 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Adversarial Training for Infrared Object Detection via Thermal Radiation Modeling
Mar 26, 2026In complex environments, infrared object detection exhibits broad applicability and stability across diverse scenarios. However, infrared object detection is vulnerable to both common corruptions and adversarial examples, leading to potential security risks. To improve the robustness of infrared object detection, current methods mostly adopt a data-driven ideology, which only superficially drives the network to fit the training data without specifically considering the unique characteristics of infrared images, resulting in limited robustness. In this paper, we revisit infrared physical knowledge and find that relative thermal radiation relations between different classes can be regarded as a reliable knowledge source under the complex scenarios of adversarial examples and common corruptions. Thus, we theoretically model thermal radiation relations based on the rank order of gray values for different classes, and further quantify the stability of various inter-class thermal radiation relations. Based on the above theoretical framework, we propose Knowledge-Guided Adversarial Training (KGAT) for infrared object detection, in which infrared physical knowledge is embedded into the adversarial training process, and the predicted results are optimized to be consistent with the actual physical laws. Extensive experiments on three infrared datasets and six mainstream infrared object detection models demonstrate that KGAT effectively enhances both clean accuracy and robustness against adversarial attacks and common corruptions.
Breaking Self-Attention Failure: Rethinking Query Initialization for Infrared Small Target Detection
Jan 06, 2026Infrared small target detection (IRSTD) faces significant challenges due to the low signal-to-noise ratio (SNR), small target size, and complex cluttered backgrounds. Although recent DETR-based detectors benefit from global context modeling, they exhibit notable performance degradation on IRSTD. We revisit this phenomenon and reveal that the target-relevant embeddings of IRST are inevitably overwhelmed by dominant background features due to the self-attention mechanism, leading to unreliable query initialization and inaccurate target localization. To address this issue, we propose SEF-DETR, a novel framework that refines query initialization for IRSTD. Specifically, SEF-DETR consists of three components: Frequency-guided Patch Screening (FPS), Dynamic Embedding Enhancement (DEE), and Reliability-Consistency-aware Fusion (RCF). The FPS module leverages the Fourier spectrum of local patches to construct a target-relevant density map, suppressing background-dominated features. DEE strengthens multi-scale representations in a target-aware manner, while RCF further refines object queries by enforcing spatial-frequency consistency and reliability. Extensive experiments on three public IRSTD datasets demonstrate that SEF-DETR achieves superior detection performance compared to state-of-the-art methods, delivering a robust and efficient solution for infrared small target detection task.
RGBT-Ground Benchmark: Visual Grounding Beyond RGB in Complex Real-World Scenarios
Dec 31, 2025Visual Grounding (VG) aims to localize specific objects in an image according to natural language expressions, serving as a fundamental task in vision-language understanding. However, existing VG benchmarks are mostly derived from datasets collected under clean environments, such as COCO, where scene diversity is limited. Consequently, they fail to reflect the complexity of real-world conditions, such as changes in illumination, weather, etc., that are critical to evaluating model robustness and generalization in safety-critical applications. To address these limitations, we present RGBT-Ground, the first large-scale visual grounding benchmark built for complex real-world scenarios. It consists of spatially aligned RGB and Thermal infrared (TIR) image pairs with high-quality referring expressions, corresponding object bounding boxes, and fine-grained annotations at the scene, environment, and object levels. This benchmark enables comprehensive evaluation and facilitates the study of robust grounding under diverse and challenging conditions. Furthermore, we establish a unified visual grounding framework that supports both uni-modal (RGB or TIR) and multi-modal (RGB-TIR) visual inputs. Based on it, we propose RGBT-VGNet, a simple yet effective baseline for fusing complementary visual modalities to achieve robust grounding. We conduct extensive adaptations to the existing methods on RGBT-Ground. Experimental results show that our proposed RGBT-VGNet significantly outperforms these adapted methods, particularly in nighttime and long-distance scenarios. All resources will be publicly released to promote future research on robust visual grounding in complex real-world environments.
