 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbabel's Participation in the WMT20 Metrics Shared Task
Oct 29, 2020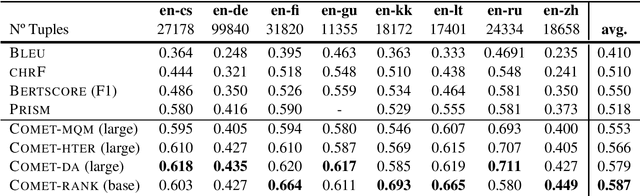
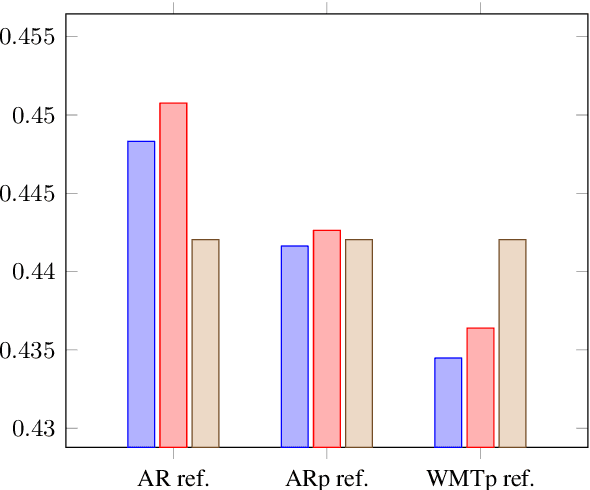
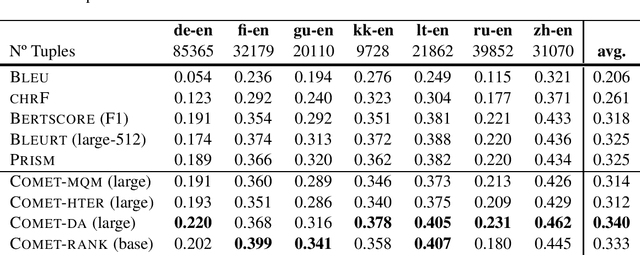
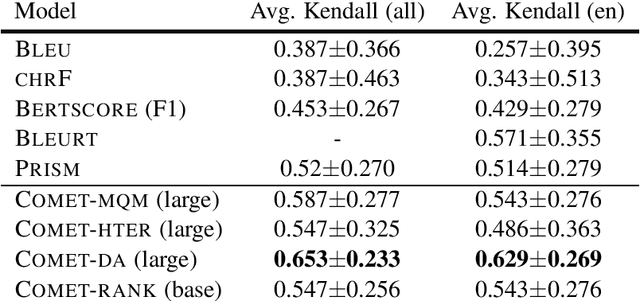
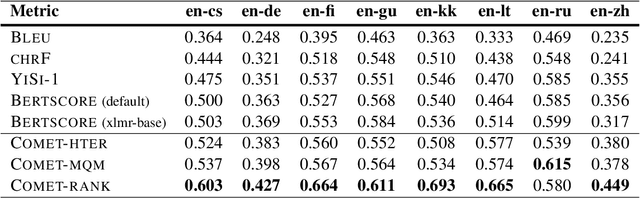
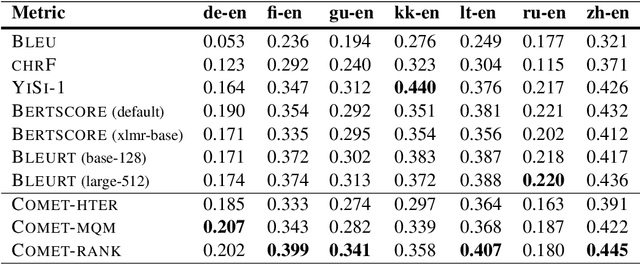
We present the contribution of the Unbabel team to the WMT 2020 Shared Task on Metrics. We intend to participate on the segment-level, document-level and system-level tracks on all language pairs, as well as the 'QE as a Metric' track. Accordingly, we illustrate results of our models in these tracks with reference to test sets from the previous year. Our submissions build upon the recently proposed COMET framework: We train several estimator models to regress on different human-generated quality scores and a novel ranking model trained on relative ranks obtained from Direct Assessments. We also propose a simple technique for converting segment-level predictions into a document-level score. Overall, our systems achieve strong results for all language pairs on previous test sets and in many cases set a new state-of-the-art.
