 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Trajectories: Unlocking the Intrinsic Generative Optimality of Diffusion Models via Graph-Theoretic Planning
Mar 16, 2026Diffusion models operate in a reflexive System 1 mode, constrained by a fixed, content-agnostic sampling schedule. This rigidity arises from the curse of state dimensionality, where the combinatorial explosion of possible states in the high-dimensional noise manifold renders explicit trajectory planning intractable and leads to systematic computational misallocation. To address this, we introduce Chain-of-Trajectories (CoTj), a train-free framework enabling System 2 deliberative planning. Central to CoTj is Diffusion DNA, a low-dimensional signature that quantifies per-stage denoising difficulty and serves as a proxy for the high-dimensional state space, allowing us to reformulate sampling as graph planning on a directed acyclic graph. Through a Predict-Plan-Execute paradigm, CoTj dynamically allocates computational effort to the most challenging generative phases. Experiments across multiple generative models demonstrate that CoTj discovers context-aware trajectories, improving output quality and stability while reducing redundant computation. This work establishes a new foundation for resource-aware, planning-based diffusion modeling. The code is available at https://github.com/UnicomAI/CoTj.
Fuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025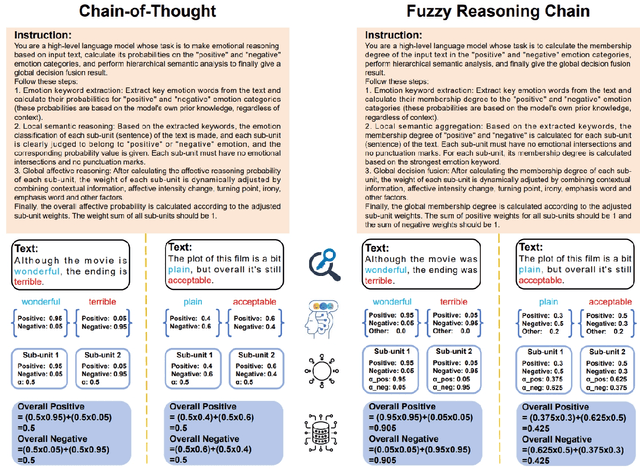
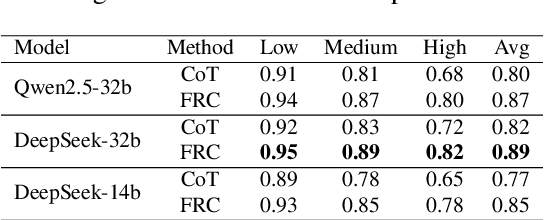
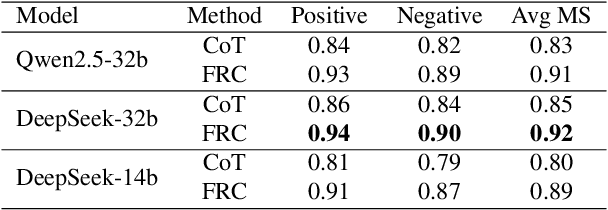
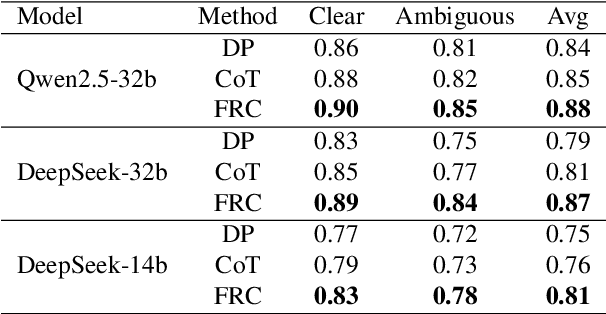
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Hierarchical Deep Fusion Framework for Multi-dimensional Facial Forgery Detection -- The 2024 Global Deepfake Image Detection Challenge
Sep 16, 2025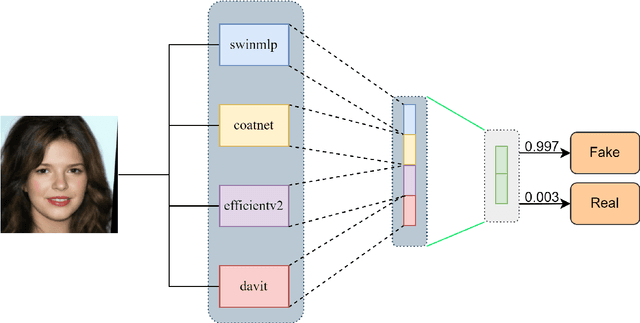

The proliferation of sophisticated deepfake technology poses significant challenges to digital security and authenticity. Detecting these forgeries, especially across a wide spectrum of manipulation techniques, requires robust and generalized models. This paper introduces the Hierarchical Deep Fusion Framework (HDFF), an ensemble-based deep learning architecture designed for high-performance facial forgery detection. Our framework integrates four diverse pre-trained sub-models, Swin-MLP, CoAtNet, EfficientNetV2, and DaViT, which are meticulously fine-tuned through a multi-stage process on the MultiFFDI dataset. By concatenating the feature representations from these specialized models and training a final classifier layer, HDFF effectively leverages their collective strengths. This approach achieved a final score of 0.96852 on the competition's private leaderboard, securing the 20th position out of 184 teams, demonstrating the efficacy of hierarchical fusion for complex image classification tasks.