NS-FPN: Improving Infrared Small Target Detection and Segmentation from Noise Suppression Perspective
Aug 09, 2025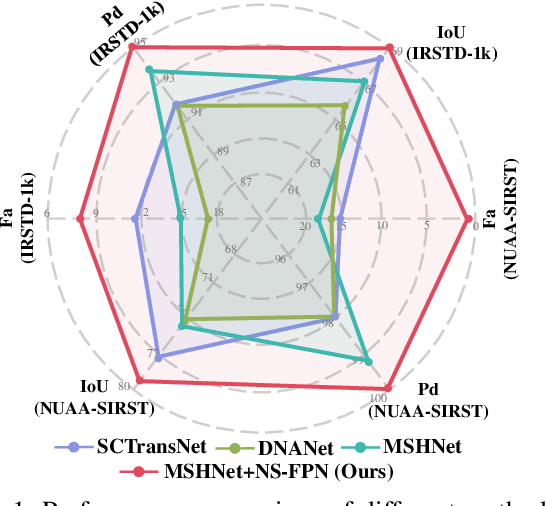

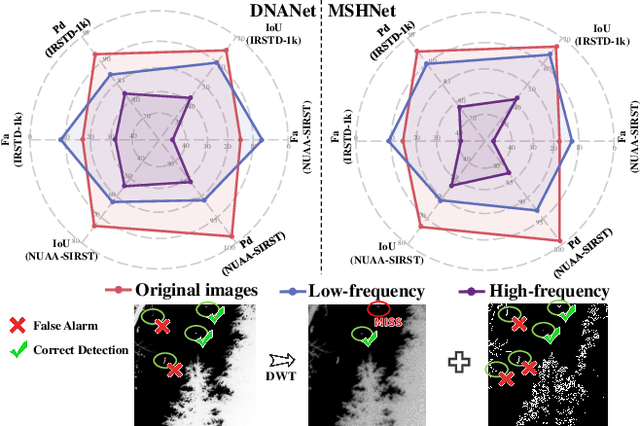
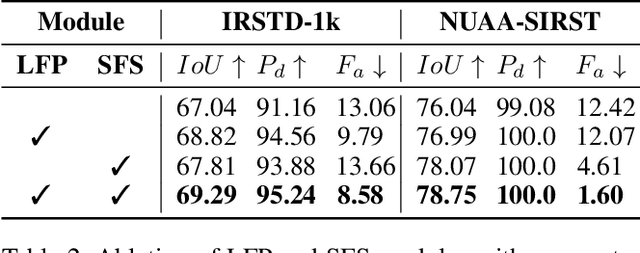
Infrared small target detection and segmentation (IRSTDS) is a critical yet challenging task in defense and civilian applications, owing to the dim, shapeless appearance of targets and severe background clutter. Recent CNN-based methods have achieved promising target perception results, but they only focus on enhancing feature representation to offset the impact of noise, which results in the increased false alarms problem. In this paper, through analyzing the problem from the frequency domain, we pioneer in improving performance from noise suppression perspective and propose a novel noise-suppression feature pyramid network (NS-FPN), which integrates a low-frequency guided feature purification (LFP) module and a spiral-aware feature sampling (SFS) module into the original FPN structure. The LFP module suppresses the noise features by purifying high-frequency components to achieve feature enhancement devoid of noise interference, while the SFS module further adopts spiral sampling to fuse target-relevant features in feature fusion process. Our NS-FPN is designed to be lightweight yet effective and can be easily plugged into existing IRSTDS frameworks. Extensive experiments on the public IRSTDS datasets demonstrate that our method significantly reduces false alarms and achieves superior performance on IRSTDS tasks.
Rethinking Multi-modal Object Detection from the Perspective of Mono-Modality Feature Learning
Mar 14, 2025Multi-Modal Object Detection (MMOD), due to its stronger adaptability to various complex environments, has been widely applied in various applications. Extensive research is dedicated to the RGB-IR object detection, primarily focusing on how to integrate complementary features from RGB-IR modalities. However, they neglect the mono-modality insufficient learning problem that the decreased feature extraction capability in multi-modal joint learning. This leads to an unreasonable but prevalent phenomenon--Fusion Degradation, which hinders the performance improvement of the MMOD model. Motivated by this, in this paper, we introduce linear probing evaluation to the multi-modal detectors and rethink the multi-modal object detection task from the mono-modality learning perspective. Therefore, we construct an novel framework called M$^2$D-LIF, which consists of the Mono-Modality Distillation (M$^2$D) method and the Local Illumination-aware Fusion (LIF) module. The M$^2$D-LIF framework facilitates the sufficient learning of mono-modality during multi-modal joint training and explores a lightweight yet effective feature fusion manner to achieve superior object detection performance. Extensive experiments conducted on three MMOD datasets demonstrate that our M$^2$D-LIF effectively mitigates the Fusion Degradation phenomenon and outperforms the previous SOTA detectors.
