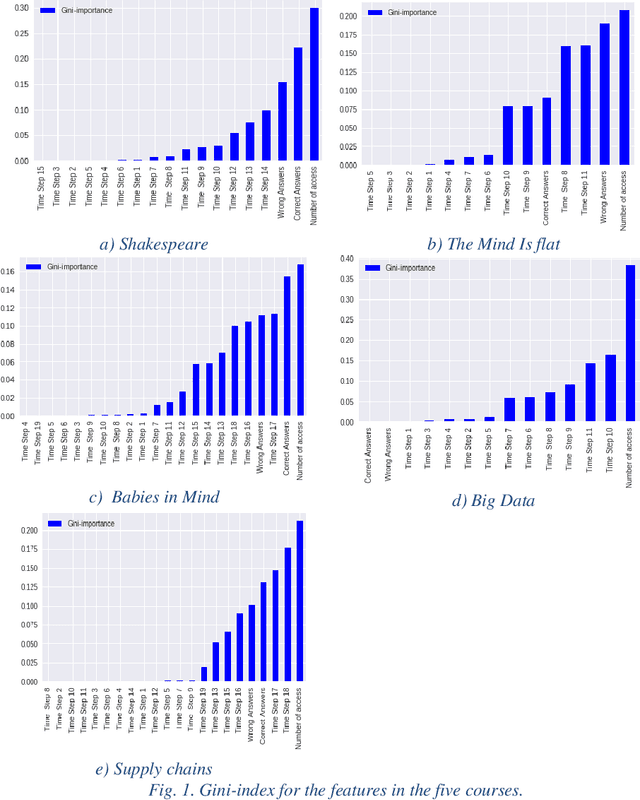
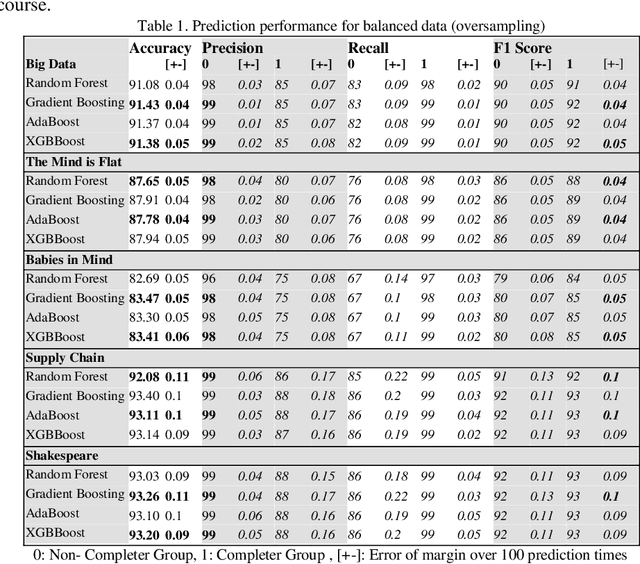
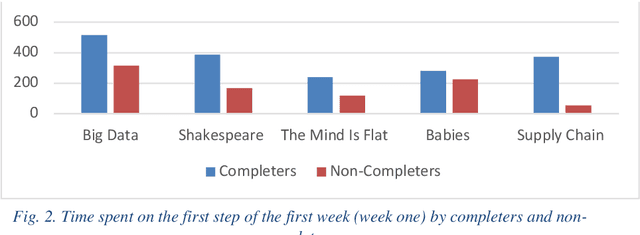
While Massive Open Online Course (MOOCs) platforms provide knowledge in a new and unique way, the very high number of dropouts is a significant drawback. Several features are considered to contribute towards learner attrition or lack of interest, which may lead to disengagement or total dropout. The jury is still out on which factors are the most appropriate predictors. However, the literature agrees that early prediction is vital to allow for a timely intervention. Whilst feature-rich predictors may have the best chance for high accuracy, they may be unwieldy. This study aims to predict learner dropout early-on, from the first week, by comparing several machine-learning approaches, including Random Forest, Adaptive Boost, XGBoost and GradientBoost Classifiers. The results show promising accuracies (82%-94%) using as little as 2 features. We show that the accuracies obtained outperform state of the art approaches, even when the latter deploy several features.
