 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaST-Bench: Benchmarking Causal Chain-Grounded Spatio-Temporal Reasoning for Video Question Answering
May 22, 2026Cause-and-effect reasoning in video is a significant challenge for Vision-Language Models (VLMs), as it requires going beyond surface-level perception to a deeper understanding of causal mechanisms. However, existing benchmarks rarely provide the fine-grained, grounded evidence needed to rigorously evaluate this capability. To address this gap, we introduce CaST-Bench, a benchmark for Causal Chain-Grounded Spatio-Temporal Video Reasoning. CaST-Bench presents complex causal questions that require models to identify and localize a chain of multiple spatio-temporal evidences. Through a human-AI collaborative pipeline, we construct a high-quality dataset of 2,066 questions over 1,015 videos, with causal chains annotated by temporal segments and bounding-box tracks. Furthermore, we design a comprehensive evaluation suite with novel metrics that assess not only answer correctness but also the capability for visual evidence grounded reasoning. This grounding is crucial for improving accuracy by mitigating spurious correlations and for enhancing user trust by making models more transparent. Our experiments show that current VLMs struggle with causal questions, largely due to their limited ability to construct precise and grounded causal chains. This highlights an important direction for improving future VLMs.
Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?
May 21, 2026Multimodal Large Language Models (MLLMs) are increasingly deployed in human-facing roles where personality perception is critical, yet existing benchmarks evaluate this capability solely on numerical Big Five score prediction, leaving open whether models truly perceive personality through behavioral understanding or merely prejudge through superficial pattern matching. We address this gap with three contributions. (i) A new task: we formalize Grounded Personality Reasoning (GPR), which requires MLLMs to anchor each Big Five rating in observable evidence through a chain of rating, reasoning, and grounding. (ii) A new dataset: we release MM-OCEAN (1,104 videos, 5,320 MCQs), produced by a multi-agent pipeline with human verification, with timestamped behavioral observations, evidence-grounded trait analyses, and seven categories of cue-grounding MCQs. (iii) Benchmark and analysis: we design a three-tier evaluation (rating, reasoning, grounding) plus four sample-level failure-mode metrics: Prejudice Rate (PR), Confabulation Rate (CR), Integration-failure Rate (IR), and Holistic-grounding Rate (HR), and benchmark 27 MLLMs (13 closed, 14 open). The analysis uncovers a striking Prejudice Gap: across the field, 51% of correct ratings are not grounded in retrieved cues, and the Holistic-Grounding Rate spans only 0-33.5%. These findings expose a disconnect between getting the right score and reasoning for the right reason, charting a roadmap for grounded social cognition in MLLMs.
SocialDirector: Training-Free Social Interaction Control for Multi-Person Video Generation
May 11, 2026Video generation has advanced rapidly, producing photorealistic videos from text or image prompts. Meanwhile, film production and social robotics increasingly demand multi-person videos with rich social interactions, including conversations, gestures, and coordinated actions. However, existing models offer no explicit control over interactions, such as who performs which action, when it occurs, and toward whom it is directed. This often results in wrong person performing unintended actions (actor-action mismatch), disordered social dynamics, and wrong action targets. To address these challenges, we present SocialDirector, a training-free interaction controller that enhances the generation model by modulating cross-attention maps. SocialDirector contains two modules: Social Actor Masking and Directional Reweighting. Social Actor Masking constrains each person's visual tokens to attend only to their own textual descriptions via a spatiotemporal mask, avoiding actor-action mismatch and disordered social dynamics. Directional Reweighting amplifies attention to directional words (e.g., "leftward", "right"), leading each action towards its intended target. To evaluate generated social interactions, we annotate existing datasets with interaction descriptions and build a fully automated evaluation pipeline powered by open-source VLMs. Experiments on different video generation models show that SocialDirector significantly improves interaction fidelity and approaches the upper bound set by real videos.
