 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Quality Assessment for Machines: Paradigm, Large-scale Database, and Models
Aug 27, 2025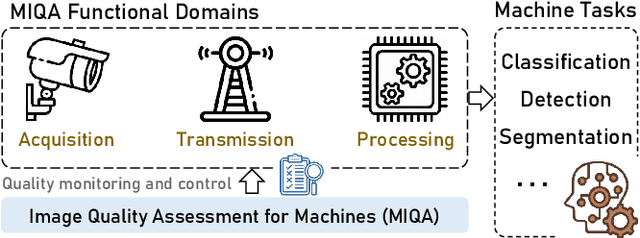

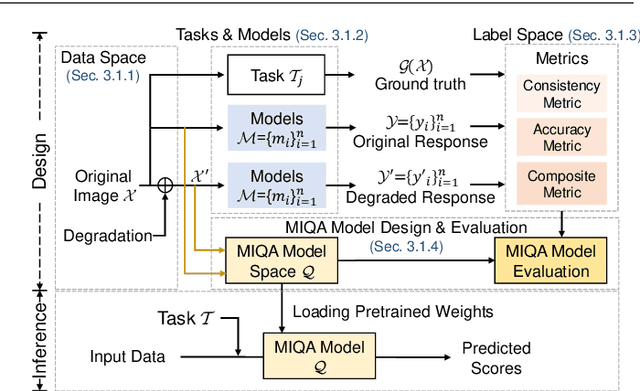
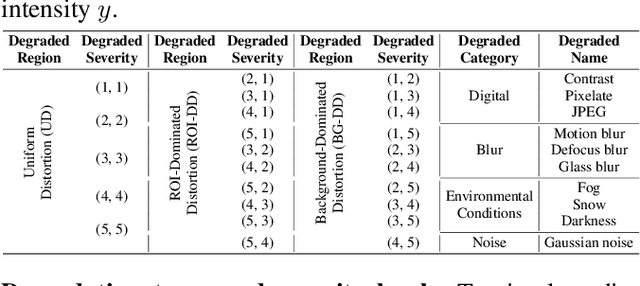
Machine vision systems (MVS) are intrinsically vulnerable to performance degradation under adverse visual conditions. To address this, we propose a machine-centric image quality assessment (MIQA) framework that quantifies the impact of image degradations on MVS performance. We establish an MIQA paradigm encompassing the end-to-end assessment workflow. To support this, we construct a machine-centric image quality database (MIQD-2.5M), comprising 2.5 million samples that capture distinctive degradation responses in both consistency and accuracy metrics, spanning 75 vision models, 250 degradation types, and three representative vision tasks. We further propose a region-aware MIQA (RA-MIQA) model to evaluate MVS visual quality through fine-grained spatial degradation analysis. Extensive experiments benchmark the proposed RA-MIQA against seven human visual system (HVS)-based IQA metrics and five retrained classical backbones. Results demonstrate RA-MIQA's superior performance in multiple dimensions, e.g., achieving SRCC gains of 13.56% on consistency and 13.37% on accuracy for image classification, while also revealing task-specific degradation sensitivities. Critically, HVS-based metrics prove inadequate for MVS quality prediction, while even specialized MIQA models struggle with background degradations, accuracy-oriented estimation, and subtle distortions. This study can advance MVS reliability and establish foundations for machine-centric image processing and optimization. The model and code are available at: https://github.com/XiaoqiWang/MIQA.