COMET: A Neural Framework for MT Evaluation
Oct 19, 2020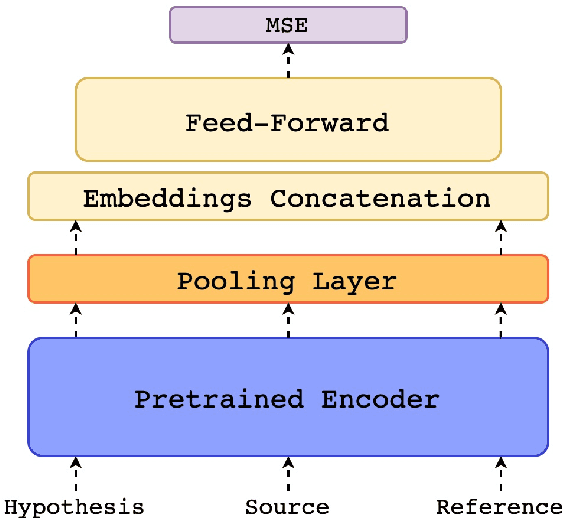
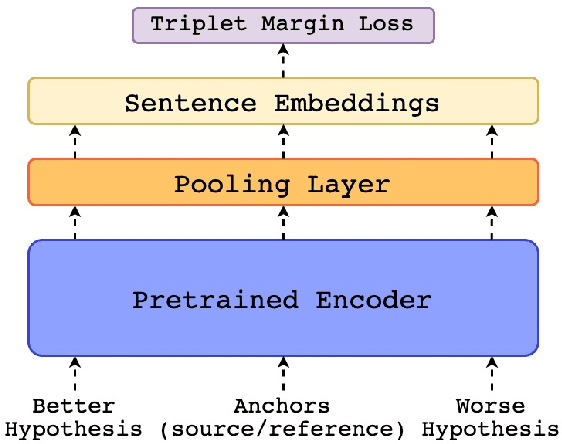
We present COMET, a neural framework for training multilingual machine translation evaluation models which obtains new state-of-the-art levels of correlation with human judgements. Our framework leverages recent breakthroughs in cross-lingual pretrained language modeling resulting in highly multilingual and adaptable MT evaluation models that exploit information from both the source input and a target-language reference translation in order to more accurately predict MT quality. To showcase our framework, we train three models with different types of human judgements: Direct Assessments, Human-mediated Translation Edit Rate and Multidimensional Quality Metrics. Our models achieve new state-of-the-art performance on the WMT 2019 Metrics shared task and demonstrate robustness to high-performing systems.
