 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Attention Fusion Net: A Prior-Guided Dual-View Representation Learning for Cardiac Output Estimation from Short-Term PPG Signals
May 19, 2026Accurate cardiac output (CO) estimation from photoplethysmography (PPG) is promising for unobtrusive hemodynamic monitoring, but remains difficult since CO is jointly determined by cardiac function and vascular tone. Conventional feature-based models use physiologically meaningful PPG descriptors, yet depend on accurate pulse detection and may miss latent temporal relationships. In contrast, fully end-to-end deep learning models learn directly from raw PPG but often underuse established PPG-derived prior information. Here, we introduce the Cross-View Attention Fusion Network (CVAF-Net), a prior-guided dual-view deep learning model for CO estimation from short, fixed-length PPG segments. CVAF-Net processes raw PPG as a temporal view and a feature sequence map (FSM) as a structured prior-guided view, and fuses the two representations through cross-view attention. The model was independently evaluated using 5-, 15-, and 30-s segments from three datasets: simulated pulse waves (3323 subjects), vasoconstriction provocation (79 subjects), and resting/cycling activities (10 subjects), and was compared with multiple machine learning and deep learning benchmarks. CVAF-Net outperformed most benchmark methods and achieved performance comparable to a state-of-the-art Transformer-based model, with a mean absolute error (MAE) of 0.19 L/min (MAPE: 3.95%) on simulated data and high accuracy in real-world settings (minimum MAE: 1.20 L/min). Importantly, CVAF-Net reduced FLOPs by twelvefold compared with the leading Transformer-based model. Plausibility analysis showed physiologically consistent CO estimates, with expected correlations with age ($ρ= -0.274$), heart rate ($ρ= 0.894$), and systemic vascular resistance ($ρ= -0.740$). These findings indicate that CVAF-Net provides an accurate, computationally efficient, and generalizable approach for continuous wearable-based CO monitoring.
Compact Latent Manifold Translation: A Parameter-Efficient Foundation Model for Cross-Modal and Cross-Frequency Physiological Signal Synthesis
May 13, 2026The analysis of physiological time series, such as electrocardiograms (ECG) and photoplethysmograms (PPG), is persistently hindered by modality and frequency gaps stemming from heterogeneous recording devices. Existing foundation models typically rely on continuous latent spaces, which frequently suffer from severe modality entanglement, lack high-fidelity cross-frequency generative capacity, and impose high computational costs that prohibit edge-device deployment. In this paper, we propose Compact Latent Manifold Translation (CLMT), a highly parameter-efficient (0.09B) unified framework that bridges these gaps through a novel two-stage discrete translation paradigm. First, we introduce a Universal Tokenizer utilizing Hierarchical Residual Vector Quantization (RVQ) to decouple heterogeneous signals into isolated, well-structured discrete latent manifolds, effectively preventing inter-modality interference. Second, a Context-Prompted Latent Translator maps these discrete tokens across modalities by integrating static physiological priors, reframing complex signal synthesis as a pure latent sequence translation task. Extensive evaluations demonstrate that our 0.09B model significantly outperforms massive baselines. In cross-modal PPG-to-ECG synthesis, it resolves temporal phase drift and dramatically improves the clinical R-peak detection F1-score from 0.37 (baseline) to 0.83. Furthermore, in extreme cross-frequency super-resolution (25Hz to 100Hz), it successfully recovers high-frequency diagnostic landmarks, achieving an unprecedented Pearson correlation of 0.9956. By learning a universal discrete language for biological signals with a fraction of the computational footprint, our approach sets a new trajectory for edge-deployable, multi-modal medical foundation models.
MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Feb 16, 2026We present MedXIAOHE, a medical vision-language foundation model designed to advance general-purpose medical understanding and reasoning in real-world clinical applications. MedXIAOHE achieves state-of-the-art performance across diverse medical benchmarks and surpasses leading closed-source multimodal systems on multiple capabilities. To achieve this, we propose an entity-aware continual pretraining framework that organizes heterogeneous medical corpora to broaden knowledge coverage and reduce long-tail gaps (e.g., rare diseases). For medical expert-level reasoning and interaction, MedXIAOHE incorporates diverse medical reasoning patterns via reinforcement learning and tool-augmented agentic training, enabling multi-step diagnostic reasoning with verifiable decision traces. To improve reliability in real-world use, MedXIAOHE integrates user-preference rubrics, evidence-grounded reasoning, and low-hallucination long-form report generation, with improved adherence to medical instructions. We release this report to document our practical design choices, scaling insights, and evaluation framework, hoping to inspire further research.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Evaluating Multi-Sensor Placement and Neural Network Architectures for Physical Activity Level Classification
Feb 20, 2025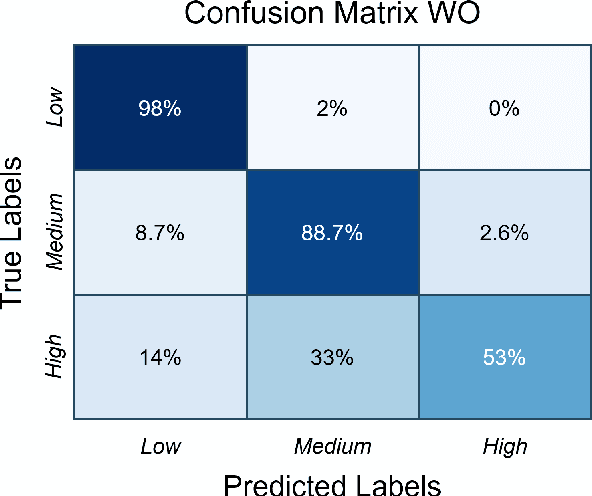
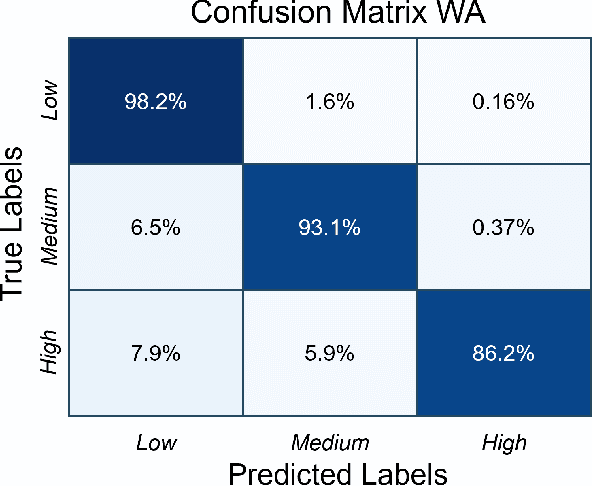
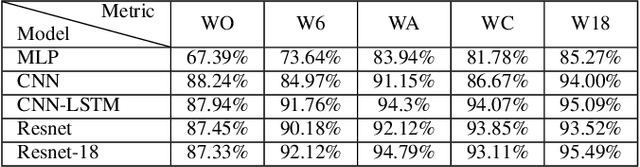
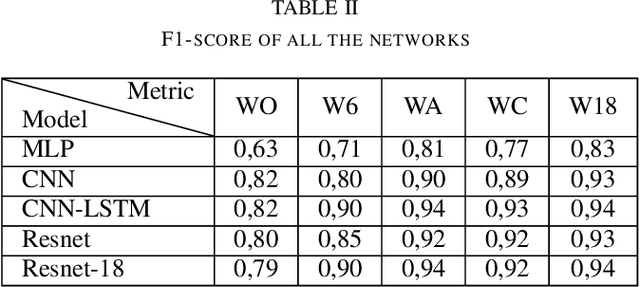
Accurate physical activity level (PAL) classification could be beneficial for osteoarthritis (OA) management. This study examines the impact of sensor placement and deep learning models on AL classification using the Metabolic Equivalent of Task values. The results show that the addition of anankle sensor (WA) significantly improves the classification of intensity activities compared to wrist-only configuration(53% to 86.2%). The CNN-LSTM model achieves the highest accuracy (95.09%). Statistical analysis confirms multi-sensor setups outperform single-sensor configurations (p < 0.05). The WA configuration offers a balance between usability and accuracy, making it a cost-effective solution for AL monitoring, particularly in OA management.