EVA02-AT: Egocentric Video-Language Understanding with Spatial-Temporal Rotary Positional Embeddings and Symmetric Optimization
Jun 17, 2025Egocentric video-language understanding demands both high efficiency and accurate spatial-temporal modeling. Existing approaches face three key challenges: 1) Excessive pre-training cost arising from multi-stage pre-training pipelines, 2) Ineffective spatial-temporal encoding due to manually split 3D rotary positional embeddings that hinder feature interactions, and 3) Imprecise learning objectives in soft-label multi-instance retrieval, which neglect negative pair correlations. In this paper, we introduce EVA02-AT, a suite of EVA02-based video-language foundation models tailored to egocentric video understanding tasks. EVA02-AT first efficiently transfers an image-based CLIP model into a unified video encoder via a single-stage pretraining. Second, instead of applying rotary positional embeddings to isolated dimensions, we introduce spatial-temporal rotary positional embeddings along with joint attention, which can effectively encode both spatial and temporal information on the entire hidden dimension. This joint encoding of spatial-temporal features enables the model to learn cross-axis relationships, which are crucial for accurately modeling motion and interaction in videos. Third, focusing on multi-instance video-language retrieval tasks, we introduce the Symmetric Multi-Similarity (SMS) loss and a novel training framework that advances all soft labels for both positive and negative pairs, providing a more precise learning objective. Extensive experiments on Ego4D, EPIC-Kitchens-100, and Charades-Ego under zero-shot and fine-tuning settings demonstrate that EVA02-AT achieves state-of-the-art performance across diverse egocentric video-language tasks with fewer parameters. Models with our SMS loss also show significant performance gains on multi-instance retrieval benchmarks. Our code and models are publicly available at https://github.com/xqwang14/EVA02-AT .
AOLO: Analysis and Optimization For Low-Carbon Oriented Wireless Large Language Model Services
Mar 06, 2025Recent advancements in large language models (LLMs) have led to their widespread adoption and large-scale deployment across various domains. However, their environmental impact, particularly during inference, has become a growing concern due to their substantial energy consumption and carbon footprint. Existing research has focused on inference computation alone, overlooking the analysis and optimization of carbon footprint in network-aided LLM service systems. To address this gap, we propose AOLO, a framework for analysis and optimization for low-carbon oriented wireless LLM services. AOLO introduces a comprehensive carbon footprint model that quantifies greenhouse gas emissions across the entire LLM service chain, including computational inference and wireless communication. Furthermore, we formulate an optimization problem aimed at minimizing the overall carbon footprint, which is solved through joint optimization of inference outputs and transmit power under quality-of-experience and system performance constraints. To achieve this joint optimization, we leverage the energy efficiency of spiking neural networks (SNNs) by adopting SNN as the actor network and propose a low-carbon-oriented optimization algorithm, i.e., SNN-based deep reinforcement learning (SDRL). Comprehensive simulations demonstrate that SDRL algorithm significantly reduces overall carbon footprint, achieving an 18.77% reduction compared to the benchmark soft actor-critic, highlighting its potential for enabling more sustainable LLM inference services.
AdvDreamer Unveils: Are Vision-Language Models Truly Ready for Real-World 3D Variations?
Dec 04, 2024
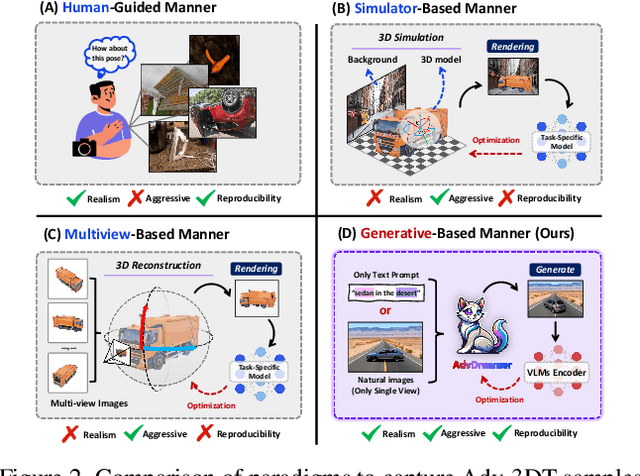
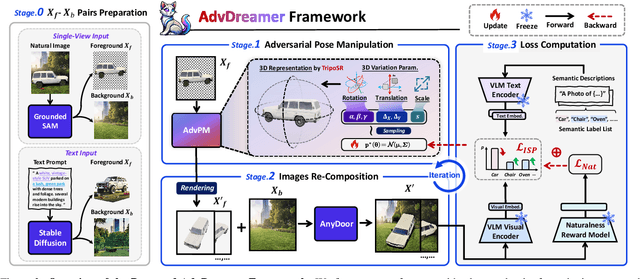
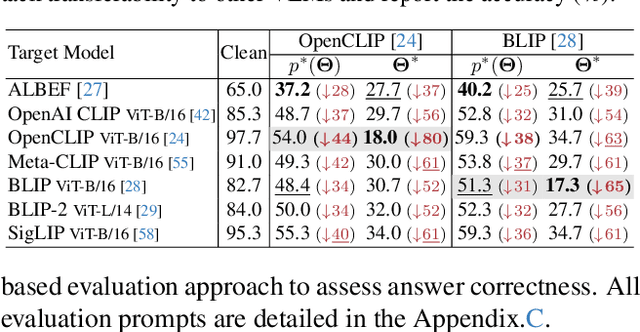