Predicting MOOCs Dropout Using Only Two Easily Obtainable Features from the First Week's Activities
Aug 12, 2020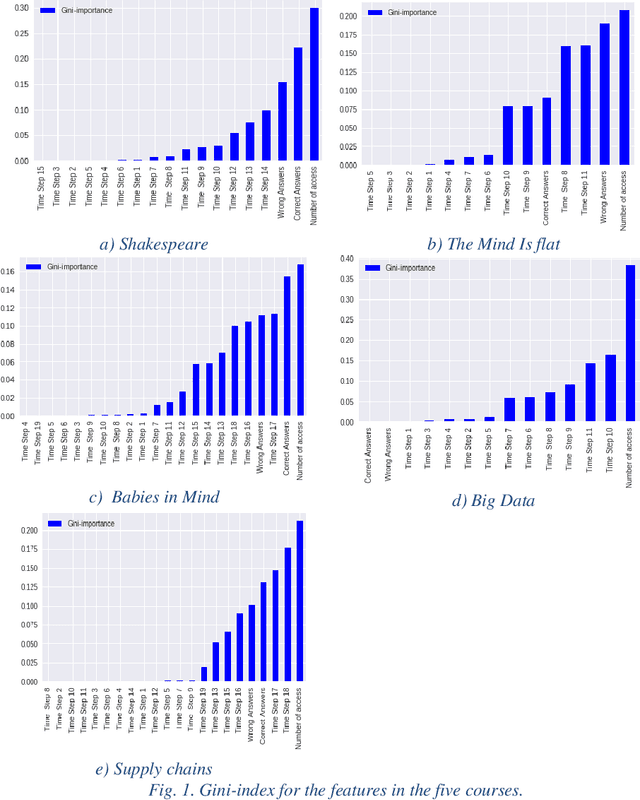
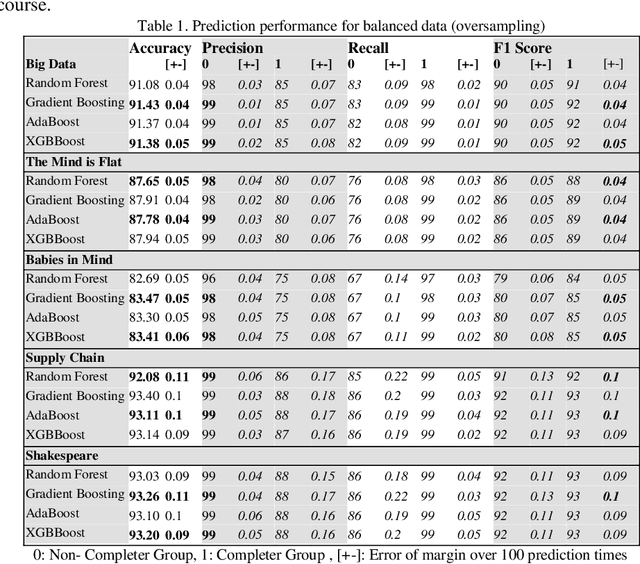
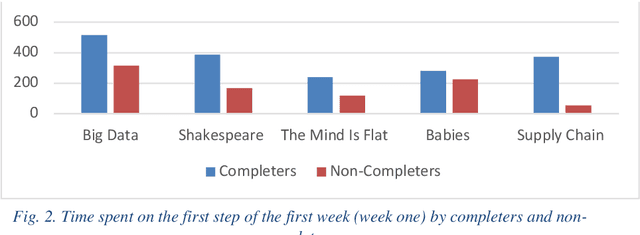
While Massive Open Online Course (MOOCs) platforms provide knowledge in a new and unique way, the very high number of dropouts is a significant drawback. Several features are considered to contribute towards learner attrition or lack of interest, which may lead to disengagement or total dropout. The jury is still out on which factors are the most appropriate predictors. However, the literature agrees that early prediction is vital to allow for a timely intervention. Whilst feature-rich predictors may have the best chance for high accuracy, they may be unwieldy. This study aims to predict learner dropout early-on, from the first week, by comparing several machine-learning approaches, including Random Forest, Adaptive Boost, XGBoost and GradientBoost Classifiers. The results show promising accuracies (82%-94%) using as little as 2 features. We show that the accuracies obtained outperform state of the art approaches, even when the latter deploy several features.
