 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo synthesis of human upper body with realistic face
Sep 12, 2019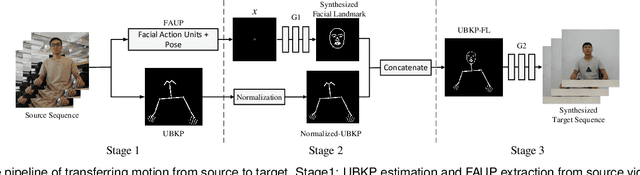
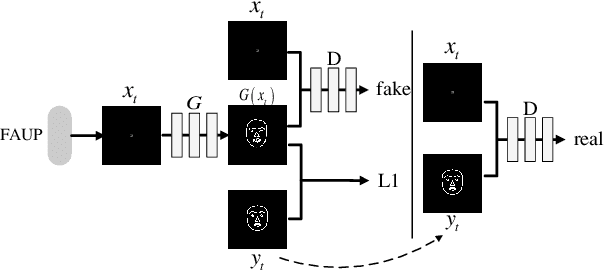
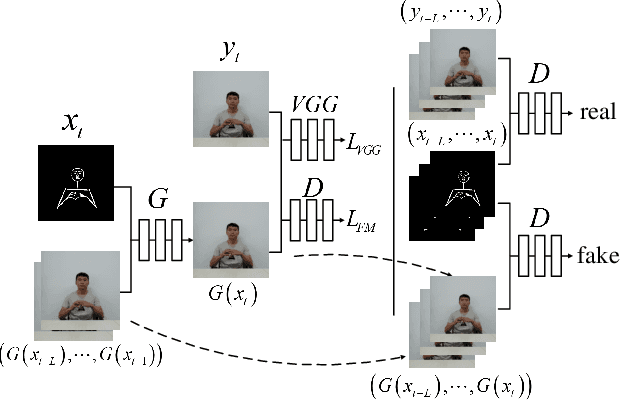

This paper presents a generative adversarial learning-based human upper body video synthesis approach to generate an upper body video of target person that is consistent with the body motion, face expression, and pose of the person in source video. We use upper body keypoints, facial action units and poses as intermediate representations between source video and target video. Instead of directly transferring the source video to the target video, we firstly map the source person's facial action units and poses into the target person's facial landmarks, then combine the normalized upper body keypoints and generated facial landmarks with spatio-temporal smoothing to generate the corresponding target video's image. Experimental results demonstrated the effectiveness of our method.
A Realistic Face-to-Face Conversation System based on Deep Neural Networks
Aug 21, 2019

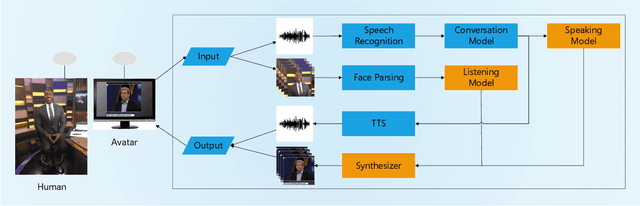
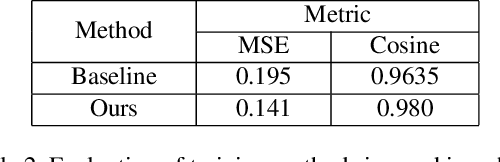
To improve the experiences of face-to-face conversation with avatar, this paper presents a novel conversation system. It is composed of two sequence-to-sequence models respectively for listening and speaking and a Generative Adversarial Network (GAN) based realistic avatar synthesizer. The models exploit the facial action and head pose to learn natural human reactions. Based on the models' output, the synthesizer uses the Pixel2Pixel model to generate realistic facial images. To show the improvement of our system, we use a 3D model based avatar driving scheme as a reference. We train and evaluate our neural networks with the data from ESPN shows. Experimental results show that our conversation system can generate natural facial reactions and realistic facial images.