SFDFusion: An Efficient Spatial-Frequency Domain Fusion Network for Infrared and Visible Image Fusion
Oct 30, 2024
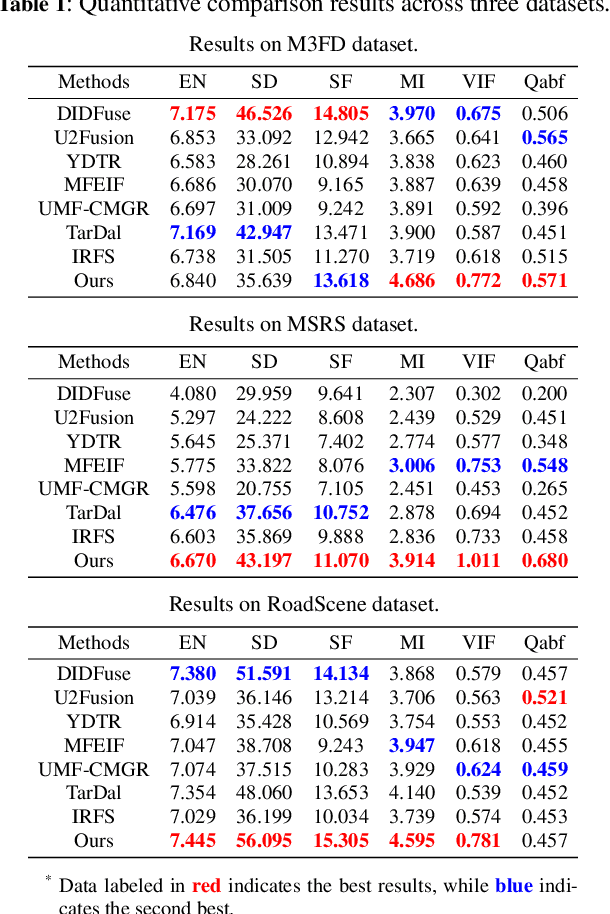


Infrared and visible image fusion aims to utilize the complementary information from two modalities to generate fused images with prominent targets and rich texture details. Most existing algorithms only perform pixel-level or feature-level fusion from different modalities in the spatial domain. They usually overlook the information in the frequency domain, and some of them suffer from inefficiency due to excessively complex structures. To tackle these challenges, this paper proposes an efficient Spatial-Frequency Domain Fusion (SFDFusion) network for infrared and visible image fusion. First, we propose a Dual-Modality Refinement Module (DMRM) to extract complementary information. This module extracts useful information from both the infrared and visible modalities in the spatial domain and enhances fine-grained spatial details. Next, to introduce frequency domain information, we construct a Frequency Domain Fusion Module (FDFM) that transforms the spatial domain to the frequency domain through Fast Fourier Transform (FFT) and then integrates frequency domain information. Additionally, we design a frequency domain fusion loss to provide guidance for the fusion process. Extensive experiments on public datasets demonstrate that our method produces fused images with significant advantages in various fusion metrics and visual effects. Furthermore, our method demonstrates high efficiency in image fusion and good performance on downstream detection tasks, thereby satisfying the real-time demands of advanced visual tasks.