SQuTR: A Robustness Benchmark for Spoken Query to Text Retrieval under Acoustic Noise
Feb 13, 2026Spoken query retrieval is an important interaction mode in modern information retrieval. However, existing evaluation datasets are often limited to simple queries under constrained noise conditions, making them inadequate for assessing the robustness of spoken query retrieval systems under complex acoustic perturbations. To address this limitation, we present SQuTR, a robustness benchmark for spoken query retrieval that includes a large-scale dataset and a unified evaluation protocol. SQuTR aggregates 37,317 unique queries from six commonly used English and Chinese text retrieval datasets, spanning multiple domains and diverse query types. We synthesize speech using voice profiles from 200 real speakers and mix 17 categories of real-world environmental noise under controlled SNR levels, enabling reproducible robustness evaluation from quiet to highly noisy conditions. Under the unified protocol, we conduct large-scale evaluations on representative cascaded and end-to-end retrieval systems. Experimental results show that retrieval performance decreases as noise increases, with substantially different drops across systems. Even large-scale retrieval models struggle under extreme noise, indicating that robustness remains a critical bottleneck. Overall, SQuTR provides a reproducible testbed for benchmarking and diagnostic analysis, and facilitates future research on robustness in spoken query to text retrieval.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Dec 08, 2025



We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.
Can MLLMs Read the Room? A Multimodal Benchmark for Verifying Truthfulness in Multi-Party Social Interactions
Oct 31, 2025As AI systems become increasingly integrated into human lives, endowing them with robust social intelligence has emerged as a critical frontier. A key aspect of this intelligence is discerning truth from deception, a ubiquitous element of human interaction that is conveyed through a complex interplay of verbal language and non-verbal visual cues. However, automatic deception detection in dynamic, multi-party conversations remains a significant challenge. The recent rise of powerful Multimodal Large Language Models (MLLMs), with their impressive abilities in visual and textual understanding, makes them natural