A Large Vision-Language Model based Environment Perception System for Visually Impaired People
Apr 25, 2025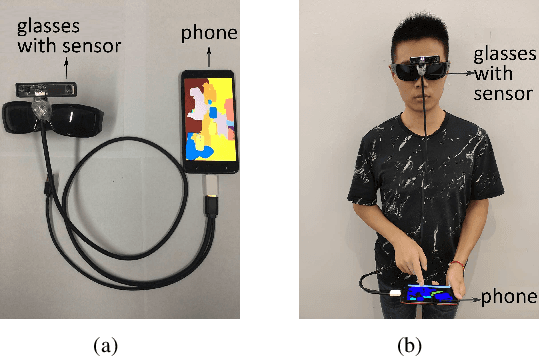
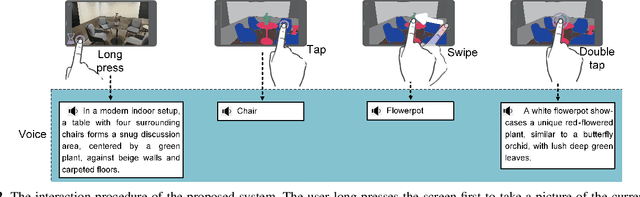
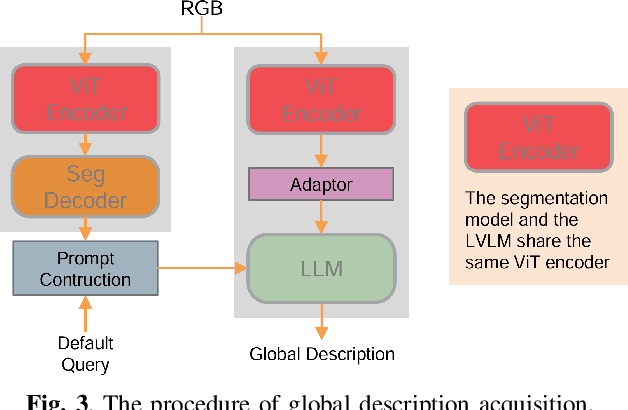

It is a challenging task for visually impaired people to perceive their surrounding environment due to the complexity of the natural scenes. Their personal and social activities are thus highly limited. This paper introduces a Large Vision-Language Model(LVLM) based environment perception system which helps them to better understand the surrounding environment, by capturing the current scene they face with a wearable device, and then letting them retrieve the analysis results through the device. The visually impaired people could acquire a global description of the scene by long pressing the screen to activate the LVLM output, retrieve the categories of the objects in the scene resulting from a segmentation model by tapping or swiping the screen, and get a detailed description of the objects they are interested in by double-tapping the screen. To help visually impaired people more accurately perceive the world, this paper proposes incorporating the segmentation result of the RGB image as external knowledge into the input of LVLM to reduce the LVLM's hallucination. Technical experiments on POPE, MME and LLaVA-QA90 show that the system could provide a more accurate description of the scene compared to Qwen-VL-Chat, exploratory experiments show that the system helps visually impaired people to perceive the surrounding environment effectively.
