 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartGD: A Self-Challenging Generative Adversarial Network for Graph Drawing
Jun 13, 2022



A multitude of studies have been conducted on graph drawing, but many existing methods only focus on optimizing particular aesthetic aspects of graph layout. Given a graph, generating a good layout that satisfies certain human aesthetic preference remains a challenging task, especially if such preference can not be expressed as a differentiable objective function. In this paper, we propose a student-teacher GAN-based graph drawing framework, SmartGD, which learns to draw graphs just like how humans learn to perform tasks. The student network in the SmartGD learns graph drawing by imitating good layout examples, while the teacher network in SmartGD is responsible for providing ratings regarding the goodness of the generated layouts. When there is a lack of concrete aesthetic criteria to specify what constitutes a good layout, the student network can learn from the good layout examples. On the other hand, when the goodness of a layout can be assessed by quantitative criteria (even if not differentiable), the student network can use it as a concrete goal to optimize the target aesthetics. To accomplish the goal, we propose a novel variant of GAN, self-challenging GAN, to learn the optimal layout distribution with respect to any aesthetic criterion, whether the criterion is differentiable or not. The proposed graph drawing framework can not only draw graphs in a similar style as the good layout examples but also optimize the graph layouts according to any given aesthetic criteria when available. Once the model is trained, it can be used to visualize arbitrary graphs according to the style of the example layouts or the chosen aesthetic criteria. The comprehensive experimental studies show that SmartGD outperforms 12 benchmark methods according to the commonly agreed metrics.
Perturbations in the Wild: Leveraging Human-Written Text Perturbations for Realistic Adversarial Attack and Defense
Mar 19, 2022



We proposes a novel algorithm, ANTHRO, that inductively extracts over 600K human-written text perturbations in the wild and leverages them for realistic adversarial attack. Unlike existing character-based attacks which often deductively hypothesize a set of manipulation strategies, our work is grounded on actual observations from real-world texts. We find that adversarial texts generated by ANTHRO achieve the best trade-off between (1) attack success rate, (2) semantic preservation of the original text, and (3) stealthiness--i.e. indistinguishable from human writings hence harder to be flagged as suspicious. Specifically, our attacks accomplished around 83% and 91% attack success rates on BERT and RoBERTa, respectively. Moreover, it outperformed the TextBugger baseline with an increase of 50% and 40% in terms of semantic preservation and stealthiness when evaluated by both layperson and professional human workers. ANTHRO can further enhance a BERT classifier's performance in understanding different variations of human-written toxic texts via adversarial training when compared to the Perspective API.
BERT-Beta: A Proactive Probabilistic Approach to Text Moderation
Sep 18, 2021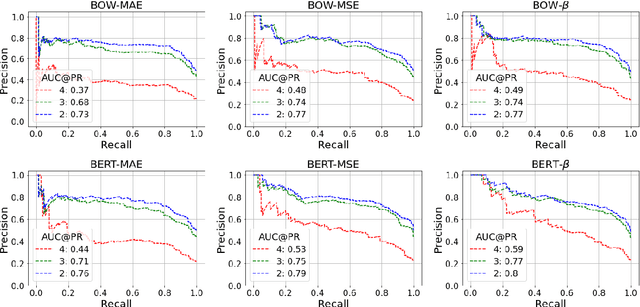
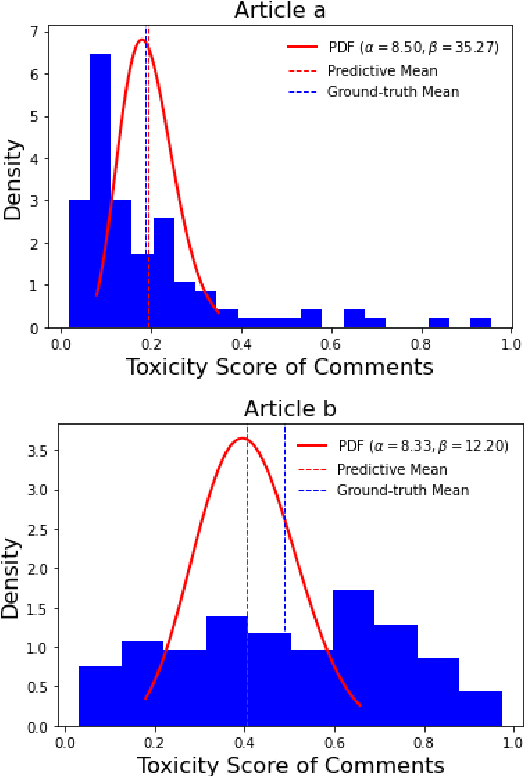
Text moderation for user generated content, which helps to promote healthy interaction among users, has been widely studied and many machine learning models have been proposed. In this work, we explore an alternative perspective by augmenting reactive reviews with proactive forecasting. Specifically, we propose a new concept {\it text toxicity propensity} to characterize the extent to which a text tends to attract toxic comments. Beta regression is then introduced to do the probabilistic modeling, which is demonstrated to function well in comprehensive experiments. We also propose an explanation method to communicate the model decision clearly. Both propensity scoring and interpretation benefit text moderation in a novel manner. Finally, the proposed scaling mechanism for the linear model offers useful insights beyond this work.
TSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity
Aug 18, 2021
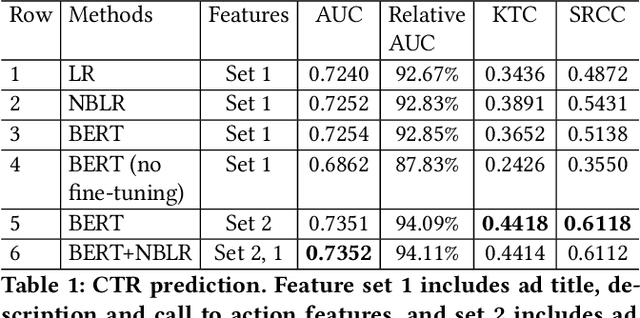
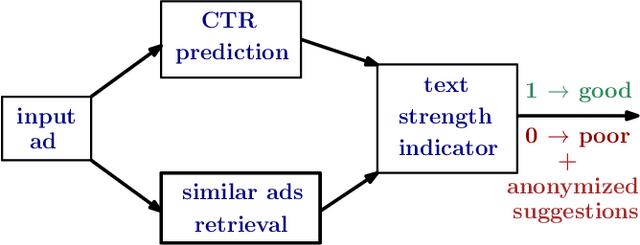