UniRGB-IR: A Unified Framework for Visible-Infrared Downstream Tasks via Adapter Tuning
Apr 26, 2024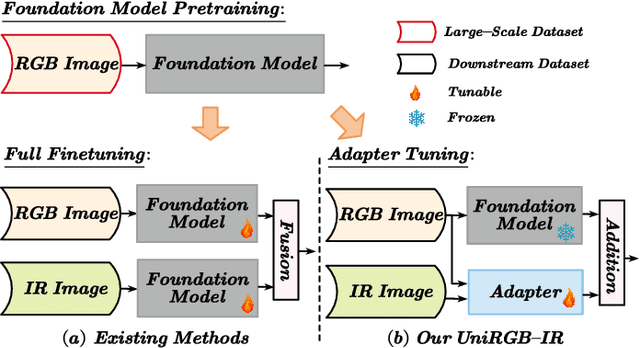

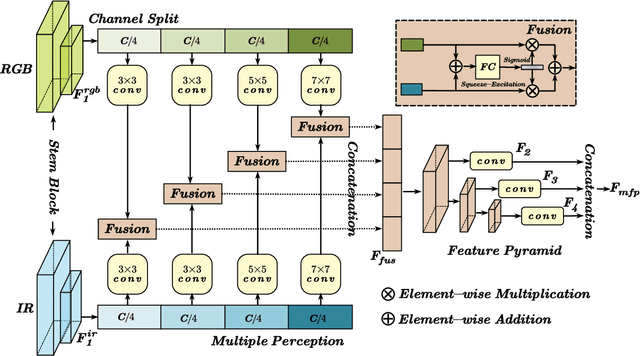
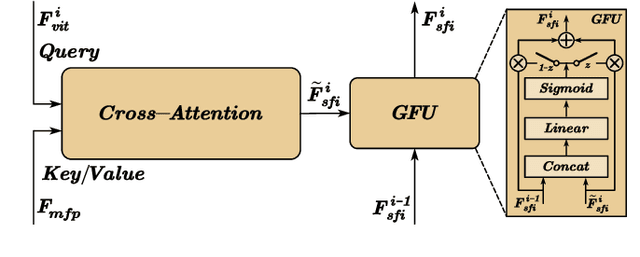
Semantic analysis on visible (RGB) and infrared (IR) images has gained attention for its ability to be more accurate and robust under low-illumination and complex weather conditions. Due to the lack of pre-trained foundation models on the large-scale infrared image datasets, existing methods prefer to design task-specific frameworks and directly fine-tune them with pre-trained foundation models on their RGB-IR semantic relevance datasets, which results in poor scalability and limited generalization. In this work, we propose a scalable and efficient framework called UniRGB-IR to unify RGB-IR downstream tasks, in which a novel adapter is developed to efficiently introduce richer RGB-IR features into the pre-trained RGB-based foundation model. Specifically, our framework consists of a vision transformer (ViT) foundation model, a Multi-modal Feature Pool (MFP) module and a Supplementary Feature Injector (SFI) module. The MFP and SFI modules cooperate with each other as an adpater to effectively complement the ViT features with the contextual multi-scale features. During training process, we freeze the entire foundation model to inherit prior knowledge and only optimize the MFP and SFI modules. Furthermore, to verify the effectiveness of our framework, we utilize the ViT-Base as the pre-trained foundation model to perform extensive experiments. Experimental results on various RGB-IR downstream tasks demonstrate that our method can achieve state-of-the-art performance. The source code and results are available at https://github.com/PoTsui99/UniRGB-IR.git.