A Multimodal Benchmark Dataset and Model for Crop Disease Diagnosis
Mar 10, 2025While conversational generative AI has shown considerable potential in enhancing decision-making for agricultural professionals, its exploration has predominantly been anchored in text-based interactions. The evolution of multimodal conversational AI, leveraging vast amounts of image-text data from diverse sources, marks a significant stride forward. However, the application of such advanced vision-language models in the agricultural domain, particularly for crop disease diagnosis, remains underexplored. In this work, we present the crop disease domain multimodal (CDDM) dataset, a pioneering resource designed to advance the field of agricultural research through the application of multimodal learning techniques. The dataset comprises 137,000 images of various crop diseases, accompanied by 1 million question-answer pairs that span a broad spectrum of agricultural knowledge, from disease identification to management practices. By integrating visual and textual data, CDDM facilitates the development of sophisticated question-answering systems capable of providing precise, useful advice to farmers and agricultural professionals. We demonstrate the utility of the dataset by finetuning state-of-the-art multimodal models, showcasing significant improvements in crop disease diagnosis. Specifically, we employed a novel finetuning strategy that utilizes low-rank adaptation (LoRA) to finetune the visual encoder, adapter and language model simultaneously. Our contributions include not only the dataset but also a finetuning strategy and a benchmark to stimulate further research in agricultural technology, aiming to bridge the gap between advanced AI techniques and practical agricultural applications. The dataset is available at https: //github.com/UnicomAI/UnicomBenchmark/tree/main/CDDMBench.
Application-Driven AI Paradigm for Human Action Recognition
Sep 30, 2022
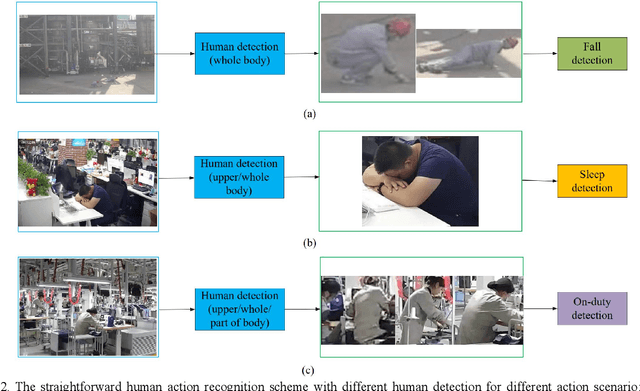
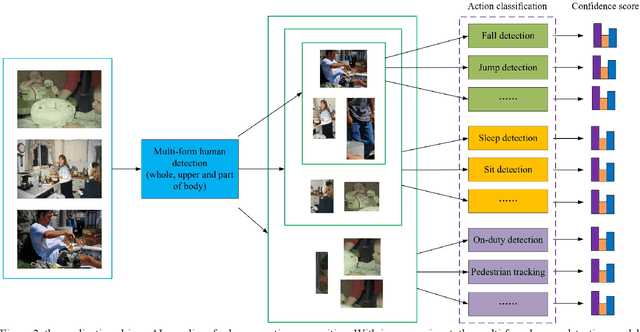

Human action recognition in computer vision has been widely studied in recent years. However, most algorithms consider only certain action specially with even high computational cost. That is not suitable for practical applications with multiple actions to be identified with low computational cost. To meet various application scenarios, this paper presents a unified human action recognition framework composed of two modules, i.e., multi-form human detection and corresponding action classification. Among them, an open-source dataset is constructed to train a multi-form human detection model that distinguishes a human being's whole body, upper body or part body, and the followed action classification model is adopted to recognize such action as falling, sleeping or on-duty, etc. Some experimental results show that the unified framework is effective for various application scenarios. It is expected to be a new application-driven AI paradigm for human action recognition.
