 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Progressive Integration Network for Blind Image Quality Assessment
Paper and Code
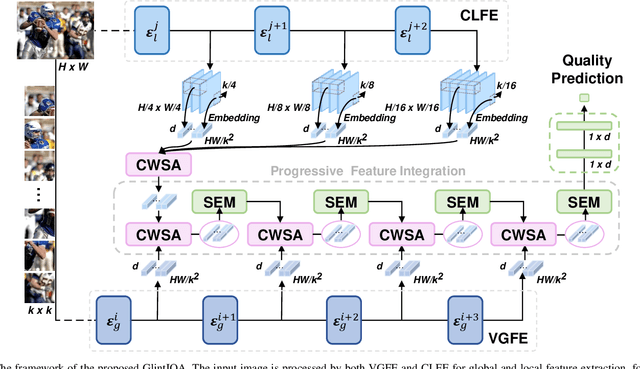
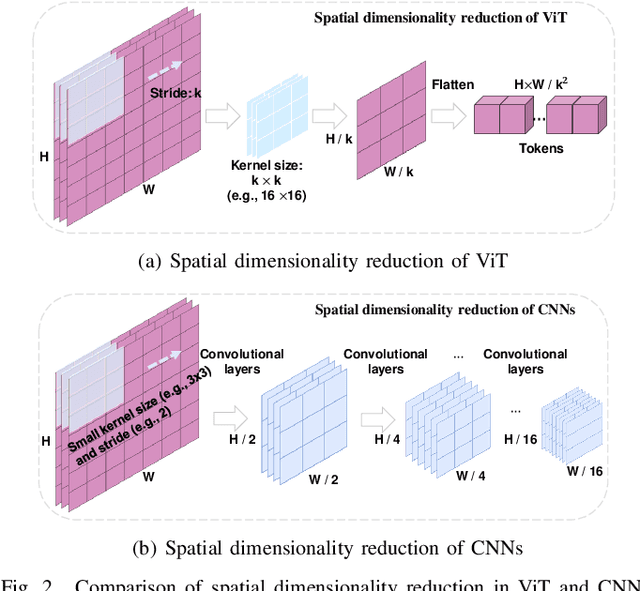
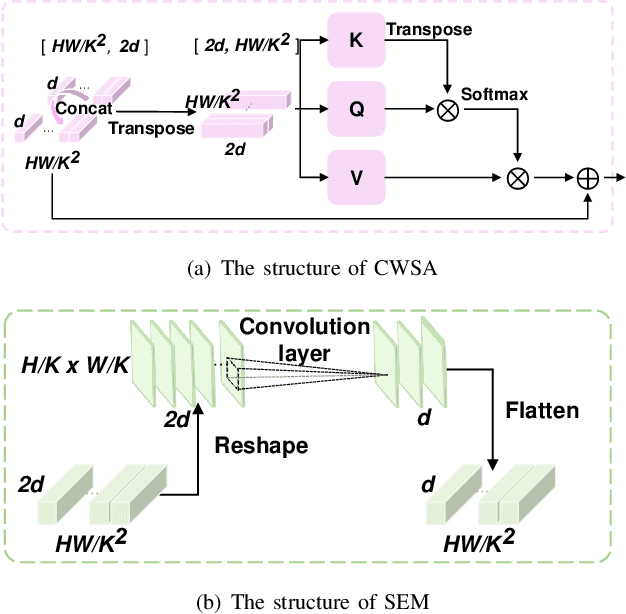
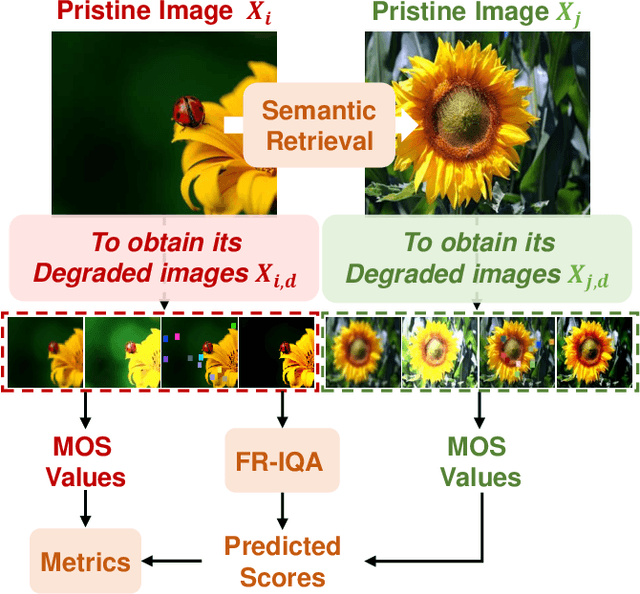
Vision transformers (ViTs) excel in computer vision for modeling long-term dependencies, yet face two key challenges for image quality assessment (IQA): discarding fine details during patch embedding, and requiring extensive training data due to lack of inductive biases. In this study, we propose a Global-Local progressive INTegration network for IQA, called GlintIQA, to address these issues through three key components: 1) Hybrid feature extraction combines ViT-based global feature extractor (VGFE) and convolutional neural networks (CNNs)-based local feature extractor (CLFE) to capture global coarse-grained features and local fine-grained features, respectively. The incorporation of CNNs mitigates the patch-level information loss and inductive bias constraints inherent to ViT architectures. 2) Progressive feature integration leverages diverse kernel sizes in embedding to spatially align coarse- and fine-grained features, and progressively aggregate these features by interactively stacking channel-wise attention and spatial enhancement modules to build effective quality-aware representations. 3) Content similarity-based labeling approach is proposed that automatically assigns quality labels to images with diverse content based on subjective quality scores. This addresses the scarcity of labeled training data in synthetic datasets and bolsters model generalization. The experimental results demonstrate the efficacy of our approach, yielding 5.04% average SROCC gains on cross-authentic dataset evaluations. Moreover, our model and its counterpart pre-trained on the proposed dataset respectively exhibited 5.40% and 13.23% improvements on across-synthetic datasets evaluation. The codes and proposed dataset will be released at https://github.com/XiaoqiWang/GlintIQA.