 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Sep 29, 2021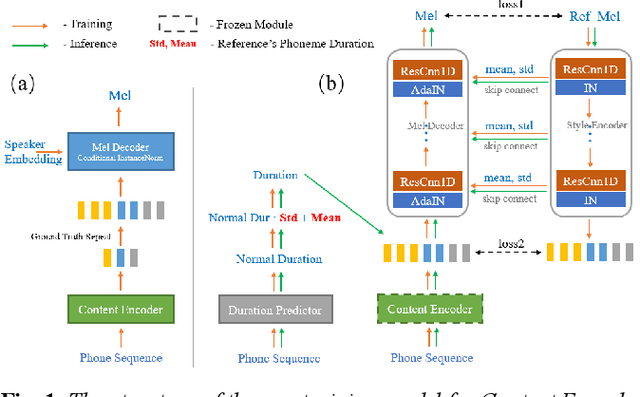
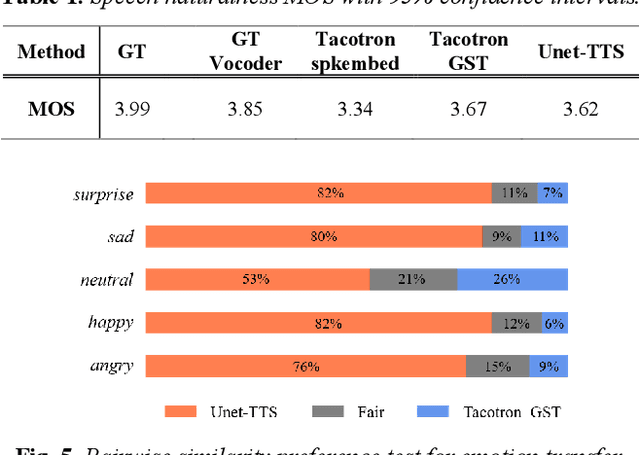
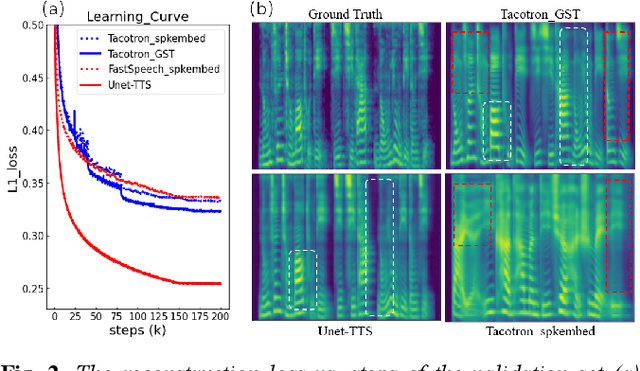
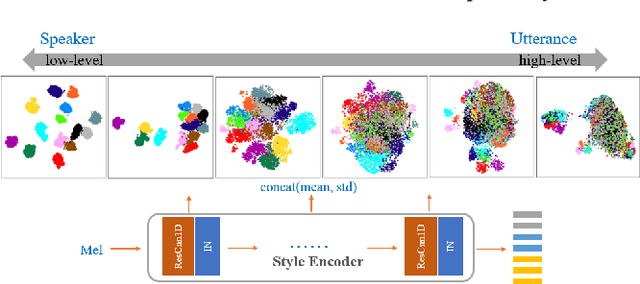
One-shot voice cloning aims to transform speaker voice and speaking style in speech synthesized from a text-to-speech (TTS) system, where only a shot recording from the target reference speech can be used. Out-of-domain transfer is still a challenging task, and one important aspect that impacts the accuracy and similarity of synthetic speech is the conditional representations carrying speaker or style cues extracted from the limited references. In this paper, we present a novel one-shot voice cloning algorithm called Unet-TTS that has good generalization ability for unseen speakers and styles. Based on a skip-connected U-net structure, the new model can efficiently discover speaker-level and utterance-level spectral feature details from the reference audio, enabling accurate inference of complex acoustic characteristics as well as imitation of speaking styles into the synthetic speech. According to both subjective and objective evaluations of similarity, the new model outperforms both speaker embedding and unsupervised style modeling (GST) approaches on an unseen emotional corpus.