Progressive Relation Learning for Group Activity Recognition
Aug 08, 2019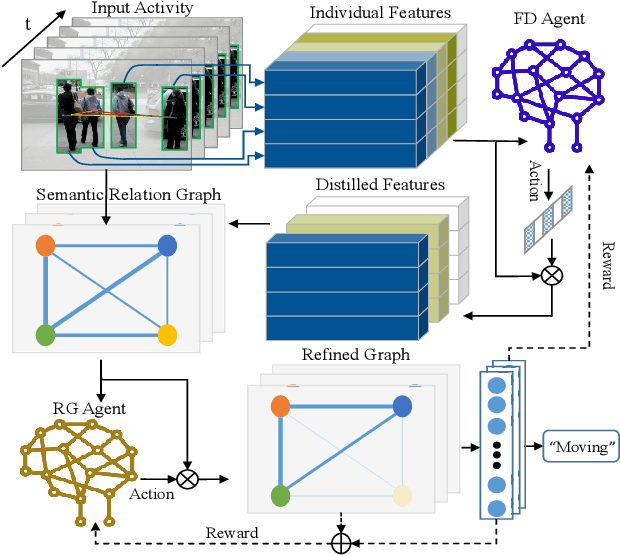
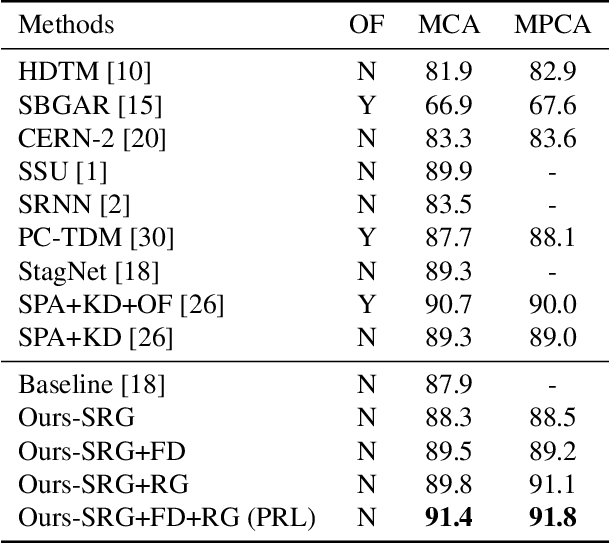
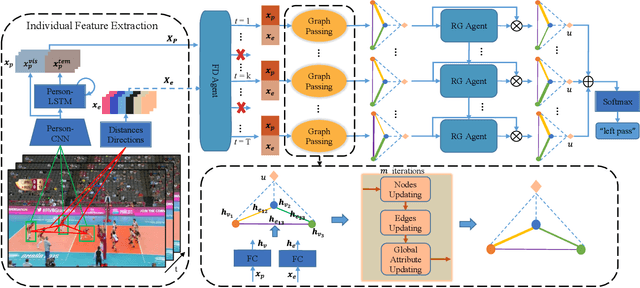
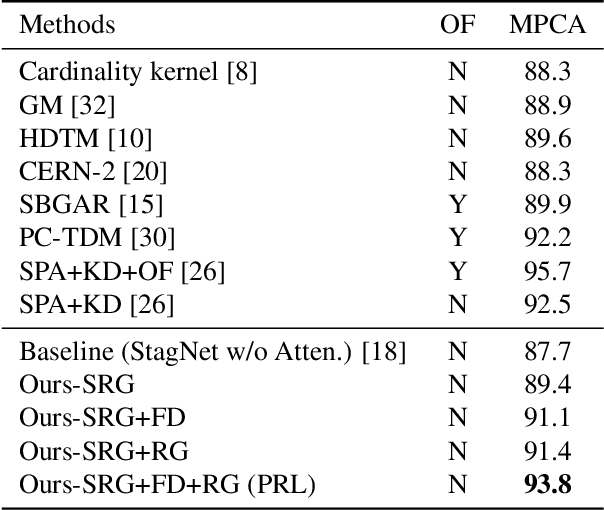
Group activities usually involve spatio-temporal dynamics among many interactive individuals, while only a few participants at several key frames essentially define the activity. Therefore, effectively modeling the group-relevant and suppressing the irrelevant actions (and interactions) are vital for group activity recognition. In this paper, we propose a novel method based on deep reinforcement learning to progressively refine the low-level features and high-level relations of group activities. Firstly, we construct a semantic relation graph (SRG) to explicitly model the relations among persons. Then, two agents adopting policy according to two Markov decision processes are applied to progressively refine the SRG. Specifically, one feature-distilling (FD) agent in the discrete action space refines the low-level spatio-temporal features by distilling the most informative frames. Another relation-gating (RG) agent in continuous action space adjusts the high-level semantic graph to pay more attention to group-relevant relations. The SRG, FD agent, and RG agent are optimized alternately to mutually boost the performance of each other. Extensive experiments on two widely used benchmarks demonstrate the effectiveness and superiority of the proposed approach.
