 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Attention Networks for Attribution of Early Modern Print
Jun 12, 2023



In this paper, we develop machine learning techniques to identify unknown printers in early modern (c.~1500--1800) English printed books. Specifically, we focus on matching uniquely damaged character type-imprints in anonymously printed books to works with known printers in order to provide evidence of their origins. Until now, this work has been limited to manual investigations by analytical bibliographers. We present a Contrastive Attention-based Metric Learning approach to identify similar damage across character image pairs, which is sensitive to very subtle differences in glyph shapes, yet robust to various confounding sources of noise associated with digitized historical books. To overcome the scarce amount of supervised data, we design a random data synthesis procedure that aims to simulate bends, fractures, and inking variations induced by the early printing process. Our method successfully improves downstream damaged type-imprint matching among printed works from this period, as validated by in-domain human experts. The results of our approach on two important philosophical works from the Early Modern period demonstrate potential to extend the extant historical research about the origins and content of these books.
Non-Parametric Temporal Adaptation for Social Media Topic Classification
Sep 13, 2022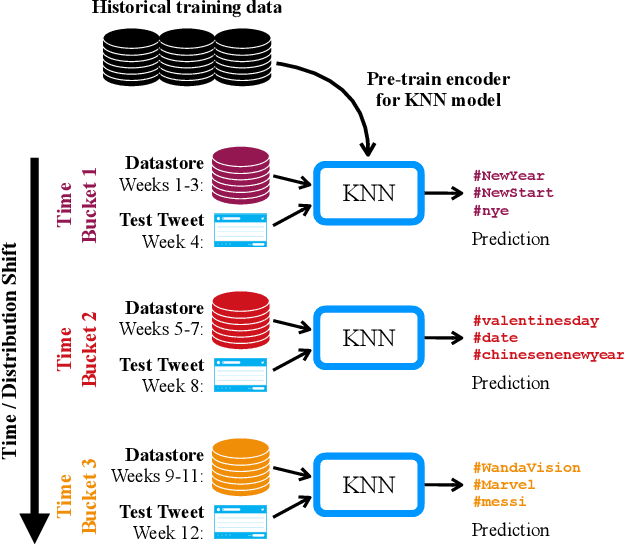
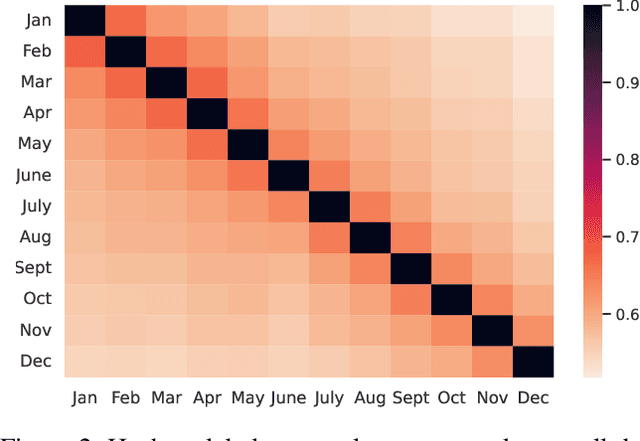
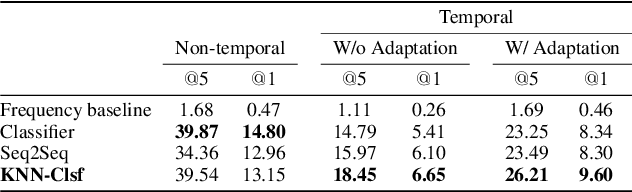
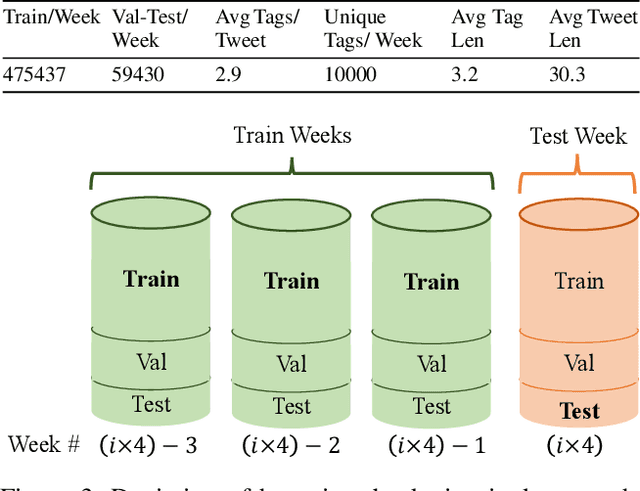
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.