A Unified Framework for Mutual Improvement of SLAM and Semantic Segmentation
Dec 25, 2018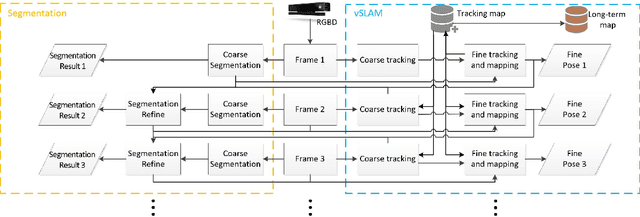
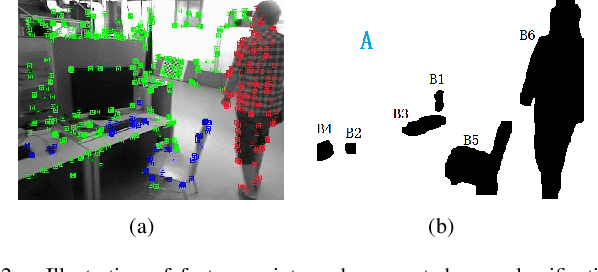
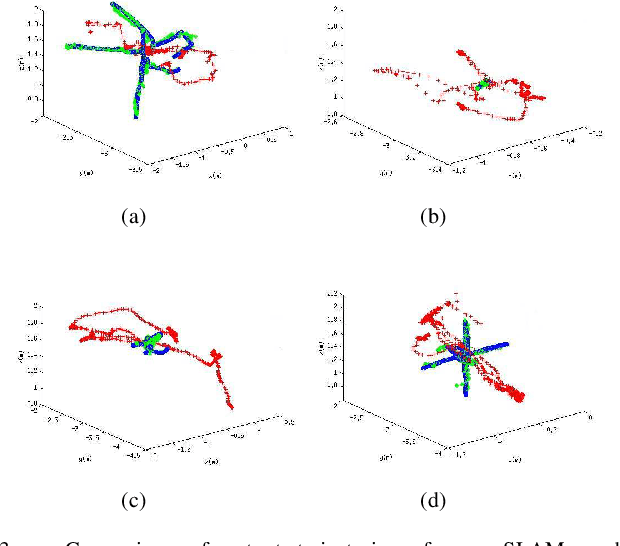

This paper presents a novel framework for simultaneously implementing localization and segmentation, which are two of the most important vision-based tasks for robotics. While the goals and techniques used for them were considered to be different previously, we show that by making use of the intermediate results of the two modules, their performance can be enhanced at the same time. Our framework is able to handle both the instantaneous motion and long-term changes of instances in localization with the help of the segmentation result, which also benefits from the refined 3D pose information. We conduct experiments on various datasets, and prove that our framework works effectively on improving the precision and robustness of the two tasks and outperforms existing localization and segmentation algorithms.
Deep Global-Relative Networks for End-to-End 6-DoF Visual Localization and Odometry
Dec 19, 2018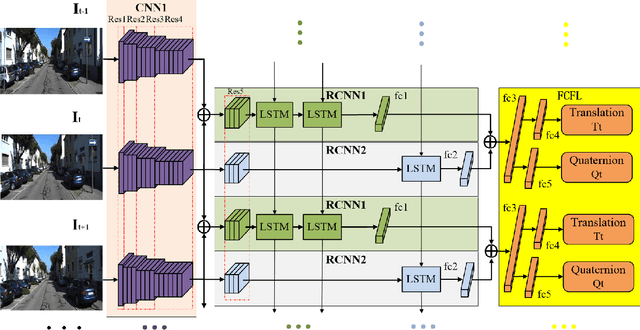

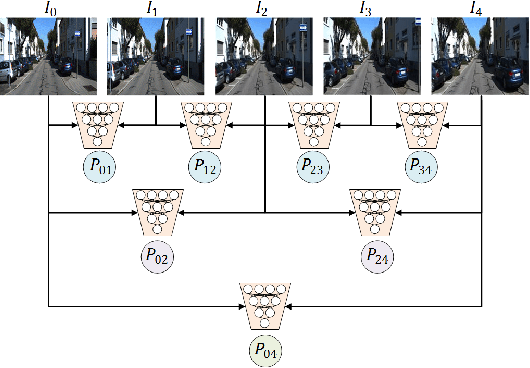

For the autonomous navigation of mobile robots, robust and fast visual localization is a challenging task. Although some end-to-end deep neural networks for 6-DoF Visual Odometry (VO) have been reported with promising results, they are still unable to solve the drift problem in long-range navigation. In this paper, we propose the deep global-relative networks (DGRNets), which is a novel global and relative fusion framework based on Recurrent Convolutional Neural Networks (RCNNs). It is designed to jointly estimate global pose and relative localization from consecutive monocular images. DGRNets include feature extraction sub-networks for discriminative feature selection, RCNNs-type relative pose estimation subnetworks for smoothing the VO trajectory and RCNNs-type global pose regression sub-networks for avoiding the accumulation of pose errors. We also propose two loss functions: the first one consists of Cross Transformation Constraints (CTC) that utilize geometric consistency of the adjacent frames to train a more accurate relative sub-networks, and the second one is composed of CTC and Mean Square Error (MSE) between the predicted pose and ground truth used to train the end-to-end DGRNets. The competitive experiments on indoor Microsoft 7-Scenes and outdoor KITTI dataset show that our DGRNets outperform other learning-based monocular VO methods in terms of pose accuracy.