Fine-grained Attention-based Video Face Recognition
May 06, 2019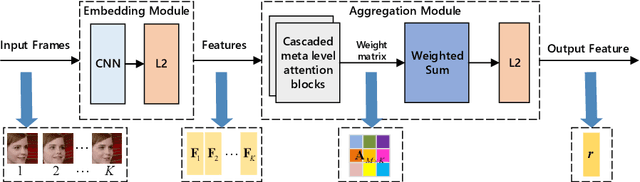



This paper aims to learn a compact representation of a video for video face recognition task. We make the following contributions: first, we propose a meta attention-based aggregation scheme which adaptively and fine-grained weighs the feature along each feature dimension among all frames to form a compact and discriminative representation. It makes the best to exploit the valuable or discriminative part of each frame to promote the performance of face recognition, without discarding or despising low quality frames as usual methods do. Second, we build a feature aggregation network comprised of a feature embedding module and a feature aggregation module. The embedding module is a convolutional neural network used to extract a feature vector from a face image, while the aggregation module consists of cascaded two meta attention blocks which adaptively aggregate the feature vectors into a single fixed-length representation. The network can deal with arbitrary number of frames, and is insensitive to frame order. Third, we validate the performance of proposed aggregation scheme. Experiments on publicly available datasets, such as YouTube face dataset and IJB-A dataset, show the effectiveness of our method, and it achieves competitive performances on both the verification and identification protocols.
Deep Learning-based Face Pose Recovery
Apr 30, 2019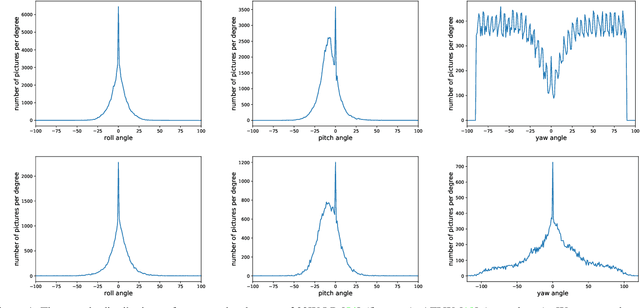
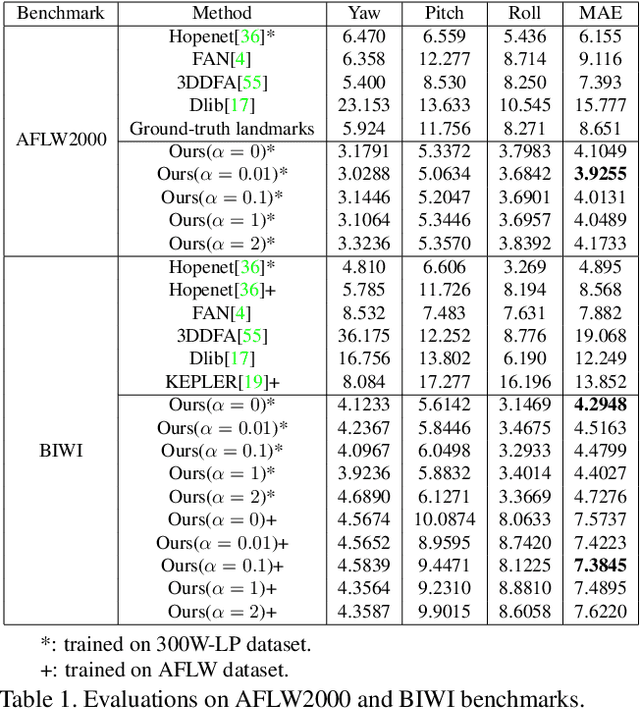
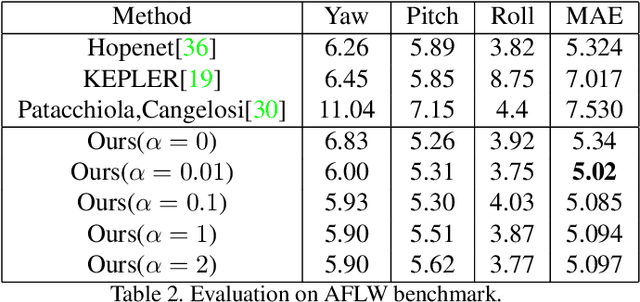
Facial pose estimation has gained a lot of attentions in many practical applications, such as human-robot interaction, gaze estimation and driver monitoring. Meanwhile, end-to-end deep learning-based facial pose estimation is becoming more and more popular. However, facial pose estimation suffers from a key challenge: the lack of sufficient training data for many poses, especially for large poses. Inspired by the observation that the faces under close poses look similar, we reformulate the facial pose estimation as a label distribution learning problem, considering each face image as an example associated with a Gaussian label distribution rather than a single label, and construct a convolutional neural network which is trained with a multi-loss function on AFLW dataset and 300WLP dataset to predict the facial poses directly from color image. Extensive experiments are conducted on several popular benchmarks, including AFLW2000, BIWI, AFLW and AFW, where our approach shows a significant advantage over other state-of-the-art methods.
Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People
Apr 30, 2019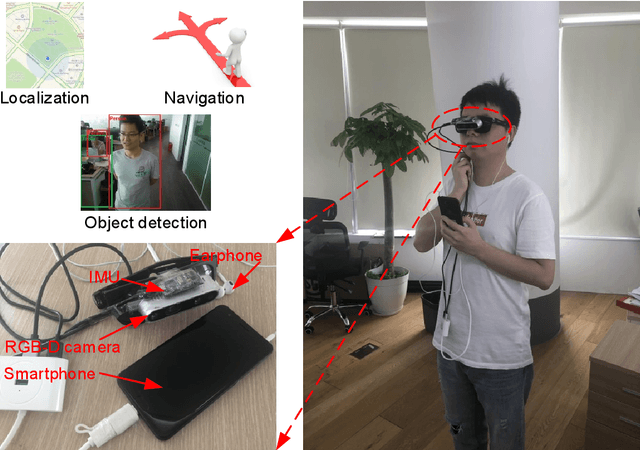
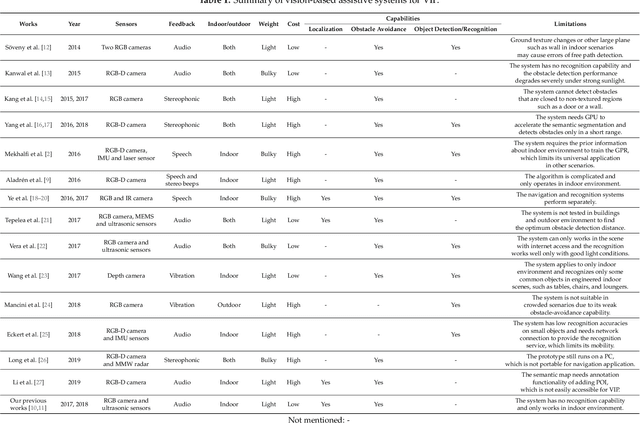
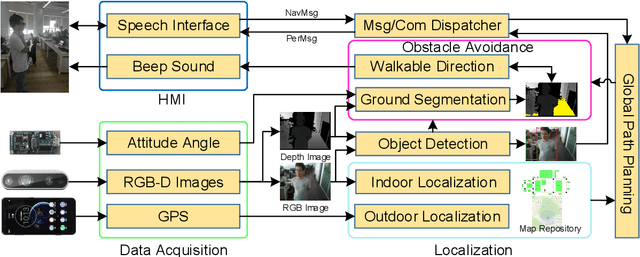
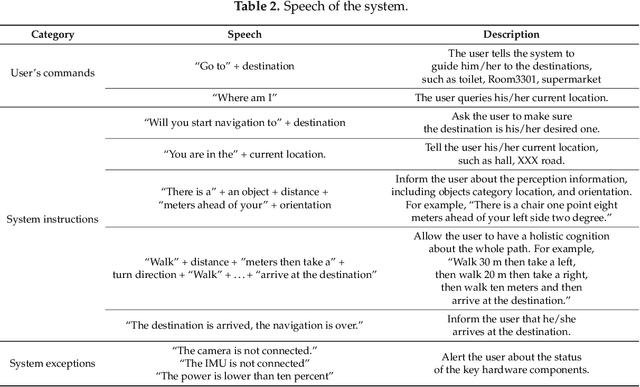
This paper presents a wearable assistive device with the shape of a pair of eyeglasses that allows visually impaired people to navigate safely and quickly in unfamiliar environment, as well as perceive the complicated environment to automatically make decisions on the direction to move. The device uses a consumer Red, Green, Blue and Depth (RGB-D) camera and an Inertial Measurement Unit (IMU) to detect obstacles. As the device leverages the ground height continuity among adjacent image frames, it is able to segment the ground from obstacles accurately and rapidly. Based on the detected ground, the optimal walkable direction is computed and the user is then informed via converted beep sound. Moreover, by utilizing deep learning techniques, the device can semantically categorize the detected obstacles to improve the users' perception of surroundings. It combines a Convolutional Neural Network (CNN) deployed on a smartphone with a depth-image-based object detection to decide what the object type is and where the object is located, and then notifies the user of such information via speech. We evaluated the device's performance with different experiments in which 20 visually impaired people were asked to wear the device and move in an office, and found that they were able to avoid obstacle collisions and find the way in complicated scenarios.
Deep Learning Based Robot for Automatically Picking up Garbage on the Grass
Apr 30, 2019