An Unsupervised Masking Objective for Abstractive Multi-Document News Summarization
Jan 07, 2022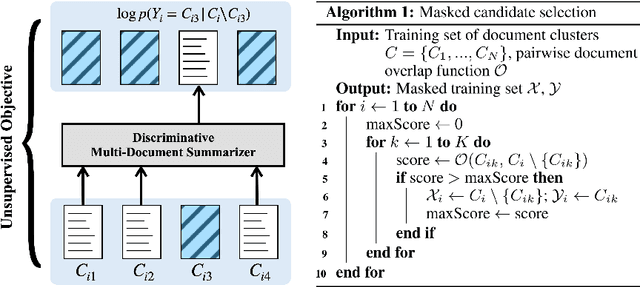

We show that a simple unsupervised masking objective can approach near supervised performance on abstractive multi-document news summarization. Our method trains a state-of-the-art neural summarization model to predict the masked out source document with highest lexical centrality relative to the multi-document group. In experiments on the Multi-News dataset, our masked training objective yields a system that outperforms past unsupervised methods and, in human evaluation, surpasses the best supervised method without requiring access to any ground-truth summaries. Further, we evaluate how different measures of lexical centrality, inspired by past work on extractive summarization, affect final performance.
Lacuna Reconstruction: Self-supervised Pre-training for Low-Resource Historical Document Transcription
Dec 16, 2021
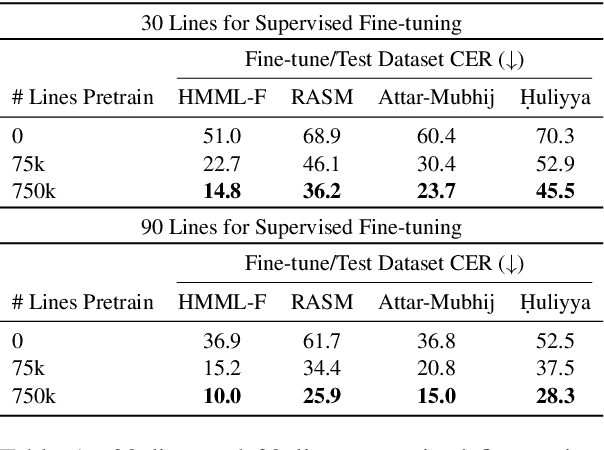
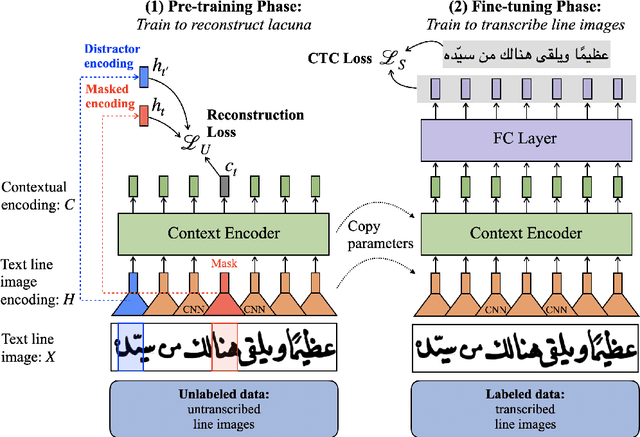

We present a self-supervised pre-training approach for learning rich visual language representations for both handwritten and printed historical document transcription. After supervised fine-tuning of our pre-trained encoder representations for low-resource document transcription on two languages, (1) a heterogeneous set of handwritten Islamicate manuscript images and (2) early modern English printed documents, we show a meaningful improvement in recognition accuracy over the same supervised model trained from scratch with as few as 30 line image transcriptions for training. Our masked language model-style pre-training strategy, where the model is trained to be able to identify the true masked visual representation from distractors sampled from within the same line, encourages learning robust contextualized language representations invariant to scribal writing style and printing noise present across documents.
