 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Adversarial Training for Infrared Object Detection via Thermal Radiation Modeling
Mar 26, 2026In complex environments, infrared object detection exhibits broad applicability and stability across diverse scenarios. However, infrared object detection is vulnerable to both common corruptions and adversarial examples, leading to potential security risks. To improve the robustness of infrared object detection, current methods mostly adopt a data-driven ideology, which only superficially drives the network to fit the training data without specifically considering the unique characteristics of infrared images, resulting in limited robustness. In this paper, we revisit infrared physical knowledge and find that relative thermal radiation relations between different classes can be regarded as a reliable knowledge source under the complex scenarios of adversarial examples and common corruptions. Thus, we theoretically model thermal radiation relations based on the rank order of gray values for different classes, and further quantify the stability of various inter-class thermal radiation relations. Based on the above theoretical framework, we propose Knowledge-Guided Adversarial Training (KGAT) for infrared object detection, in which infrared physical knowledge is embedded into the adversarial training process, and the predicted results are optimized to be consistent with the actual physical laws. Extensive experiments on three infrared datasets and six mainstream infrared object detection models demonstrate that KGAT effectively enhances both clean accuracy and robustness against adversarial attacks and common corruptions.
Improving Safety Alignment via Balanced Direct Preference Optimization
Mar 24, 2026With the rapid development and widespread application of Large Language Models (LLMs), their potential safety risks have attracted widespread attention. Reinforcement Learning from Human Feedback (RLHF) has been adopted to enhance the safety performance of LLMs. As a simple and effective alternative to RLHF, Direct Preference Optimization (DPO) is widely used for safety alignment. However, safety alignment still suffers from severe overfitting, which limits its actual performance. This paper revisits the overfitting phenomenon from the perspective of the model's comprehension of the training data. We find that the Imbalanced Preference Comprehension phenomenon exists between responses in preference pairs, which compromises the model's safety performance. To address this, we propose Balanced Direct Preference Optimization (B-DPO), which adaptively modulates optimization strength between preferred and dispreferred responses based on mutual information. A series of experimental results show that B-DPO can enhance the safety capability while maintaining the competitive general capabilities of LLMs on various mainstream benchmarks compared to state-of-the-art methods. \color{red}{Warning: This paper contains examples of harmful texts, and reader discretion is recommended.
Mind over Space: Can Multimodal Large Language Models Mentally Navigate?
Mar 23, 2026Despite the widespread adoption of MLLMs in embodied agents, their capabilities remain largely confined to reactive planning from immediate observations, consistently failing in spatial reasoning across extensive spatiotemporal scales. Cognitive science reveals that Biological Intelligence (BI) thrives on "mental navigation": the strategic construction of spatial representations from experience and the subsequent mental simulation of paths prior to action. To bridge the gap between AI and BI, we introduce Video2Mental, a pioneering benchmark for evaluating the mental navigation capabilities of MLLMs. The task requires constructing hierarchical cognitive maps from long egocentric videos and generating landmark-based path plans step by step, with planning accuracy verified through simulator-based physical interaction. Our benchmarking results reveal that mental navigation capability does not naturally emerge from standard pre-training. Frontier MLLMs struggle profoundly with zero-shot structured spatial representation, and their planning accuracy decays precipitously over extended horizons. To overcome this, we propose \textbf{NavMind}, a reasoning model that internalizes mental navigation using explicit, fine-grained cognitive maps as learnable intermediate representations. Through a difficulty-stratified progressive supervised fine-tuning paradigm, NavMind effectively bridges the gap between raw perception and structured planning. Experiments demonstrate that NavMind achieves superior mental navigation capabilities, significantly outperforming frontier commercial and spatial MLLMs.