This paper presents a novel garbage pickup robot which operates on the grass. The robot is able to detect the garbage accurately and autonomously by using a deep neural network for garbage recognition. In addition, with the ground segmentation using a deep neural network, a novel navigation strategy is proposed to guide the robot to move around. With the garbage recognition and automatic navigation functions, the robot can clean garbage on the ground in places like parks or schools efficiently and autonomously. Experimental results show that the garbage recognition accuracy can reach as high as 95%, and even without path planning, the navigation strategy can reach almost the same cleaning efficiency with traditional methods. Thus, the proposed robot can serve as a good assistance to relieve dustman's physical labor on garbage cleaning tasks.
Virtual-Blind-Road Following Based Wearable Navigation Device for Blind People
Apr 30, 2019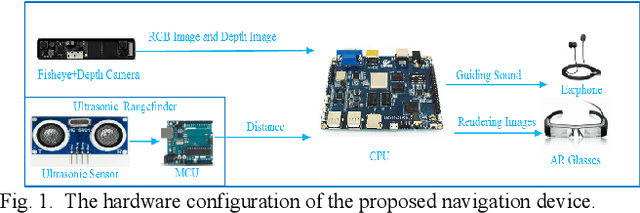
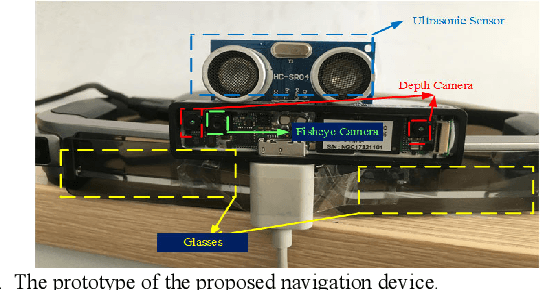

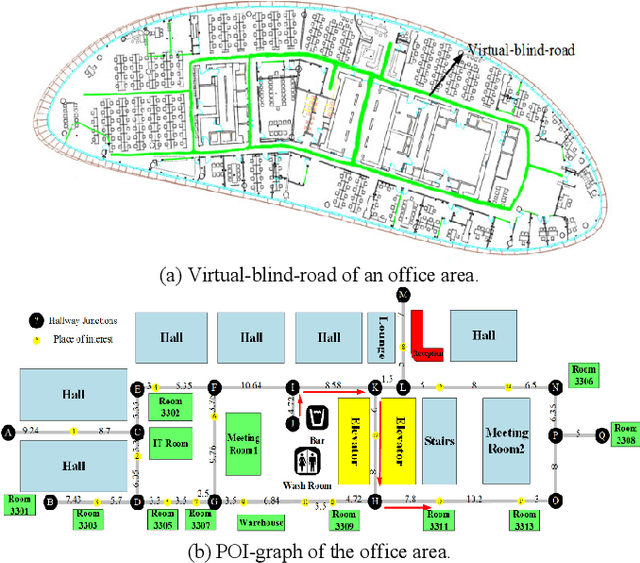
To help the blind people walk to the destination efficiently and safely in indoor environment, a novel wearable navigation device is presented in this paper. The locating, way-finding, route following and obstacle avoiding modules are the essential components in a navigation system, while it remains a challenging task to consider obstacle avoiding during route following, as the indoor environment is complex, changeable and possibly with dynamic objects. To address this issue, we propose a novel scheme which utilizes a dynamic sub-goal selecting strategy to guide the users to the destination and help them bypass obstacles at the same time. This scheme serves as the key component of a complete navigation system deployed on a pair of wearable optical see-through glasses for the ease of use of blind people's daily walks. The proposed navigation device has been tested on a collection of individuals and proved to be effective on indoor navigation tasks. The sensors embedded are of low cost, small volume and easy integration, making it possible for the glasses to be widely used as a wearable consumer device.