UniRGB-IR: A Unified Framework for Visible-Infrared Downstream Tasks via Adapter Tuning
Apr 26, 2024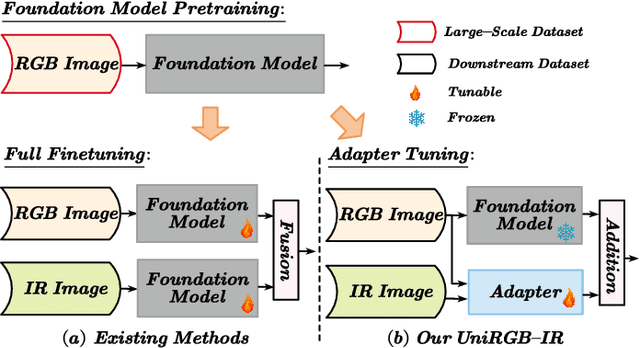

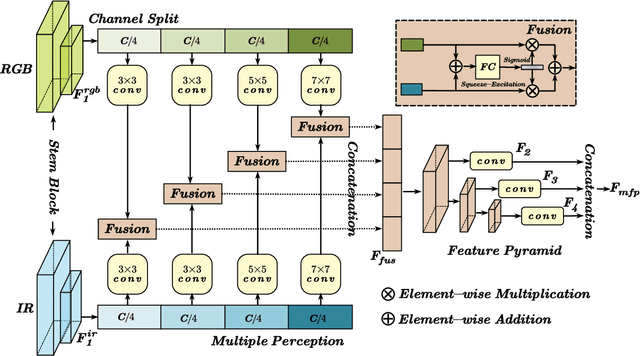
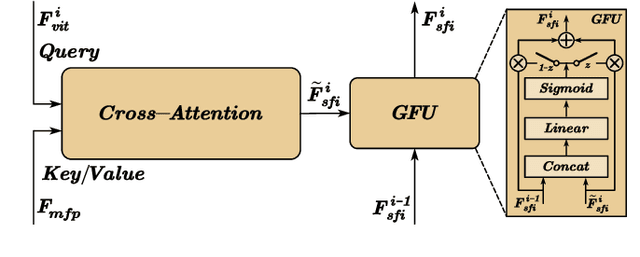
Semantic analysis on visible (RGB) and infrared (IR) images has gained attention for its ability to be more accurate and robust under low-illumination and complex weather conditions. Due to the lack of pre-trained foundation models on the large-scale infrared image datasets, existing methods prefer to design task-specific frameworks and directly fine-tune them with pre-trained foundation models on their RGB-IR semantic relevance datasets, which results in poor scalability and limited generalization. In this work, we propose a scalable and efficient framework called UniRGB-IR to unify RGB-IR downstream tasks, in which a novel adapter is developed to efficiently introduce richer RGB-IR features into the pre-trained RGB-based foundation model. Specifically, our framework consists of a vision transformer (ViT) foundation model, a Multi-modal Feature Pool (MFP) module and a Supplementary Feature Injector (SFI) module. The MFP and SFI modules cooperate with each other as an adpater to effectively complement the ViT features with the contextual multi-scale features. During training process, we freeze the entire foundation model to inherit prior knowledge and only optimize the MFP and SFI modules. Furthermore, to verify the effectiveness of our framework, we utilize the ViT-Base as the pre-trained foundation model to perform extensive experiments. Experimental results on various RGB-IR downstream tasks demonstrate that our method can achieve state-of-the-art performance. The source code and results are available at https://github.com/PoTsui99/UniRGB-IR.git.
Removal and Selection: Improving RGB-Infrared Object Detection via Coarse-to-Fine Fusion
Jan 19, 2024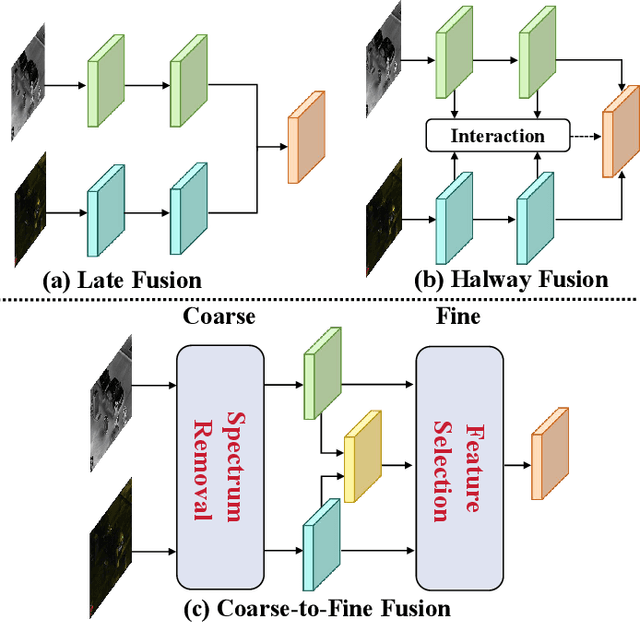



Object detection in visible (RGB) and infrared (IR) images has been widely applied in recent years. Leveraging the complementary characteristics of RGB and IR images, the object detector provides reliable and robust object localization from day to night. Existing fusion strategies directly inject RGB and IR images into convolution neural networks, leading to inferior detection performance. Since the RGB and IR features have modality-specific noise, these strategies will worsen the fused features along with the propagation. Inspired by the mechanism of human brain processing multimodal information, this work introduces a new coarse-to-fine perspective to purify and fuse two modality features. Specifically, following this perspective, we design a Redundant Spectrum Removal module to coarsely remove interfering information within each modality and a Dynamic Feature Selection module to finely select the desired features for feature fusion. To verify the effectiveness of the coarse-to-fine fusion strategy, we construct a new object detector called Removal and Selection Detector (RSDet). Extensive experiments on three RGB-IR object detection datasets verify the superior performance of our method.