NS-FPN: Improving Infrared Small Target Detection and Segmentation from Noise Suppression Perspective
Aug 09, 2025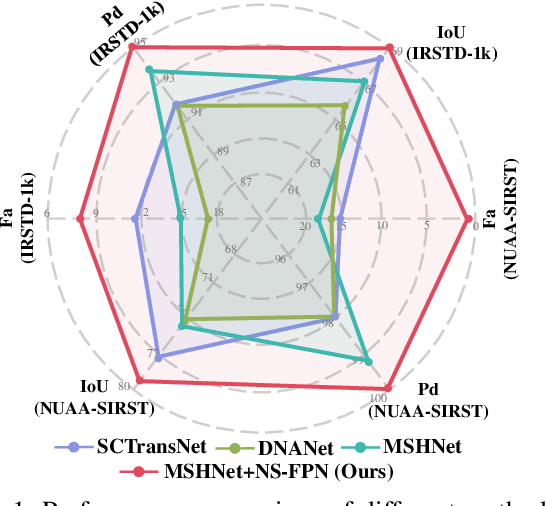

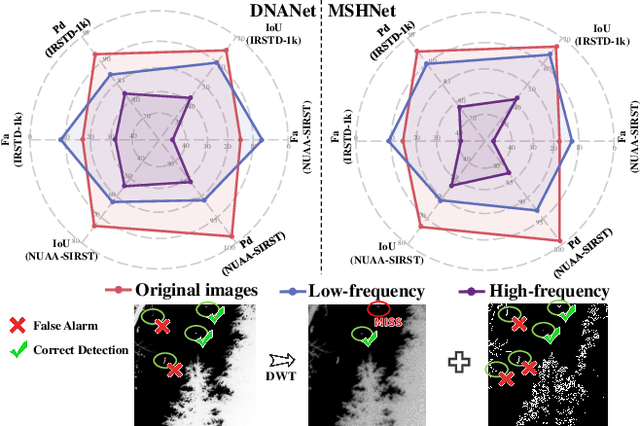
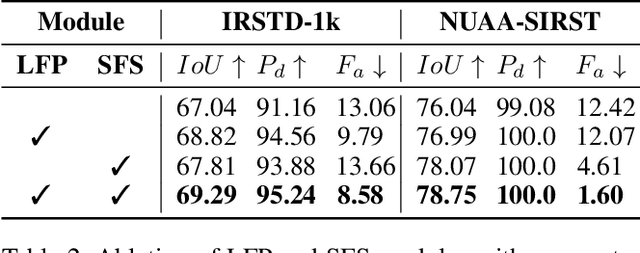
Infrared small target detection and segmentation (IRSTDS) is a critical yet challenging task in defense and civilian applications, owing to the dim, shapeless appearance of targets and severe background clutter. Recent CNN-based methods have achieved promising target perception results, but they only focus on enhancing feature representation to offset the impact of noise, which results in the increased false alarms problem. In this paper, through analyzing the problem from the frequency domain, we pioneer in improving performance from noise suppression perspective and propose a novel noise-suppression feature pyramid network (NS-FPN), which integrates a low-frequency guided feature purification (LFP) module and a spiral-aware feature sampling (SFS) module into the original FPN structure. The LFP module suppresses the noise features by purifying high-frequency components to achieve feature enhancement devoid of noise interference, while the SFS module further adopts spiral sampling to fuse target-relevant features in feature fusion process. Our NS-FPN is designed to be lightweight yet effective and can be easily plugged into existing IRSTDS frameworks. Extensive experiments on the public IRSTDS datasets demonstrate that our method significantly reduces false alarms and achieves superior performance on IRSTDS tasks.