Causally Driven Incremental Multi Touch Attribution Using a Recurrent Neural Network
Feb 05, 2019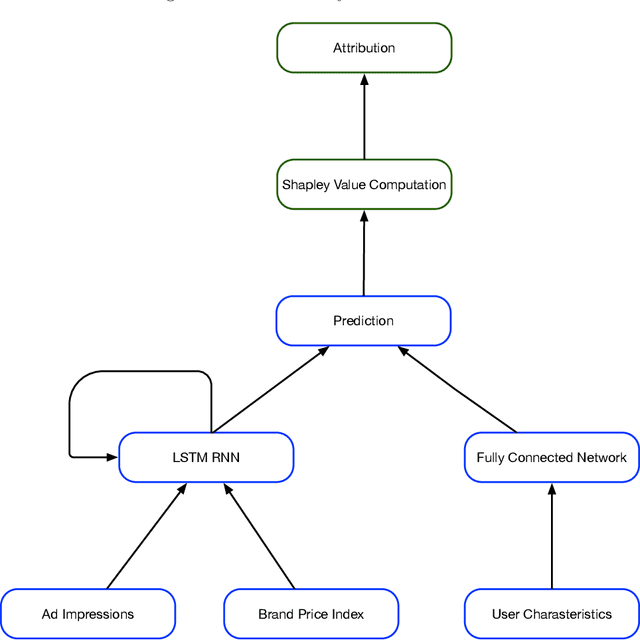

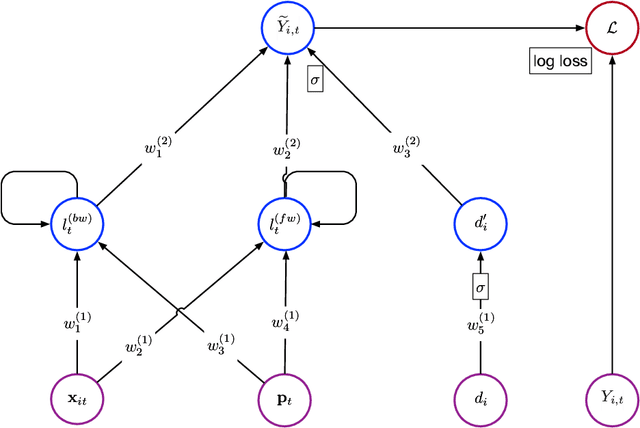
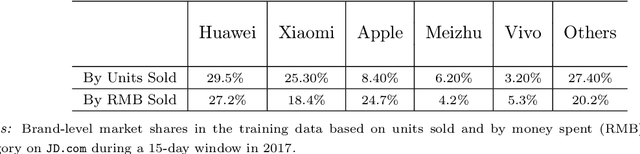
This paper describes a practical system for Multi Touch Attribution (MTA) for use by a publisher of digital ads. We developed this system for JD.com, an eCommerce company, which is also a publisher of digital ads in China. The approach has two steps. The first step ('response modeling') fits a user-level model for purchase of a product as a function of the user's exposure to ads. The second ('credit allocation') uses the fitted model to allocate the incremental part of the observed purchase due to advertising, to the ads the user is exposed to over the previous T days. To implement step one, we train a Recurrent Neural Network (RNN) on user-level conversion and exposure data. The RNN has the advantage of flexibly handling the sequential dependence in the data in a semi-parametric way. The specific RNN formulation we implement captures the impact of advertising intensity, timing, competition, and user-heterogeneity, which are known to be relevant to ad-response. To implement step two, we compute Shapley Values, which have the advantage of having axiomatic foundations and satisfying fairness considerations. The specific formulation of the Shapley Value we implement respects incrementality by allocating the overall incremental improvement in conversion to the exposed ads, while handling the sequence-dependence of exposures on the observed outcomes. The system is under production at JD.com, and scales to handle the high dimensionality of the problem on the platform (attribution of the orders of about 300M users, for roughly 160K brands, across 200+ ad-types, served about 80B ad-impressions over a typical 15-day period).