$\mathbf{C}^2$Former: Calibrated and Complementary Transformer for RGB-Infrared Object Detection
Jul 15, 2023Object detection on visible (RGB) and infrared (IR) images, as an emerging solution to facilitate robust detection for around-the-clock applications, has received extensive attention in recent years. With the help of IR images, object detectors have been more reliable and robust in practical applications by using RGB-IR combined information. However, existing methods still suffer from modality miscalibration and fusion imprecision problems. Since transformer has the powerful capability to model the pairwise correlations between different features, in this paper, we propose a novel Calibrated and Complementary Transformer called $\mathrm{C}^2$Former to address these two problems simultaneously. In $\mathrm{C}^2$Former, we design an Inter-modality Cross-Attention (ICA) module to obtain the calibrated and complementary features by learning the cross-attention relationship between the RGB and IR modality. To reduce the computational cost caused by computing the global attention in ICA, an Adaptive Feature Sampling (AFS) module is introduced to decrease the dimension of feature maps. Because $\mathrm{C}^2$Former performs in the feature domain, it can be embedded into existed RGB-IR object detectors via the backbone network. Thus, one single-stage and one two-stage object detector both incorporating our $\mathrm{C}^2$Former are constructed to evaluate its effectiveness and versatility. With extensive experiments on the DroneVehicle and KAIST RGB-IR datasets, we verify that our method can fully utilize the RGB-IR complementary information and achieve robust detection results. The code is available at https://github.com/yuanmaoxun/Calibrated-and-Complementary-Transformer-for-RGB-Infrared-Object-Detection.git.
Learning to Pan-sharpening with Memories of Spatial Details
Jun 28, 2023



Pan-sharpening, as one of the most commonly used techniques in remote sensing systems, aims to inject spatial details from panchromatic images into multi-spectral images to obtain high-resolution MS images. Since deep learning has received widespread attention because of its powerful fitting ability and efficient feature extraction, a variety of pan-sharpening methods have been proposed to achieve remarkable performance. However, current pan-sharpening methods usually require the paired PAN and MS images as the input, which limits their usage in some scenarios. To address this issue, in this paper, we observe that the spatial details from PAN images are mainly high-frequency cues, i.e., the edges reflect the contour of input PAN images. This motivates us to develop a PAN-agnostic representation to store some base edges, so as to compose the contour for the corresponding PAN image via them. As a result, we can perform the pan-sharpening task with only the MS image when inference. To this end, a memory-based network is adapted to extract and memorize the spatial details during the training phase and is used to replace the process of obtaining spatial information from PAN images when inference, which is called Memory-based Spatial Details Network (MSDN). We finally integrate the proposed MSDN module into the existing DL-based pan-sharpening methods to achieve an end-to-end pan-sharpening network. With extensive experiments on the Gaofen1 and WorldView-4 satellites, we verify that our method constructs good spatial details without PAN images and achieves the best performance. The code is available at https://github.com/Zhao-Tian-yi/Learning-to-Pan-sharpening-with-Memories-of-Spatial-Details.git.