A Neural Virtual Anchor Synthesizer based on Seq2Seq and GAN Models
Sep 12, 2019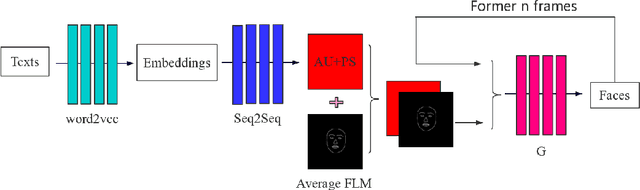
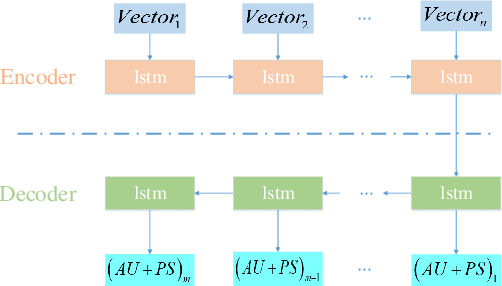
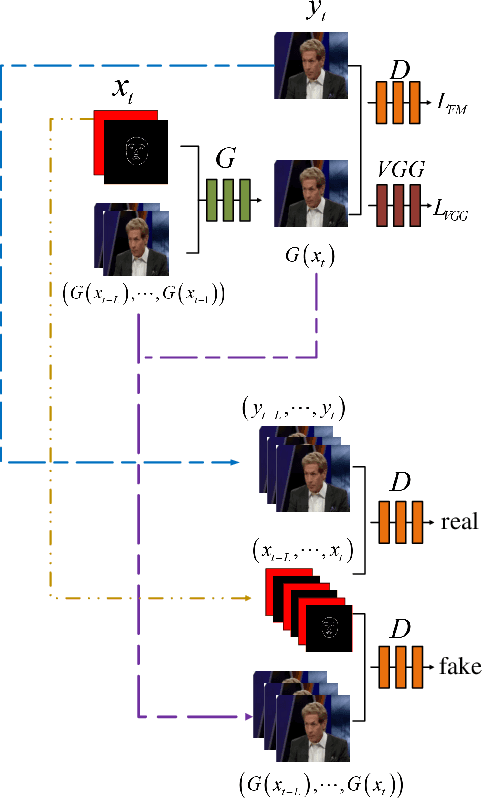

This paper presents a novel framework to generate realistic face video of an anchor, who is reading certain news. This task is also known as Virtual Anchor. Given some paragraphs of words, we first utilize a pretrained Word2Vec model to embed each word into a vector; then we utilize a Seq2Seq-based model to translate these word embeddings into action units and head poses of the target anchor; these action units and head poses will be concatenated with facial landmarks as well as the former $n$ synthesized frames, and the concatenation serves as input of a Pix2PixHD-based model to synthesize realistic facial images for the virtual anchor. The experimental results demonstrate our framework is feasible for the synthesis of virtual anchor.
A Realistic Face-to-Face Conversation System based on Deep Neural Networks
Aug 21, 2019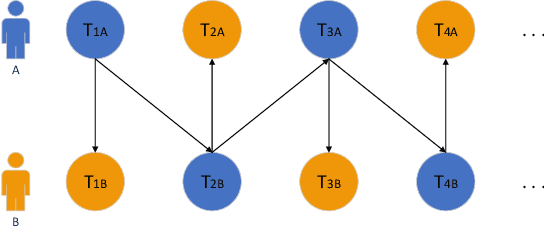

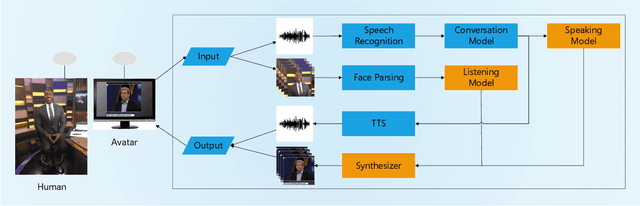
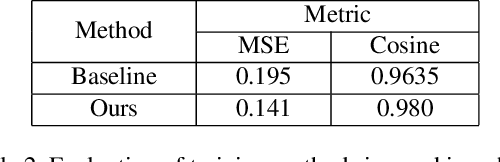
To improve the experiences of face-to-face conversation with avatar, this paper presents a novel conversation system. It is composed of two sequence-to-sequence models respectively for listening and speaking and a Generative Adversarial Network (GAN) based realistic avatar synthesizer. The models exploit the facial action and head pose to learn natural human reactions. Based on the models' output, the synthesizer uses the Pixel2Pixel model to generate realistic facial images. To show the improvement of our system, we use a 3D model based avatar driving scheme as a reference. We train and evaluate our neural networks with the data from ESPN shows. Experimental results show that our conversation system can generate natural facial reactions and realistic facial images.