Vision Language Models (VLMs) have exhibited remarkable generalization capabilities, yet their robustness in dynamic real-world scenarios remains largely unexplored. To systematically evaluate VLMs' robustness to real-world 3D variations, we propose AdvDreamer, the first framework that generates physically reproducible adversarial 3D transformation (Adv-3DT) samples from single-view images. AdvDreamer integrates advanced generative techniques with two key innovations and aims to characterize the worst-case distributions of 3D variations from natural images. To ensure adversarial effectiveness and method generality, we introduce an Inverse Semantic Probability Objective that executes adversarial optimization on fundamental vision-text alignment spaces, which can be generalizable across different VLM architectures and downstream tasks. To mitigate the distribution discrepancy between generated and real-world samples while maintaining physical reproducibility, we design a Naturalness Reward Model that provides regularization feedback during adversarial optimization, preventing convergence towards hallucinated and unnatural elements. Leveraging AdvDreamer, we establish MM3DTBench, the first VQA dataset for benchmarking VLMs' 3D variations robustness. Extensive evaluations on representative VLMs with diverse architectures highlight that 3D variations in the real world may pose severe threats to model performance across various tasks.
DT-JRD: Deep Transformer based Just Recognizable Difference Prediction Model for Video Coding for Machines
Nov 14, 2024Just Recognizable Difference (JRD) represents the minimum visual difference that is detectable by machine vision, which can be exploited to promote machine vision oriented visual signal processing. In this paper, we propose a Deep Transformer based JRD (DT-JRD) prediction model for Video Coding for Machines (VCM), where the accurately predicted JRD can be used reduce the coding bit rate while maintaining the accuracy of machine tasks. Firstly, we model the JRD prediction as a multi-class classification and propose a DT-JRD prediction model that integrates an improved embedding, a content and distortion feature extraction, a multi-class classification and a novel learning strategy. Secondly, inspired by the perception property that machine vision exhibits a similar response to distortions near JRD, we propose an asymptotic JRD loss by using Gaussian Distribution-based Soft Labels (GDSL), which significantly extends the number of training labels and relaxes classification boundaries. Finally, we propose a DT-JRD based VCM to reduce the coding bits while maintaining the accuracy of object detection. Extensive experimental results demonstrate that the mean absolute error of the predicted JRD by the DT-JRD is 5.574, outperforming the state-of-the-art JRD prediction model by 13.1%. Coding experiments shows that comparing with the VVC, the DT-JRD based VCM achieves an average of 29.58% bit rate reduction while maintaining the object detection accuracy.
FedNE: Surrogate-Assisted Federated Neighbor Embedding for Dimensionality Reduction
Sep 17, 2024



Federated learning (FL) has rapidly evolved as a promising paradigm that enables collaborative model training across distributed participants without exchanging their local data. Despite its broad applications in fields such as computer vision, graph learning, and natural language processing, the development of a data projection model that can be effectively used to visualize data in the context of FL is crucial yet remains heavily under-explored. Neighbor embedding (NE) is an essential technique for visualizing complex high-dimensional data, but collaboratively learning a joint NE model is difficult. The key challenge lies in the objective function, as effective visualization algorithms like NE require computing loss functions among pairs of data. In this paper, we introduce \textsc{FedNE}, a novel approach that integrates the \textsc{FedAvg} framework with the contrastive NE technique, without any requirements of shareable data. To address the lack of inter-client repulsion which is crucial for the alignment in the global embedding space, we develop a surrogate loss function that each client learns and shares with each other. Additionally, we propose a data-mixing strategy to augment the local data, aiming to relax the problems of invisible neighbors and false neighbors constructed by the local $k$NN graphs. We conduct comprehensive experiments on both synthetic and real-world datasets. The results demonstrate that our \textsc{FedNE} can effectively preserve the neighborhood data structures and enhance the alignment in the global embedding space compared to several baseline methods.