Deep Global-Relative Networks for End-to-End 6-DoF Visual Localization and Odometry
Dec 19, 2018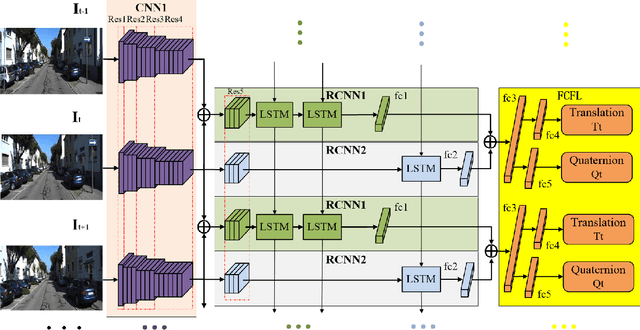

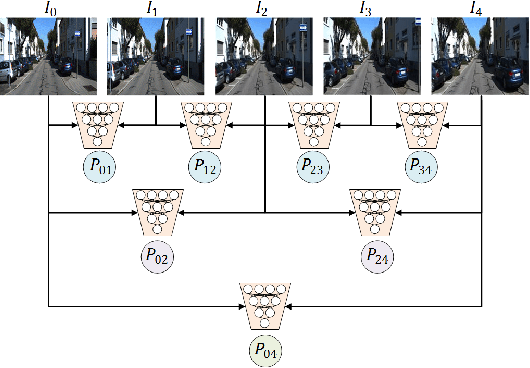

For the autonomous navigation of mobile robots, robust and fast visual localization is a challenging task. Although some end-to-end deep neural networks for 6-DoF Visual Odometry (VO) have been reported with promising results, they are still unable to solve the drift problem in long-range navigation. In this paper, we propose the deep global-relative networks (DGRNets), which is a novel global and relative fusion framework based on Recurrent Convolutional Neural Networks (RCNNs). It is designed to jointly estimate global pose and relative localization from consecutive monocular images. DGRNets include feature extraction sub-networks for discriminative feature selection, RCNNs-type relative pose estimation subnetworks for smoothing the VO trajectory and RCNNs-type global pose regression sub-networks for avoiding the accumulation of pose errors. We also propose two loss functions: the first one consists of Cross Transformation Constraints (CTC) that utilize geometric consistency of the adjacent frames to train a more accurate relative sub-networks, and the second one is composed of CTC and Mean Square Error (MSE) between the predicted pose and ground truth used to train the end-to-end DGRNets. The competitive experiments on indoor Microsoft 7-Scenes and outdoor KITTI dataset show that our DGRNets outperform other learning-based monocular VO methods in terms of pose accuracy.