Improving Robustness of Machine Translation with Synthetic Noise
Apr 10, 2019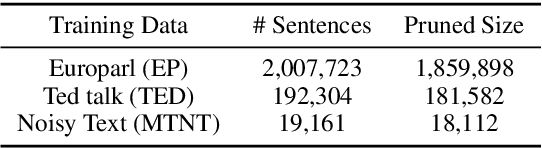

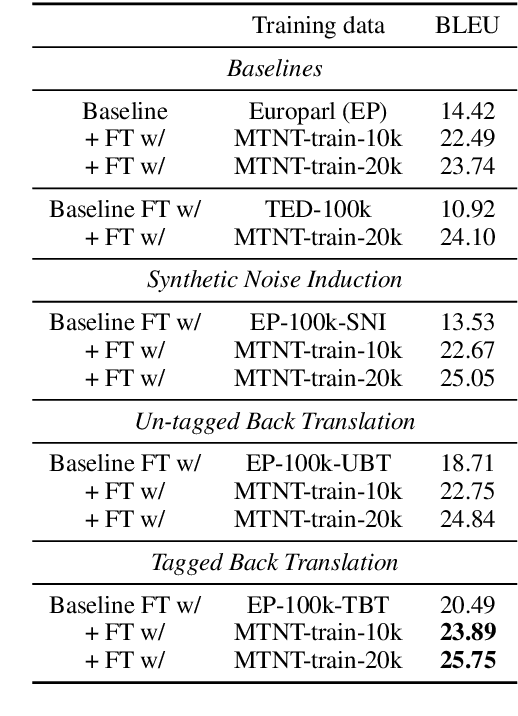
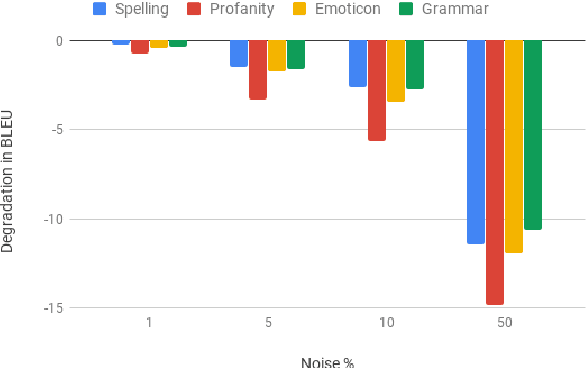
Modern Machine Translation (MT) systems perform consistently well on clean, in-domain text. However most human generated text, particularly in the realm of social media, is full of typos, slang, dialect, idiolect and other noise which can have a disastrous impact on the accuracy of output translation. In this paper we leverage the Machine Translation of Noisy Text (MTNT) dataset to enhance the robustness of MT systems by emulating naturally occurring noise in otherwise clean data. Synthesizing noise in this manner we are ultimately able to make a vanilla MT system resilient to naturally occurring noise and partially mitigate loss in accuracy resulting therefrom.
Lost in Interpretation: Predicting Untranslated Terminology in Simultaneous Interpretation
Apr 01, 2019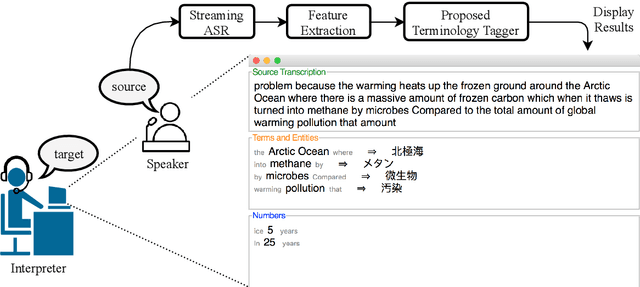
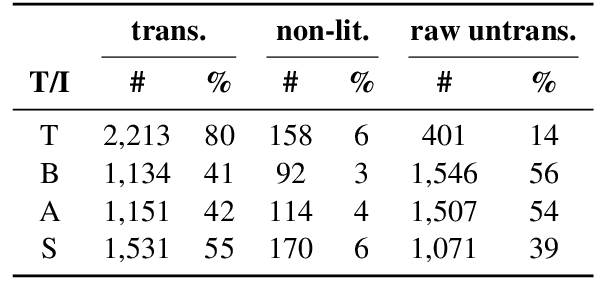

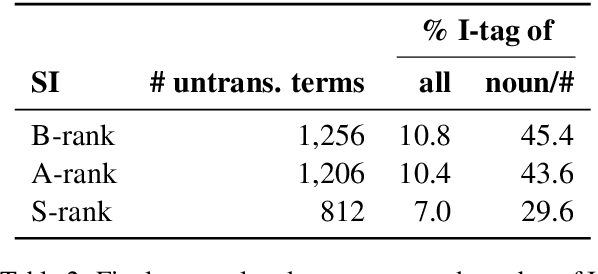
Simultaneous interpretation, the translation of speech from one language to another in real-time, is an inherently difficult and strenuous task. One of the greatest challenges faced by interpreters is the accurate translation of difficult terminology like proper names, numbers, or other entities. Intelligent computer-assisted interpreting (CAI) tools that could analyze the spoken word and detect terms likely to be untranslated by an interpreter