Revealing the Hidden Patterns: A Comparative Study on Profiling Subpopulations of MOOC Students
Aug 12, 2020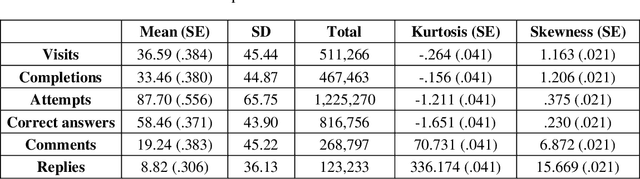
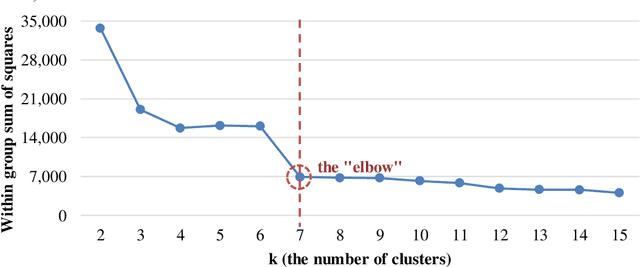
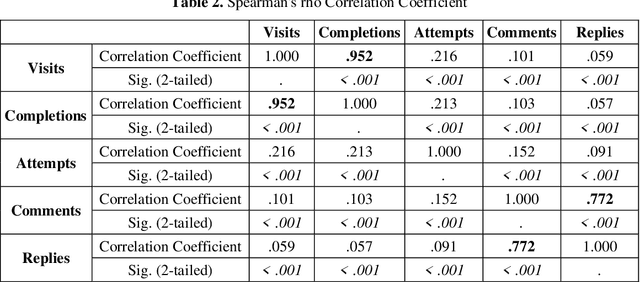
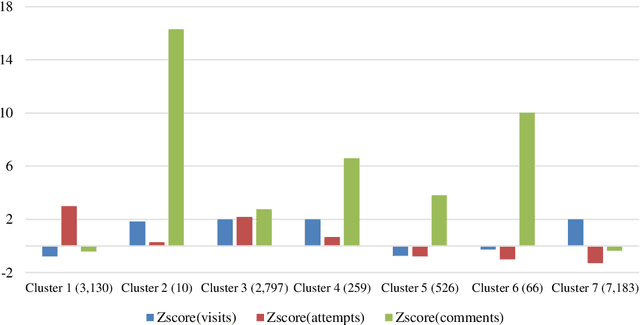
Massive Open Online Courses (MOOCs) exhibit a remarkable heterogeneity of students. The advent of complex "big data" from MOOC platforms is a challenging yet rewarding opportunity to deeply understand how students are engaged in MOOCs. Past research, looking mainly into overall behavior, may have missed patterns related to student diversity. Using a large dataset from a MOOC offered by FutureLearn, we delve into a new way of investigating hidden patterns through both machine learning and statistical modelling. In this paper, we report on clustering analysis of student activities and comparative analysis on both behavioral patterns and demographical patterns between student subpopulations in the MOOC. Our approach allows for a deeper understanding of how MOOC students behave and achieve. Our findings may be used to design adaptive strategies towards an enhanced MOOC experience
Nowcasting the Stance of Social Media Users in a Sudden Vote: The Case of the Greek Referendum
Aug 26, 2018Modelling user voting intention in social media is an important research area, with applications in analysing electorate behaviour, online political campaigning and advertising. Previous approaches mainly focus on predicting national general elections, which are regularly scheduled and where data of past results and opinion polls are available. However, there is no evidence of how such models would perform during a sudden vote under time-constrained circumstances. That poses a more challenging task compared to traditional elections, due to its spontaneous nature. In this paper, we focus on the 2015 Greek bailout referendum, aiming to nowcast on a daily basis the voting intention of 2,197 Twitter users. We propose a semi-supervised multiple convolution kernel learning approach, leveraging temporally sensitive text and network information. Our evaluation under a real-time simulation framework demonstrates the effectiveness and robustness of our approach against competitive baselines, achieving a significant 20% increase in F-score compared to solely text-based models.
Can We Assess Mental Health through Social Media and Smart Devices? Addressing Bias in Methodology and Evaluation
Jul 19, 2018
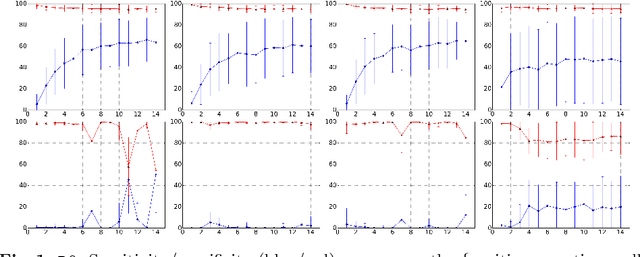
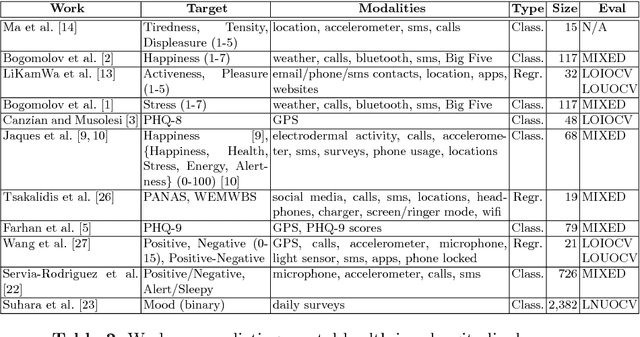
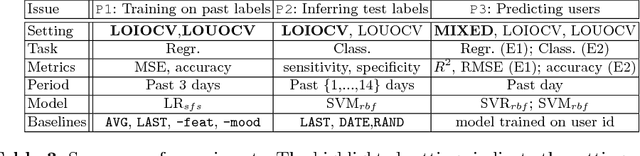
Predicting mental health from smartphone and social media data on a longitudinal basis has recently attracted great interest, with very promising results being reported across many studies. Such approaches have the potential to revolutionise mental health assessment, if their development and evaluation follows a real world deployment setting. In this work we take a closer look at state-of-the-art approaches, using different mental health datasets and indicators, different feature sources and multiple simulations, in order to assess their ability to generalise. We demonstrate that under a pragmatic evaluation framework, none of the approaches deliver or even approach the reported performances. In fact, we show that current state-of-the-art approaches can barely outperform the most na\"ive baselines in the real-world setting, posing serious questions not only about their deployment ability, but also about the contribution of the derived features for the mental health assessment task and how to make better use of such data in the future.