Towards Class-wise Fair Adversarial Training via Anti-Bias Soft Label Distillation
Jun 10, 2025Adversarial Training (AT) is widely recognized as an effective approach to enhance the adversarial robustness of Deep Neural Networks. As a variant of AT, Adversarial Robustness Distillation (ARD) has shown outstanding performance in enhancing the robustness of small models. However, both AT and ARD face robust fairness issue: these models tend to display strong adversarial robustness against some classes (easy classes) while demonstrating weak adversarial robustness against others (hard classes). This paper explores the underlying factors of this problem and points out the smoothness degree of soft labels for different classes significantly impacts the robust fairness from both empirical observation and theoretical analysis. Based on the above exploration, we propose Anti-Bias Soft Label Distillation (ABSLD) within the Knowledge Distillation framework to enhance the adversarial robust fairness. Specifically, ABSLD adaptively reduces the student's error risk gap between different classes, which is accomplished by adjusting the class-wise smoothness degree of teacher's soft labels during the training process, and the adjustment is managed by assigning varying temperatures to different classes. Additionally, as a label-based approach, ABSLD is highly adaptable and can be integrated with the sample-based methods. Extensive experiments demonstrate ABSLD outperforms state-of-the-art methods on the comprehensive performance of robustness and fairness.
Enhancing Adversarial Robustness of Vision Language Models via Adversarial Mixture Prompt Tuning
May 23, 2025Large pre-trained Vision Language Models (VLMs) have excellent generalization capabilities but are highly susceptible to adversarial examples, presenting potential security risks. To improve the robustness of VLMs against adversarial examples, adversarial prompt tuning methods are proposed to align the text feature with the adversarial image feature without changing model parameters. However, when facing various adversarial attacks, a single learnable text prompt has insufficient generalization to align well with all adversarial image features, which finally leads to the overfitting phenomenon. To address the above challenge, in this paper, we empirically find that increasing the number of learned prompts can bring more robustness improvement than a longer prompt. Then we propose an adversarial tuning method named Adversarial Mixture Prompt Tuning (AMPT) to enhance the generalization towards various adversarial attacks for VLMs. AMPT aims to learn mixture text prompts to obtain more robust text features. To further enhance the adaptability, we propose a conditional weight router based on the input adversarial image to predict the mixture weights of multiple learned prompts, which helps obtain sample-specific aggregated text features aligning with different adversarial image features. A series of experiments show that our method can achieve better adversarial robustness than state-of-the-art methods on 11 datasets under different experimental settings.
When Lighting Deceives: Exposing Vision-Language Models' Illumination Vulnerability Through Illumination Transformation Attack
Mar 10, 2025



Vision-Language Models (VLMs) have achieved remarkable success in various tasks, yet their robustness to real-world illumination variations remains largely unexplored. To bridge this gap, we propose \textbf{I}llumination \textbf{T}ransformation \textbf{A}ttack (\textbf{ITA}), the first framework to systematically assess VLMs' robustness against illumination changes. However, there still exist two key challenges: (1) how to model global illumination with fine-grained control to achieve diverse lighting conditions and (2) how to ensure adversarial effectiveness while maintaining naturalness. To address the first challenge, we innovatively decompose global illumination into multiple parameterized point light sources based on the illumination rendering equation. This design enables us to model more diverse lighting variations that previous methods could not capture. Then, by integrating these parameterized lighting variations with physics-based lighting reconstruction techniques, we could precisely render such light interactions in the original scenes, finally meeting the goal of fine-grained lighting control. For the second challenge, by controlling illumination through the lighting reconstrution model's latent space rather than direct pixel manipulation, we inherently preserve physical lighting priors. Furthermore, to prevent potential reconstruction artifacts, we design additional perceptual constraints for maintaining visual consistency with original images and diversity constraints for avoiding light source convergence. Extensive experiments demonstrate that our ITA could significantly reduce the performance of advanced VLMs, e.g., LLaVA-1.6, while possessing competitive naturalness, exposing VLMS' critical illuminiation vulnerabilities.