Deep Learning-based Face Pose Recovery
Apr 30, 2019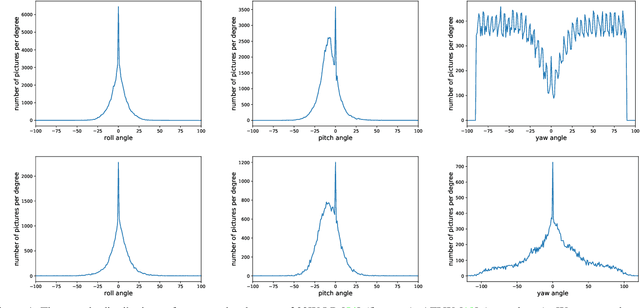
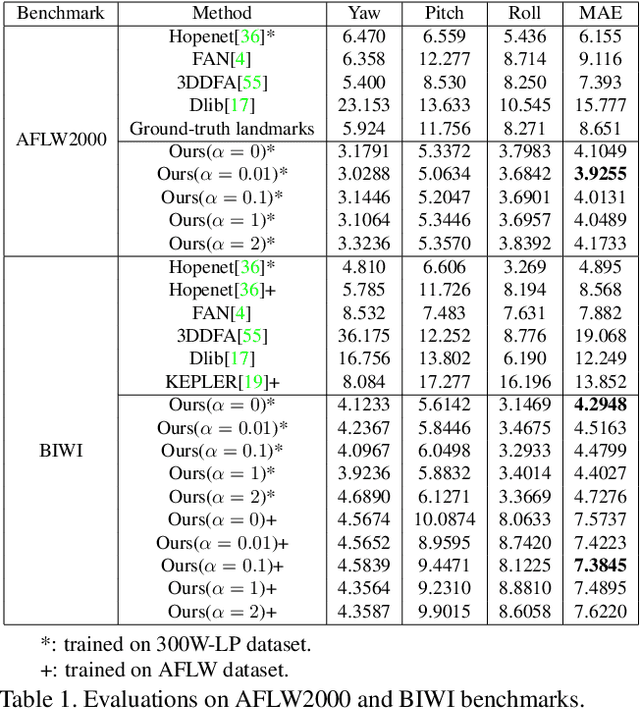
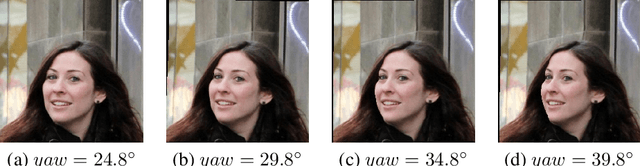
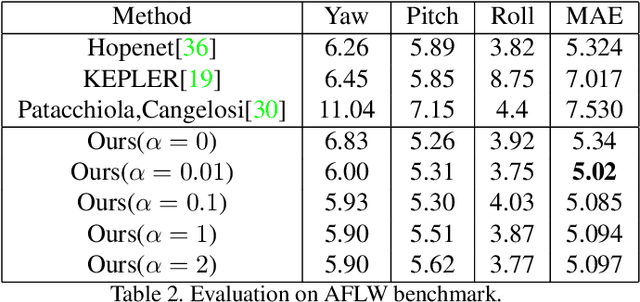
Facial pose estimation has gained a lot of attentions in many practical applications, such as human-robot interaction, gaze estimation and driver monitoring. Meanwhile, end-to-end deep learning-based facial pose estimation is becoming more and more popular. However, facial pose estimation suffers from a key challenge: the lack of sufficient training data for many poses, especially for large poses. Inspired by the observation that the faces under close poses look similar, we reformulate the facial pose estimation as a label distribution learning problem, considering each face image as an example associated with a Gaussian label distribution rather than a single label, and construct a convolutional neural network which is trained with a multi-loss function on AFLW dataset and 300WLP dataset to predict the facial poses directly from color image. Extensive experiments are conducted on several popular benchmarks, including AFLW2000, BIWI, AFLW and AFW, where our approach shows a significant advantage over other state-of-the-art methods.