candidates for this task. Consequently, their capabilities in this crucial domain are mostly unquantified. To address this gap, we introduce a new task, Multimodal Interactive Veracity Assessment (MIVA), and present a novel multimodal dataset derived from the social deduction game Werewolf. This dataset provides synchronized video, text, with verifiable ground-truth labels for every statement. We establish a comprehensive benchmark evaluating state-of-the-art MLLMs, revealing a significant performance gap: even powerful models like GPT-4o struggle to distinguish truth from falsehood reliably. Our analysis of failure modes indicates that these models fail to ground language in visual social cues effectively and may be overly conservative in their alignment, highlighting the urgent need for novel approaches to building more perceptive and trustworthy AI systems.
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
Aug 24, 2025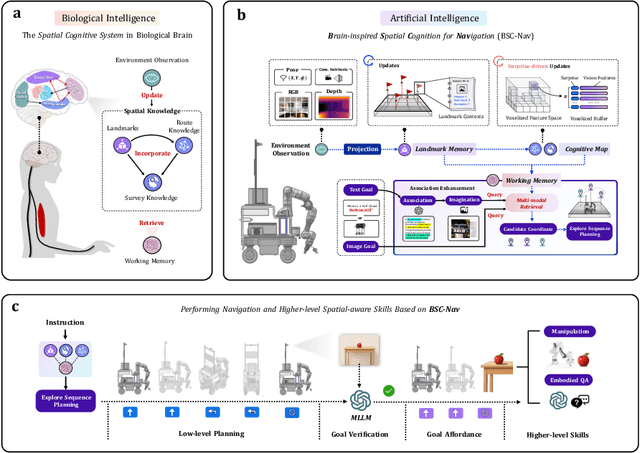
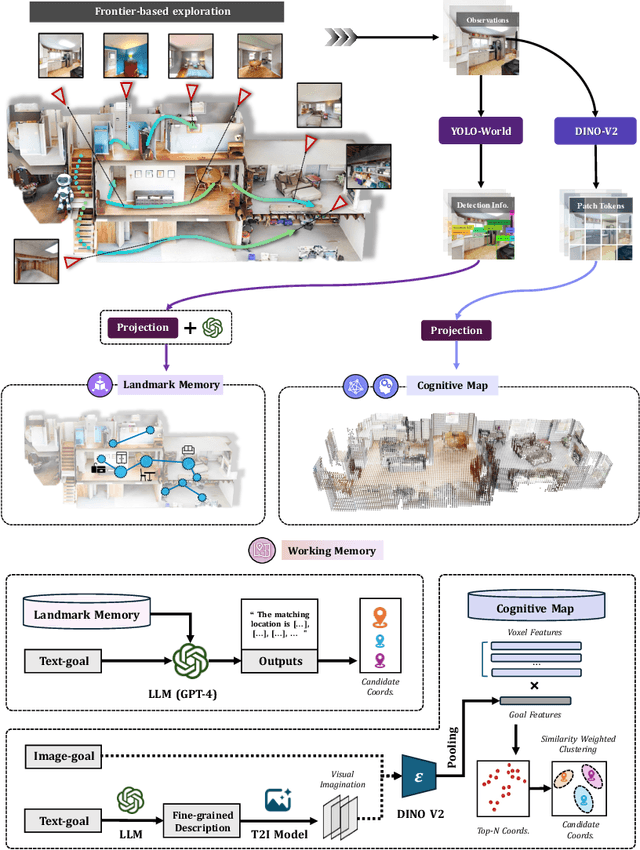
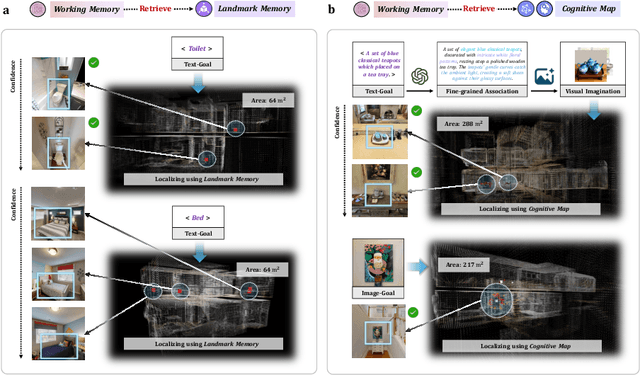
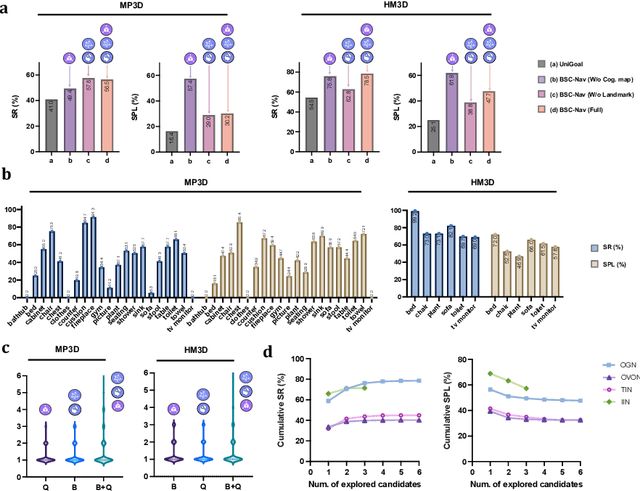
Spatial cognition enables adaptive goal-directed behavior by constructing internal models of space. Robust biological systems consolidate spatial knowledge into three interconnected forms: \textit{landmarks} for salient cues, \textit{route knowledge} for movement trajectories, and \textit{survey knowledge} for map-like representations. While recent advances in multi-modal large language models (MLLMs) have enabled visual-language reasoning in embodied agents, these efforts lack structured spatial memory and instead operate reactively, limiting their generalization and adaptability in complex real-world environments. Here we present Brain-inspired Spatial Cognition for Navigation (BSC-Nav), a unified framework for constructing and leveraging structured spatial memory in embodied agents. BSC-Nav builds allocentric cognitive maps from egocentric trajectories and contextual cues, and dynamically retrieves spatial knowledge aligned with semantic goals. Integrated with powerful MLLMs, BSC-Nav achieves state-of-the-art efficacy and efficiency across diverse navigation tasks, demonstrates strong zero-shot generalization, and supports versatile embodied behaviors in the real physical world, offering a scalable and biologically grounded path toward general-purpose spatial intelligence.
