 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiGL: Large-Scale Graph Neural Networks at Snapchat
Feb 20, 2025Recent advances in graph machine learning (ML) with the introduction of Graph Neural Networks (GNNs) have led to a widespread interest in applying these approaches to business applications at scale. GNNs enable differentiable end-to-end (E2E) learning of model parameters given graph structure which enables optimization towards popular node, edge (link) and graph-level tasks. While the research innovation in new GNN layers and training strategies has been rapid, industrial adoption and utility of GNNs has lagged considerably due to the unique scale challenges that large-scale graph ML problems create. In this work, we share our approach to training, inference, and utilization of GNNs at Snapchat. To this end, we present GiGL (Gigantic Graph Learning), an open-source library to enable large-scale distributed graph ML to the benefit of researchers, ML engineers, and practitioners. We use GiGL internally at Snapchat to manage the heavy lifting of GNN workflows, including graph data preprocessing from relational DBs, subgraph sampling, distributed training, inference, and orchestration. GiGL is designed to interface cleanly with open-source GNN modeling libraries prominent in academia like PyTorch Geometric (PyG), while handling scaling and productionization challenges that make it easier for internal practitioners to focus on modeling. GiGL is used in multiple production settings, and has powered over 35 launches across multiple business domains in the last 2 years in the contexts of friend recommendation, content recommendation and advertising. This work details high-level design and tools the library provides, scaling properties, case studies in diverse business settings with industry-scale graphs, and several key lessons learned in employing graph ML at scale on large social data. GiGL is open-sourced at https://github.com/snap-research/GiGL.
TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Sep 15, 2022
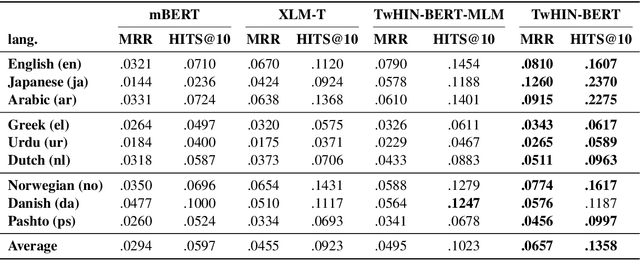

We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.
HABERTOR: An Efficient and Effective Deep Hatespeech Detector
Oct 17, 2020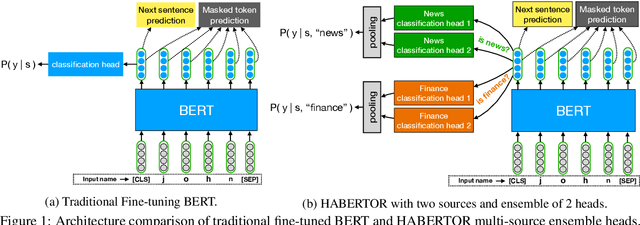
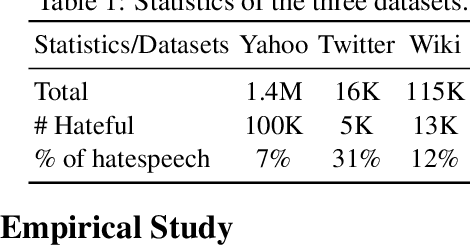

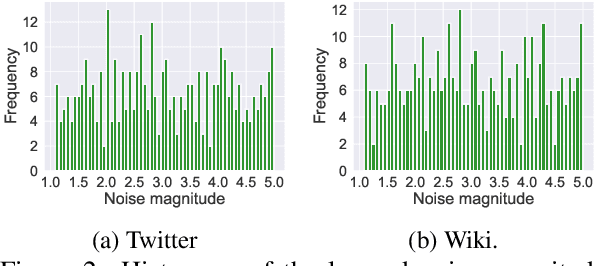
We present our HABERTOR model for detecting hatespeech in large scale user-generated content. Inspired by the recent success of the BERT model, we propose several modifications to BERT to enhance the performance on the downstream hatespeech classification task. HABERTOR inherits BERT's architecture, but is different in four aspects: (i) it generates its own vocabularies and is pre-trained from the scratch using the largest scale hatespeech dataset; (ii) it consists of Quaternion-based factorized components, resulting in a much smaller number of parameters, faster training and inferencing, as well as less memory usage; (iii) it uses our proposed multi-source ensemble heads with a pooling layer for separate input sources, to further enhance its effectiveness; and (iv) it uses a regularized adversarial training with our proposed fine-grained and adaptive noise magnitude to enhance its robustness. Through experiments on the large-scale real-world hatespeech dataset with 1.4M annotated comments, we show that HABERTOR works better than 15 state-of-the-art hatespeech detection methods, including fine-tuning Language Models. In particular, comparing with BERT, our HABERTOR is 4~5 times faster in the training/inferencing phase, uses less than 1/3 of the memory, and has better performance, even though we pre-train it by using less than 1% of the number of words. Our generalizability analysis shows that HABERTOR transfers well to other unseen hatespeech datasets and is a more efficient and effective alternative to BERT for the hatespeech classification.
