 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Conditional Alt-Text Generation for Twitter Images
May 24, 2023In this work we present an approach for generating alternative text (or alt-text) descriptions for images shared on social media, specifically Twitter. This task is more than just a special case of image captioning, as alt-text is both more literally descriptive and context-specific. Also critically, images posted to Twitter are often accompanied by user-written text that despite not necessarily describing the image may provide useful context that if properly leveraged can be informative -- e.g. the tweet may name an uncommon object in the image that the model has not previously seen. We address this with a CLIP prefix model that extracts an embedding of the image and passes it to a mapping network that outputs a short sequence in word embedding space, or a ``prefix'', to which we also concatenate the text from the tweet itself. This lets the model condition on both visual and textual information from the post. The combined multimodal prefix is then fed as a prompt to a pretrained language model which autoregressively completes the sequence to generate the alt-text. While prior work has used similar methods for captioning, ours is the first to our knowledge that incorporates textual information from the associated social media post into the prefix as well, and we further demonstrate through ablations that utility of these two information sources stacks. We put forward a new dataset scraped from Twitter and evaluate on it across a variety of automated metrics as well as human evaluation, and show that our approach of conditioning on both tweet text and visual information significantly outperforms prior work.
TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Sep 15, 2022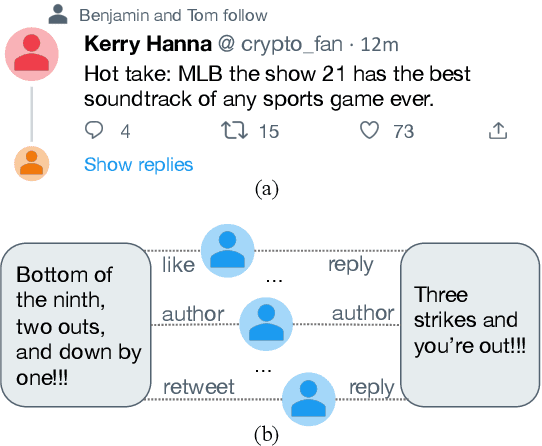
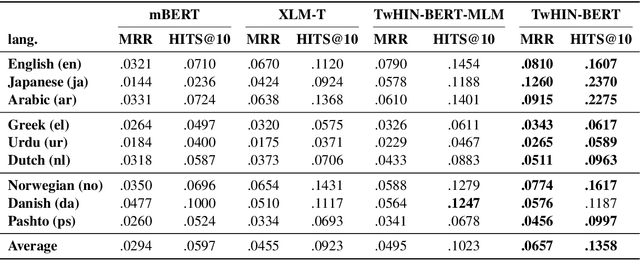

We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.
Non-Parametric Temporal Adaptation for Social Media Topic Classification
Sep 13, 2022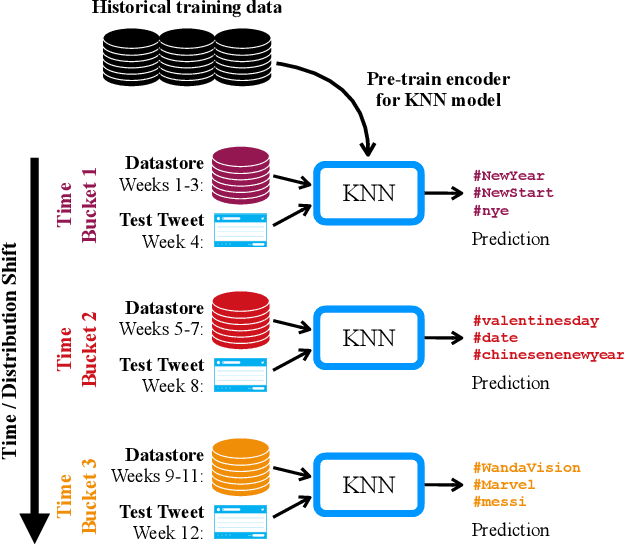
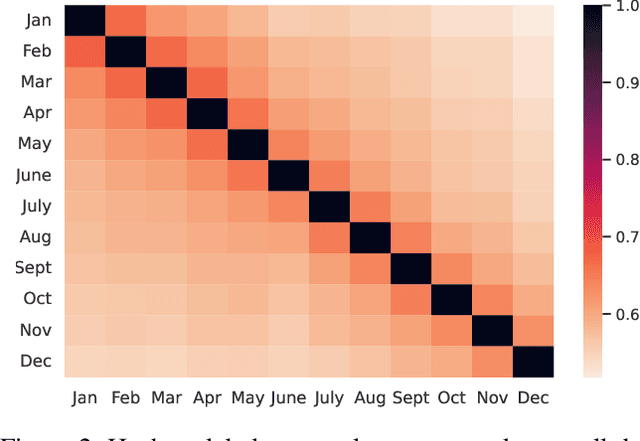
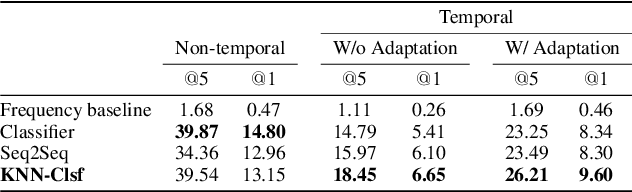
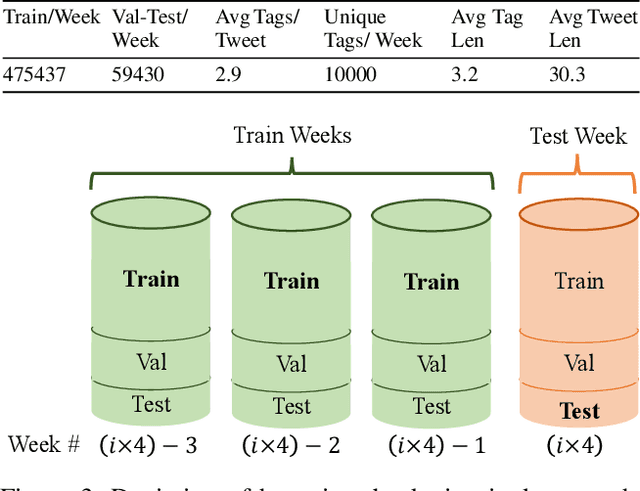
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.