Jailbreaking Multimodal Large Language Models via Shuffle Inconsistency
Jan 09, 2025



Multimodal Large Language Models (MLLMs) have achieved impressive performance and have been put into practical use in commercial applications, but they still have potential safety mechanism vulnerabilities. Jailbreak attacks are red teaming methods that aim to bypass safety mechanisms and discover MLLMs' potential risks. Existing MLLMs' jailbreak methods often bypass the model's safety mechanism through complex optimization methods or carefully designed image and text prompts. Despite achieving some progress, they have a low attack success rate on commercial closed-source MLLMs. Unlike previous research, we empirically find that there exists a Shuffle Inconsistency between MLLMs' comprehension ability and safety ability for the shuffled harmful instruction. That is, from the perspective of comprehension ability, MLLMs can understand the shuffled harmful text-image instructions well. However, they can be easily bypassed by the shuffled harmful instructions from the perspective of safety ability, leading to harmful responses. Then we innovatively propose a text-image jailbreak attack named SI-Attack. Specifically, to fully utilize the Shuffle Inconsistency and overcome the shuffle randomness, we apply a query-based black-box optimization method to select the most harmful shuffled inputs based on the feedback of the toxic judge model. A series of experiments show that SI-Attack can improve the attack's performance on three benchmarks. In particular, SI-Attack can obviously improve the attack success rate for commercial MLLMs such as GPT-4o or Claude-3.5-Sonnet.
OODFace: Benchmarking Robustness of Face Recognition under Common Corruptions and Appearance Variations
Dec 03, 2024



With the rise of deep learning, facial recognition technology has seen extensive research and rapid development. Although facial recognition is considered a mature technology, we find that existing open-source models and commercial algorithms lack robustness in certain real-world Out-of-Distribution (OOD) scenarios, raising concerns about the reliability of these systems. In this paper, we introduce OODFace, which explores the OOD challenges faced by facial recognition models from two perspectives: common corruptions and appearance variations. We systematically design 30 OOD scenarios across 9 major categories tailored for facial recognition. By simulating these challenges on public datasets, we establish three robustness benchmarks: LFW-C/V, CFP-FP-C/V, and YTF-C/V. We then conduct extensive experiments on 19 different facial recognition models and 3 commercial APIs, along with extended experiments on face masks, Vision-Language Models (VLMs), and defense strategies to assess their robustness. Based on the results, we draw several key insights, highlighting the vulnerability of facial recognition systems to OOD data and suggesting possible solutions. Additionally, we offer a unified toolkit that includes all corruption and variation types, easily extendable to other datasets. We hope that our benchmarks and findings can provide guidance for future improvements in facial recognition model robustness.
Improving Adversarial Robust Fairness via Anti-Bias Soft Label Distillation
Dec 09, 2023
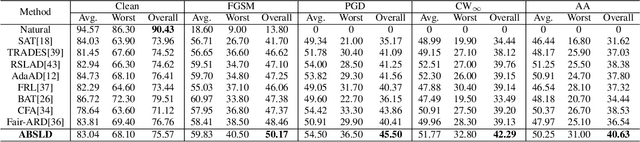


Adversarial Training (AT) has been widely proved to be an effective method to improve the adversarial robustness against adversarial examples for Deep Neural Networks (DNNs). As a variant of AT, Adversarial Robustness Distillation (ARD) has demonstrated its superior performance in improving the robustness of small student models with the guidance of large teacher models. However, both AT and ARD encounter the robust fairness problem: these models exhibit strong robustness when facing part of classes (easy class), but weak robustness when facing others (hard class). In this paper, we give an in-depth analysis of the potential factors and argue that the smoothness degree of samples' soft labels for different classes (i.e., hard class or easy class) will affect the robust fairness of DNN models from both empirical observation and theoretical analysis. Based on the above finding, we propose an Anti-Bias Soft Label Distillation (ABSLD) method to mitigate the adversarial robust fairness problem within the framework of Knowledge Distillation (KD). Specifically, ABSLD adaptively reduces the student's error risk gap between different classes to achieve fairness by adjusting the class-wise smoothness degree of samples' soft labels during the training process, and the smoothness degree of soft labels is controlled by assigning different temperatures in KD to different classes. Extensive experiments demonstrate that ABSLD outperforms state-of-the-art AT, ARD, and robust fairness methods in terms of overall performance of robustness and fairness.