A Transportation $L^p$ Distance for Signal Analysis
Sep 27, 2016
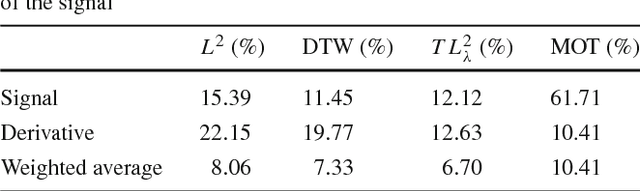
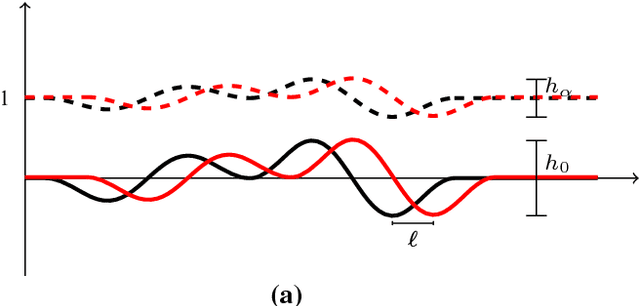
Transport based distances, such as the Wasserstein distance and earth mover's distance, have been shown to be an effective tool in signal and image analysis. The success of transport based distances is in part due to their Lagrangian nature which allows it to capture the important variations in many signal classes. However these distances require the signal to be nonnegative and normalized. Furthermore, the signals are considered as measures and compared by redistributing (transporting) them, which does not directly take into account the signal intensity. Here we study a transport-based distance, called the $TL^p$ distance, that combines Lagrangian and intensity modelling and is directly applicable to general, non-positive and multi-channelled signals. The framework allows the application of existing numerical methods. We give an overview of the basic properties of this distance and applications to classification, with multi-channelled, non-positive one and two-dimensional signals, and color transfer.
Transport-based analysis, modeling, and learning from signal and data distributions
Sep 15, 2016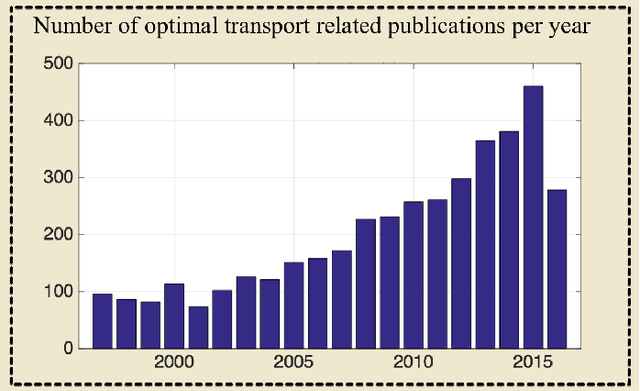
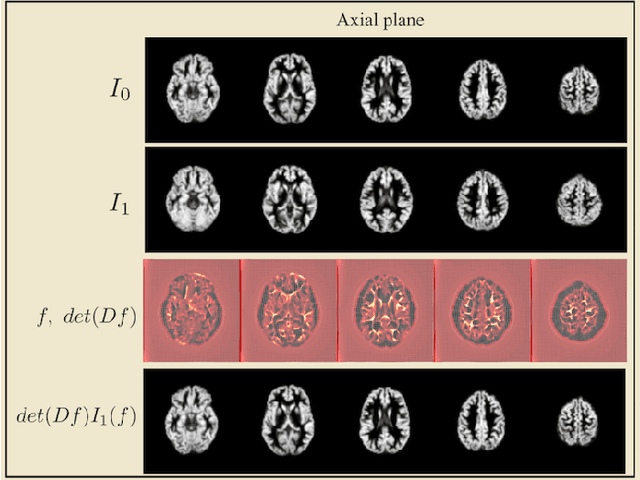
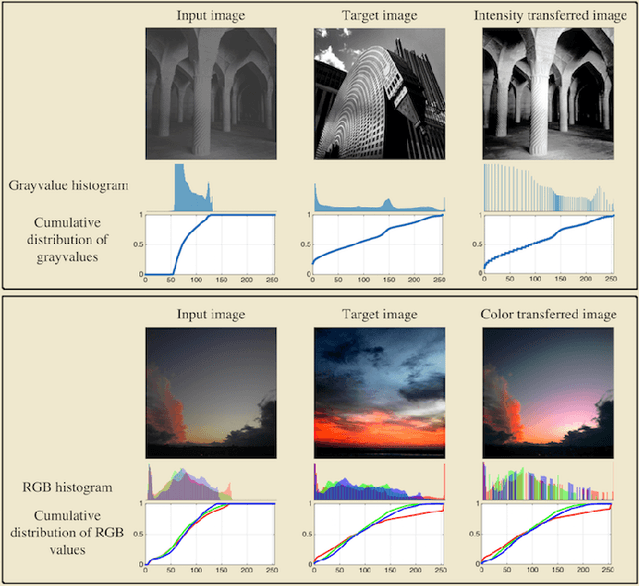
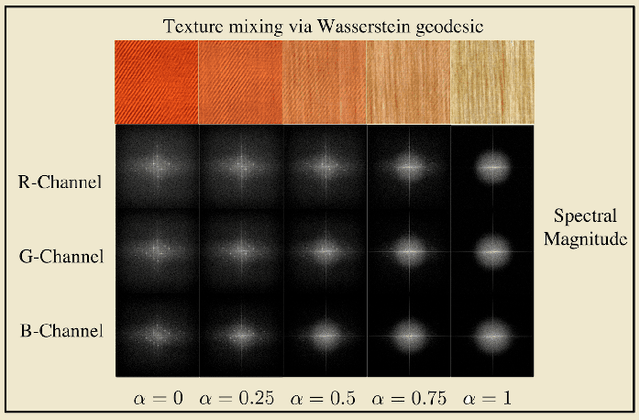
Transport-based techniques for signal and data analysis have received increased attention recently. Given their abilities to provide accurate generative models for signal intensities and other data distributions, they have been used in a variety of applications including content-based retrieval, cancer detection, image super-resolution, and statistical machine learning, to name a few, and shown to produce state of the art in several applications. Moreover, the geometric characteristics of transport-related metrics have inspired new kinds of algorithms for interpreting the meaning of data distributions. Here we provide an overview of the mathematical underpinnings of mass transport-related methods, including numerical implementation, as well as a review, with demonstrations, of several applications.