A Fog Robotic System for Dynamic Visual Servoing
Sep 16, 2018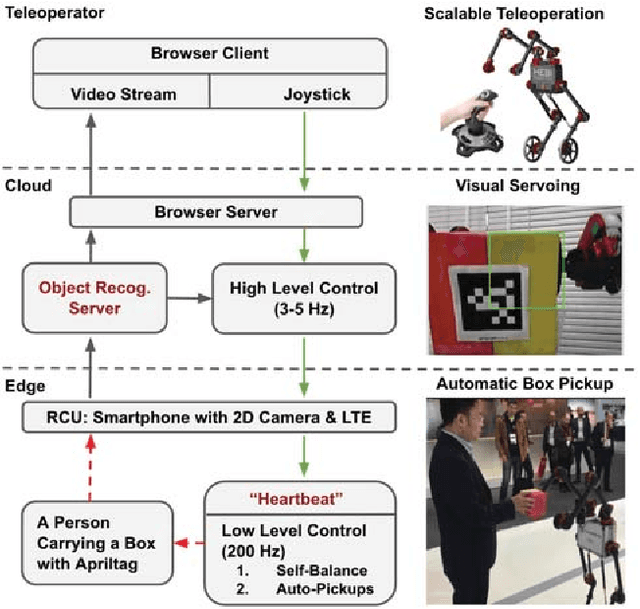

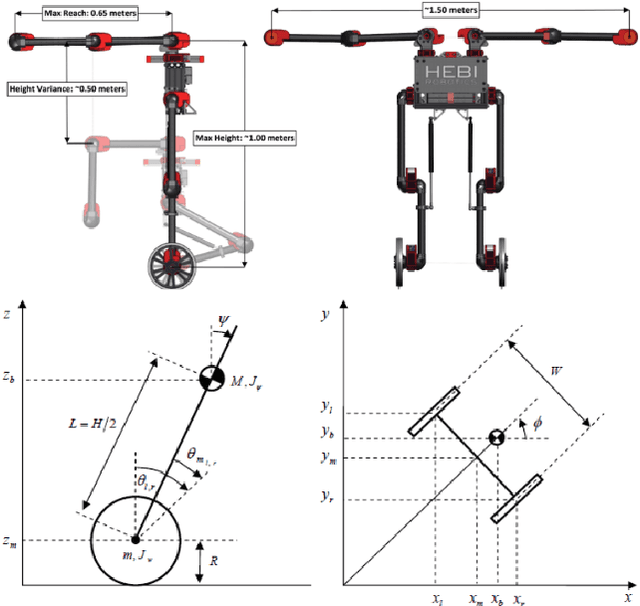
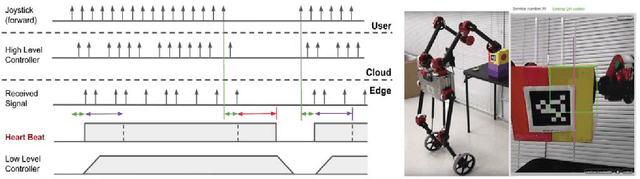
Cloud Robotics is a paradigm where distributed robots are connected to cloud services via networks to access unlimited computation power, at the cost of network communication. However, due to limitations such as network latency and variability, it is difficult to control dynamic, human compliant service robots directly from the cloud. In this work, by leveraging asynchronous protocol with a heartbeat signal, we combine cloud robotics with a smart edge device to build a Fog Robotic system. We use the system to enable robust teleoperation of a dynamic self-balancing robot from the cloud. We first use the system to pick up boxes from static locations, a task commonly performed in warehouse logistics. To make cloud teleoperation more efficient, we deploy image based visual servoing (IBVS) to perform box pickups automatically. Visual feedbacks, including apriltag recognition and tracking, are performed in the cloud to emulate a Fog Robotic object recognition system for IBVS. We demonstrate the feasibility of real-time dynamic automation system using this cloud-edge hybrid, which opens up possibilities of deploying dynamic robotic control with deep-learning recognition systems in Fog Robotics. Finally, we show that Fog Robotics enables the self-balancing service robot to pick up a box automatically from a person under unstructured environments.