Coming up with effective ad text is a time consuming process, and particularly challenging for small businesses with limited advertising experience. When an inexperienced advertiser onboards with a poorly written ad text, the ad platform has the opportunity to detect low performing ad text, and provide improvement suggestions. To realize this opportunity, we propose an ad text strength indicator (TSI) which: (i) predicts the click-through-rate (CTR) for an input ad text, (ii) fetches similar existing ads to create a neighborhood around the input ad, (iii) and compares the predicted CTRs in the neighborhood to declare whether the input ad is strong or weak. In addition, as suggestions for ad text improvement, TSI shows anonymized versions of superior ads (higher predicted CTR) in the neighborhood. For (i), we propose a BERT based text-to-CTR model trained on impressions and clicks associated with an ad text. For (ii), we propose a sentence-BERT based semantic-ad-similarity model trained using weak labels from ad campaign setup data. Offline experiments demonstrate that our BERT based text-to-CTR model achieves a significant lift in CTR prediction AUC for cold start (new) advertisers compared to bag-of-words based baselines. In addition, our semantic-textual-similarity model for similar ads retrieval achieves a precision@1 of 0.93 (for retrieving ads from the same product category); this is significantly higher compared to unsupervised TF-IDF, word2vec, and sentence-BERT baselines. Finally, we share promising online results from advertisers in the Yahoo (Verizon Media) ad platform where a variant of TSI was implemented with sub-second end-to-end latency.
DeepGD: A Deep Learning Framework for Graph Drawing Using GNN
Jun 27, 2021
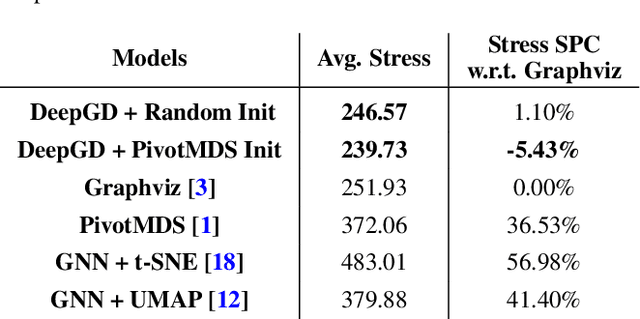