could reduce translation error and improve interpreter performance. In this paper, we propose a task of predicting which terminology simultaneous interpreters will leave untranslated, and examine methods that perform this task using supervised sequence taggers. We describe a number of task-specific features explicitly designed to indicate when an interpreter may struggle with translating a word. Experimental results on a newly-annotated version of the NAIST Simultaneous Translation Corpus (Shimizu et al., 2014) indicate the promise of our proposed method.
Automatic Estimation of Simultaneous Interpreter Performance
Jul 06, 2018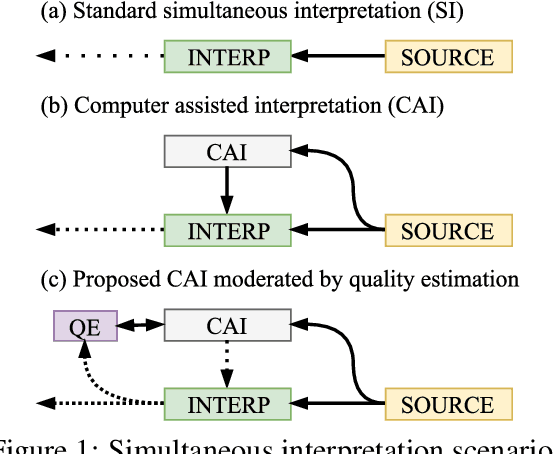
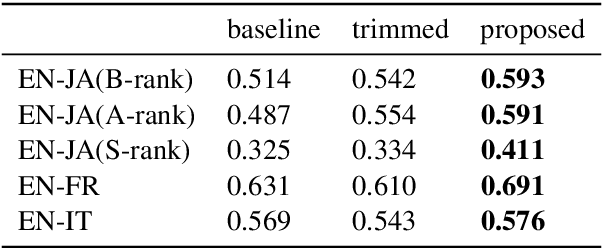
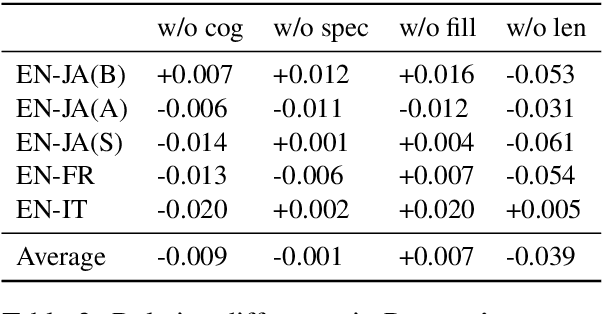
Simultaneous interpretation, translation of the spoken word in real-time, is both highly challenging and physically demanding. Methods to predict interpreter confidence and the adequacy of the interpreted message have a number of potential applications, such as in computer-assisted interpretation interfaces or pedagogical tools. We propose the task of predicting simultaneous interpreter performance by building on existing methodology for quality estimation (QE) of machine translation output. In experiments over five settings in three language pairs, we extend a QE pipeline to estimate interpreter performance (as approximated by the METEOR evaluation metric) and propose novel features reflecting interpretation strategy and evaluation measures that further improve prediction accuracy.