Towards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Apr 19, 2025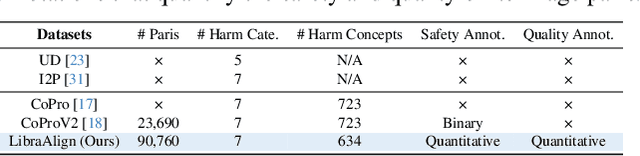
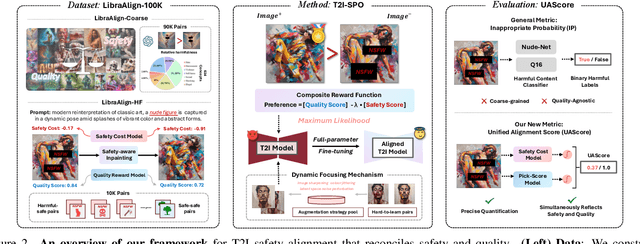
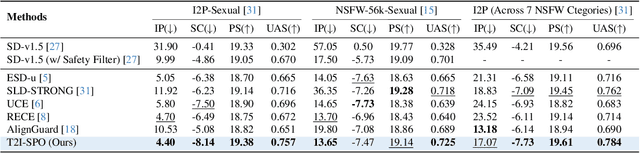
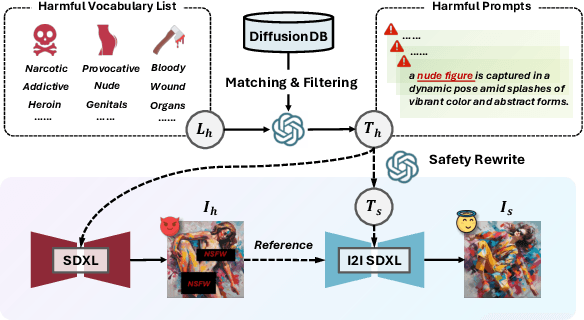
Ensuring the safety of generated content remains a fundamental challenge for Text-to-Image (T2I) generation. Existing studies either fail to guarantee complete safety under potentially harmful concepts or struggle to balance safety with generation quality. To address these issues, we propose Safety-Constrained Direct Preference Optimization (SC-DPO), a novel framework for safety alignment in T2I models. SC-DPO integrates safety constraints into the general human preference calibration, aiming to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs. In SC-DPO, we introduce a safety cost model to accurately quantify harmful levels for images, and train it effectively using the proposed contrastive learning and cost anchoring objectives. To apply SC-DPO for effective T2I safety alignment, we constructed SCP-10K, a safety-constrained preference dataset containing rich harmful concepts, which blends safety-constrained preference pairs under both harmful and clean instructions, further mitigating the trade-off between safety and sample quality. Additionally, we propose a Dynamic Focusing Mechanism (DFM) for SC-DPO, promoting the model's learning of difficult preference pair samples. Extensive experiments demonstrate that SC-DPO outperforms existing methods, effectively defending against various NSFW content while maintaining optimal sample quality and human preference alignment. Additionally, SC-DPO exhibits resilience against adversarial prompts designed to generate harmful content.
Jailbreaking Multimodal Large Language Models via Shuffle Inconsistency
Jan 09, 2025



Multimodal Large Language Models (MLLMs) have achieved impressive performance and have been put into practical use in commercial applications, but they still have potential safety mechanism vulnerabilities. Jailbreak attacks are red teaming methods that aim to bypass safety mechanisms and discover MLLMs' potential risks. Existing MLLMs' jailbreak methods often bypass the model's safety mechanism through complex optimization methods or carefully designed image and text prompts. Despite achieving some progress, they have a low attack success rate on commercial closed-source MLLMs. Unlike previous research, we empirically find that there exists a Shuffle Inconsistency between MLLMs' comprehension ability and safety ability for the shuffled harmful instruction. That is, from the perspective of comprehension ability, MLLMs can understand the shuffled harmful text-image instructions well. However, they can be easily bypassed by the shuffled harmful instructions from the perspective of safety ability, leading to harmful responses. Then we innovatively propose a text-image jailbreak attack named SI-Attack. Specifically, to fully utilize the Shuffle Inconsistency and overcome the shuffle randomness, we apply a query-based black-box optimization method to select the most harmful shuffled inputs based on the feedback of the toxic judge model. A series of experiments show that SI-Attack can improve the attack's performance on three benchmarks. In particular, SI-Attack can obviously improve the attack success rate for commercial MLLMs such as GPT-4o or Claude-3.5-Sonnet.