 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Paper and Code
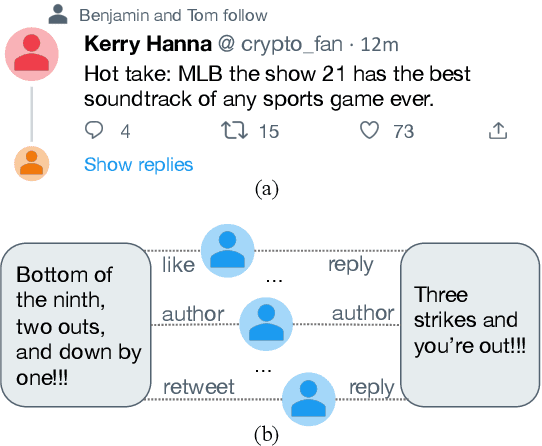
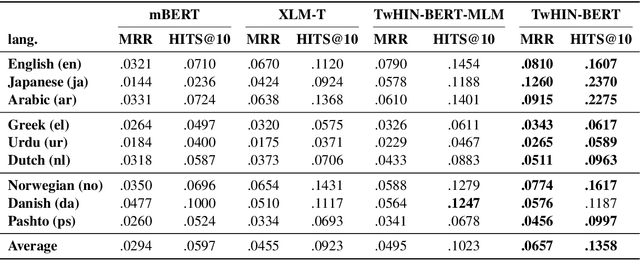

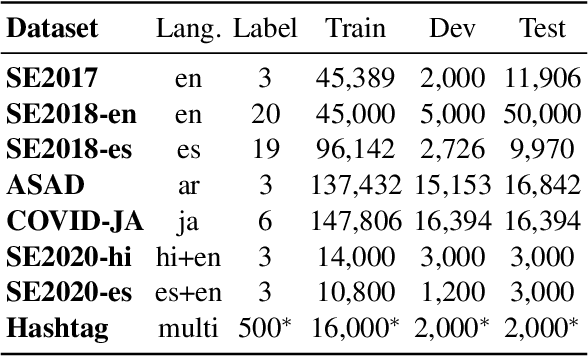
We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.