Global-Local Progressive Integration Network for Blind Image Quality Assessment
Aug 07, 2024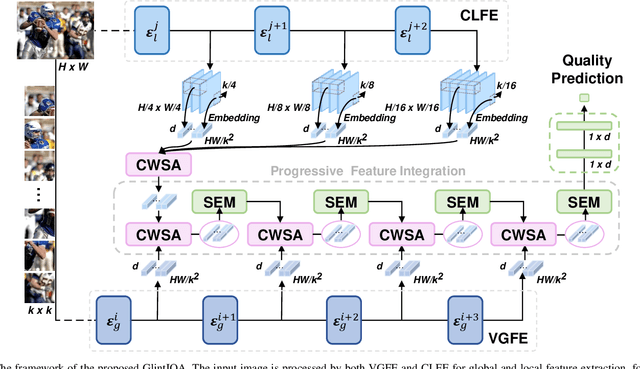
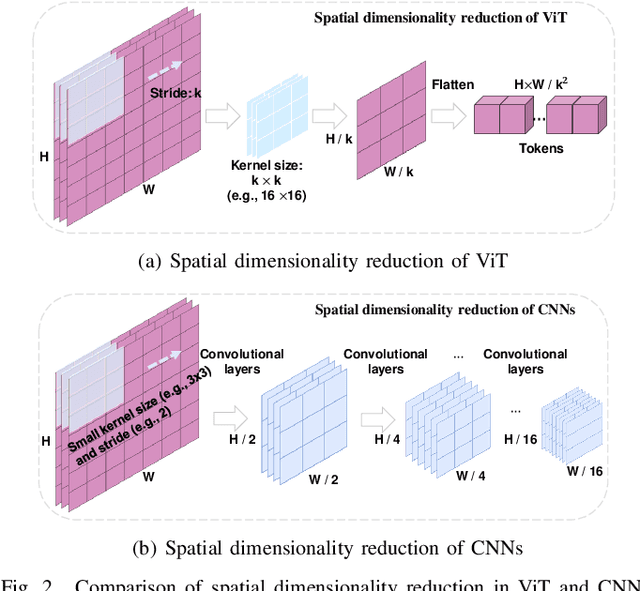
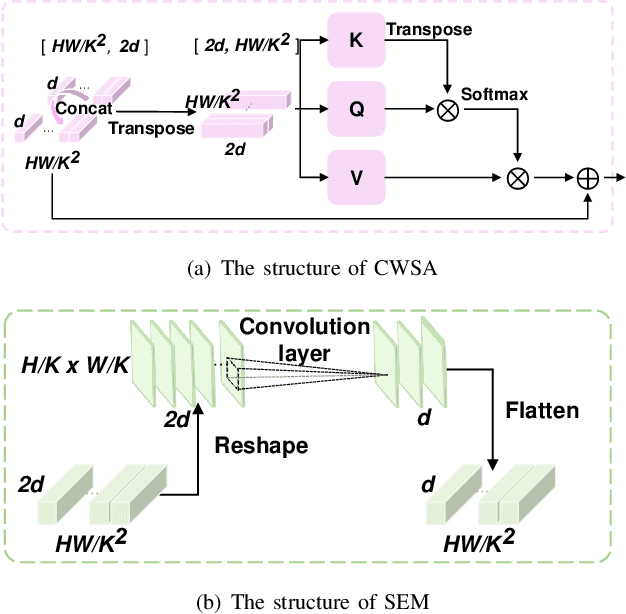
Vision transformers (ViTs) excel in computer vision for modeling long-term dependencies, yet face two key challenges for image quality assessment (IQA): discarding fine details during patch embedding, and requiring extensive training data due to lack of inductive biases. In this study, we propose a Global-Local progressive INTegration network for IQA, called GlintIQA, to address these issues through three key components: 1) Hybrid feature extraction combines ViT-based global feature extractor (VGFE) and convolutional neural networks (CNNs)-based local feature extractor (CLFE) to capture global coarse-grained features and local fine-grained features, respectively. The incorporation of CNNs mitigates the patch-level information loss and inductive bias constraints inherent to ViT architectures. 2) Progressive feature integration leverages diverse kernel sizes in embedding to spatially align coarse- and fine-grained features, and progressively aggregate these features by interactively stacking channel-wise attention and spatial enhancement modules to build effective quality-aware representations. 3) Content similarity-based labeling approach is proposed that automatically assigns quality labels to images with diverse content based on subjective quality scores. This addresses the scarcity of labeled training data in synthetic datasets and bolsters model generalization. The experimental results demonstrate the efficacy of our approach, yielding 5.04% average SROCC gains on cross-authentic dataset evaluations. Moreover, our model and its counterpart pre-trained on the proposed dataset respectively exhibited 5.40% and 13.23% improvements on across-synthetic datasets evaluation. The codes and proposed dataset will be released at https://github.com/XiaoqiWang/GlintIQA.