Lost in Interpretation: Predicting Untranslated Terminology in Simultaneous Interpretation
Apr 01, 2019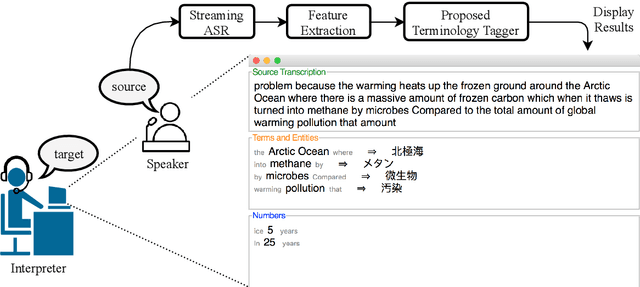
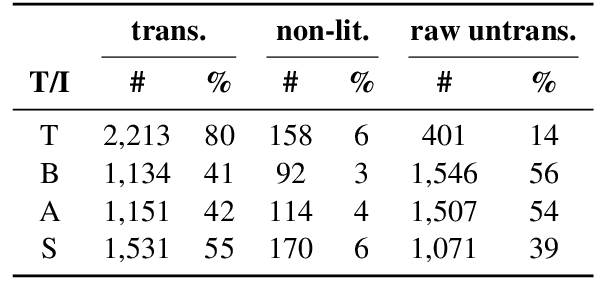

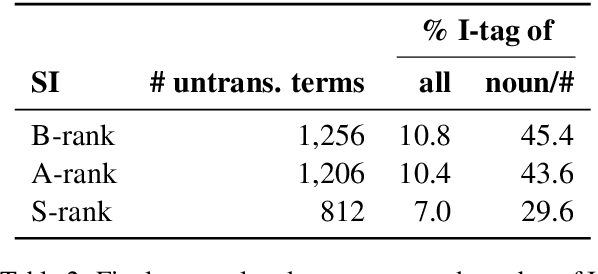
Simultaneous interpretation, the translation of speech from one language to another in real-time, is an inherently difficult and strenuous task. One of the greatest challenges faced by interpreters is the accurate translation of difficult terminology like proper names, numbers, or other entities. Intelligent computer-assisted interpreting (CAI) tools that could analyze the spoken word and detect terms likely to be untranslated by an interpreter could reduce translation error and improve interpreter performance. In this paper, we propose a task of predicting which terminology simultaneous interpreters will leave untranslated, and examine methods that perform this task using supervised sequence taggers. We describe a number of task-specific features explicitly designed to indicate when an interpreter may struggle with translating a word. Experimental results on a newly-annotated version of the NAIST Simultaneous Translation Corpus (Shimizu et al., 2014) indicate the promise of our proposed method.
Automatic Estimation of Simultaneous Interpreter Performance
Jul 06, 2018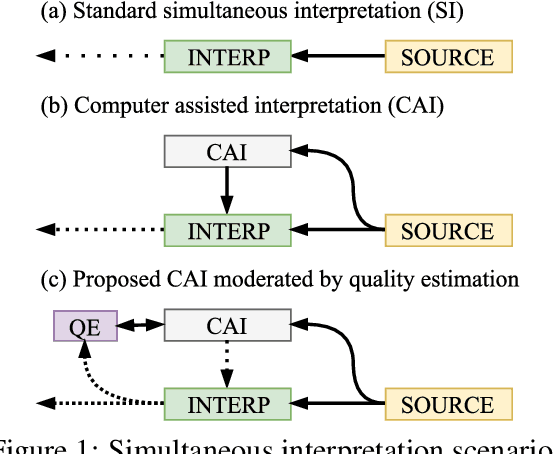
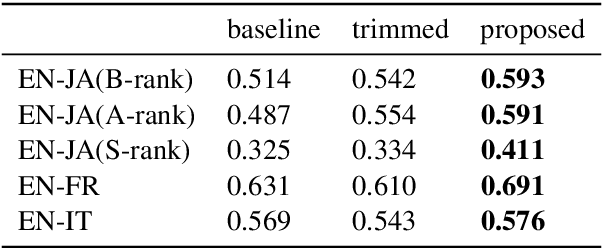
Simultaneous interpretation, translation of the spoken word in real-time, is both highly challenging and physically demanding. Methods to predict interpreter confidence and the adequacy of the interpreted message have a number of potential applications, such as in computer-assisted interpretation interfaces or pedagogical tools. We propose the task of predicting simultaneous interpreter performance by building on existing methodology for quality estimation (QE) of machine translation output. In experiments over five settings in three language pairs, we extend a QE pipeline to estimate interpreter performance (as approximated by the METEOR evaluation metric) and propose novel features reflecting interpretation strategy and evaluation measures that further improve prediction accuracy.