Skeleton-Based Action Recognition with Synchronous Local and Non-local Spatio-temporal Learning and Frequency Attention
Nov 10, 2018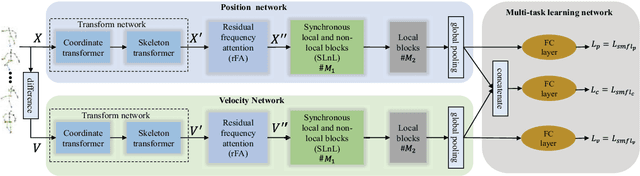
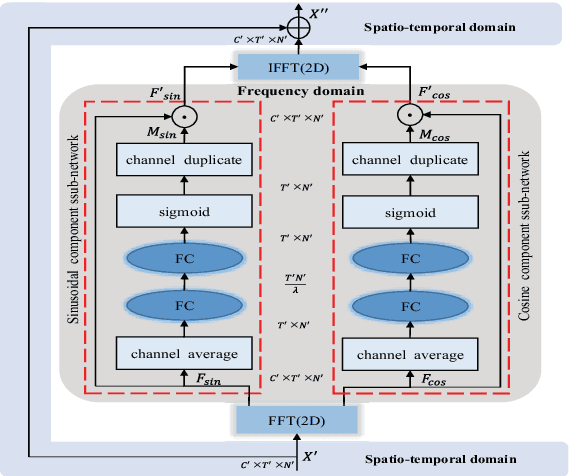
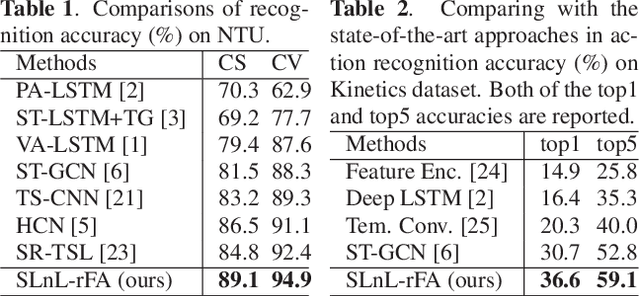
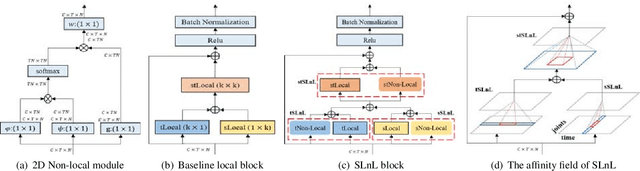
Benefiting from its succinctness and robustness, skeleton-based human action recognition has recently attracted much attention. Most existing methods utilize local networks, such as recurrent networks, convolutional neural networks, and graph convolutional networks, to extract spatio-temporal dynamics hierarchically. As a consequence, the local and non-local dependencies, which respectively contain more details and semantics, are asynchronously captured in different level of layers. Moreover, limited to the spatio-temporal domain, these methods ignored patterns in the frequency domain. To better extract information from multi-domains, we propose a residual frequency attention (rFA) to focus on discriminative patterns in the frequency domain, and a synchronous local and non-local (SLnL) block to simultaneously capture the details and semantics in the spatio-temporal domain. To optimize the whole process, we also propose a soft-margin focal loss (SMFL), which can automatically conducts adaptive data selection and encourages intrinsic margins in classifiers. Extensive experiments are performed on several large-scale action recognition datasets and our approach significantly outperforms other state-of-the-art methods.