Symmetric Multi-Similarity Loss for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2024
Jun 18, 2024

In this report, we present our champion solution for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge in CVPR 2024. Essentially, this challenge differs from traditional visual-text retrieval tasks by providing a correlation matrix that acts as a set of soft labels for video-text clip combinations. However, existing loss functions have not fully exploited this information. Motivated by this, we propose a novel loss function, Symmetric Multi-Similarity Loss, which offers a more precise learning objective. Together with tricks and ensemble learning, the model achieves 63.76% average mAP and 74.25% average nDCG on the public leaderboard, demonstrating the effectiveness of our approach. Our code will be released at: https://github.com/xqwang14/SMS-Loss/tree/main
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
Regression-free Blind Image Quality Assessment
Jul 18, 2023



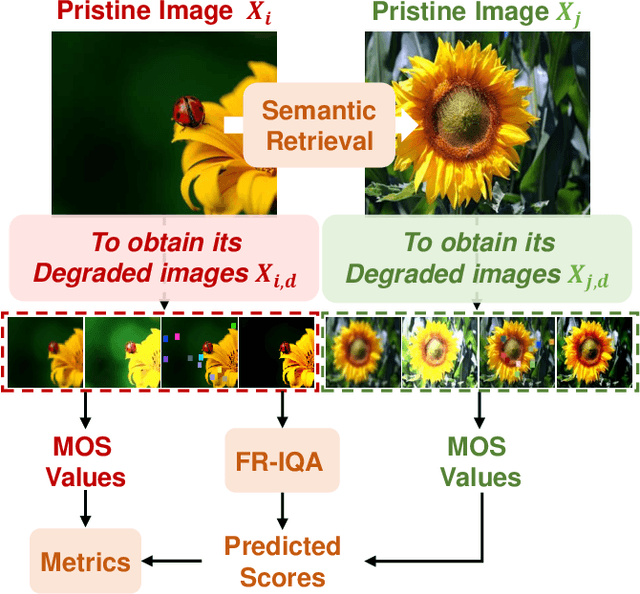
Regression-based blind image quality assessment (IQA) models are susceptible to biased training samples, leading to a biased estimation of model parameters. To mitigate this issue, we propose a regression-free framework for image quality evaluation, which is founded upon retrieving similar instances by incorporating semantic and distortion features. The motivation behind this approach is rooted in the observation that the human visual system (HVS) has analogous visual responses to semantically similar image contents degraded by the same distortion. The proposed framework comprises two classification-based modules: semantic-based classification (SC) module and distortion-based classification (DC) module. Given a test image and an IQA database, the SC module retrieves multiple pristine images based on semantic similarity. The DC module then retrieves instances based on distortion similarity from the distorted images that correspond to each retrieved pristine image. Finally, the predicted quality score is derived by aggregating the subjective quality scores of multiple retrieved instances. Experimental results on four benchmark databases validate that the proposed model can remarkably outperform the state-of-the-art regression-based models.