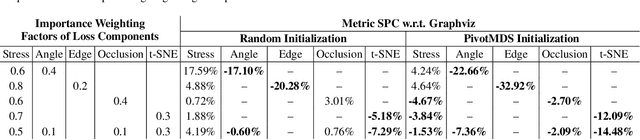
In the past decades, many graph drawing techniques have been proposed for generating aesthetically pleasing graph layouts. However, it remains a challenging task since different layout methods tend to highlight different characteristics of the graphs. Recently, studies on deep learning based graph drawing algorithm have emerged but they are often not generalizable to arbitrary graphs without re-training. In this paper, we propose a Convolutional Graph Neural Network based deep learning framework, DeepGD, which can draw arbitrary graphs once trained. It attempts to generate layouts by compromising among multiple pre-specified aesthetics considering a good graph layout usually complies with multiple aesthetics simultaneously. In order to balance the trade-off, we propose two adaptive training strategies which adjust the weight factor of each aesthetic dynamically during training. The quantitative and qualitative assessment of DeepGD demonstrates that it is capable of drawing arbitrary graphs effectively, while being flexible at accommodating different aesthetic criteria.
Political Posters Identification with Appearance-Text Fusion
Dec 19, 2020
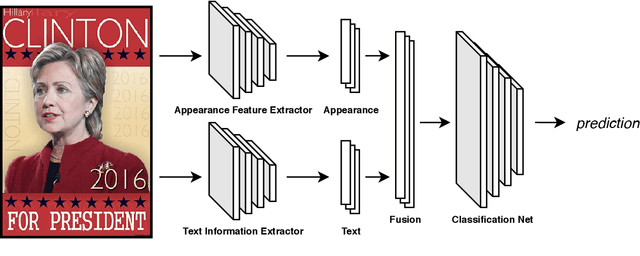

In this paper, we propose a method that efficiently utilizes appearance features and text vectors to accurately classify political posters from other similar political images. The majority of this work focuses on political posters that are designed to serve as a promotion of a certain political event, and the automated identification of which can lead to the generation of detailed statistics and meets the judgment needs in a variety of areas. Starting with a comprehensive keyword list for politicians and political events, we curate for the first time an effective and practical political poster dataset containing 13K human-labeled political images, including 3K political posters that explicitly support a movement or a campaign. Second, we make a thorough case study for this dataset and analyze common patterns and outliers of political posters. Finally, we propose a model that combines the power of both appearance and text information to classify political posters with significantly high accuracy.
HABERTOR: An Efficient and Effective Deep Hatespeech Detector
Oct 17, 2020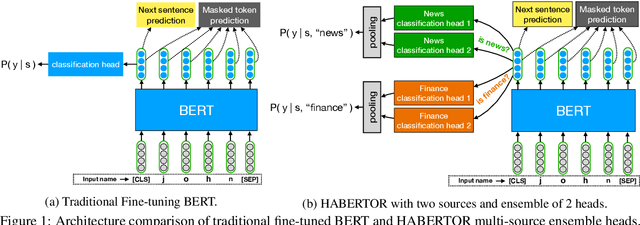
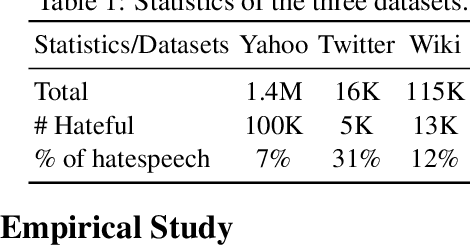

We present our HABERTOR model for detecting hatespeech in large scale user-generated content. Inspired by the recent success of the BERT model, we propose several modifications to BERT to enhance the performance on the downstream hatespeech classification task. HABERTOR inherits BERT's architecture, but is different in four aspects: (i) it generates its own vocabularies and is pre-trained from the scratch using the largest scale hatespeech dataset; (ii) it consists of Quaternion-based factorized components, resulting in a much smaller number of parameters, faster training and inferencing, as well as less memory usage; (iii) it uses our proposed multi-source ensemble heads with a pooling layer for separate input sources, to further enhance its effectiveness; and (iv) it uses a regularized adversarial training with our proposed fine-grained and adaptive noise magnitude to enhance its robustness. Through experiments on the large-scale real-world hatespeech dataset with 1.4M annotated comments, we show that HABERTOR works better than 15 state-of-the-art hatespeech detection methods, including fine-tuning Language Models. In particular, comparing with BERT, our HABERTOR is 4~5 times faster in the training/inferencing phase, uses less than 1/3 of the memory, and has better performance, even though we pre-train it by using less than 1% of the number of words. Our generalizability analysis shows that HABERTOR transfers well to other unseen hatespeech datasets and is a more efficient and effective alternative to BERT for the hatespeech classification.