 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTP3M: Transformer-based Pseudo 3D Image Matching with Reference
May 14, 2024



Image matching is still challenging in such scenes with large viewpoints or illumination changes or with low textures. In this paper, we propose a Transformer-based pseudo 3D image matching method. It upgrades the 2D features extracted from the source image to 3D features with the help of a reference image and matches to the 2D features extracted from the destination image by the coarse-to-fine 3D matching. Our key discovery is that by introducing the reference image, the source image's fine points are screened and furtherly their feature descriptors are enriched from 2D to 3D, which improves the match performance with the destination image. Experimental results on multiple datasets show that the proposed method achieves the state-of-the-art on the tasks of homography estimation, pose estimation and visual localization especially in challenging scenes.
DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry using 3D Geometric Constraints
Jun 28, 2019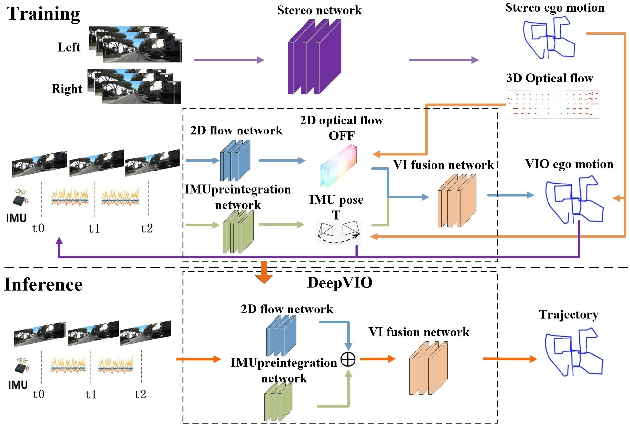
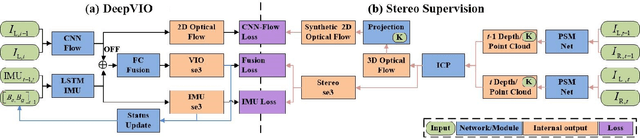


This paper presents an self-supervised deep learning network for monocular visual inertial odometry (named DeepVIO). DeepVIO provides absolute trajectory estimation by directly merging 2D optical flow feature (OFF) and Inertial Measurement Unit (IMU) data. Specifically, it firstly estimates the depth and dense 3D point cloud of each scene by using stereo sequences, and then obtains 3D geometric constraints including 3D optical flow and 6-DoF pose as supervisory signals. Note that such 3D optical flow shows robustness and accuracy to dynamic objects and textureless environments. In DeepVIO training, 2D optical flow network is constrained by the projection of its corresponding 3D optical flow, and LSTM-style IMU preintegration network and the fusion network are learned by minimizing the loss functions from ego-motion constraints. Furthermore, we employ an IMU status update scheme to improve IMU pose estimation through updating the additional gyroscope and accelerometer bias. The experimental results on KITTI and EuRoC datasets show that DeepVIO outperforms state-of-the-art learning based methods in terms of accuracy and data adaptability. Compared to the traditional methods, DeepVIO reduces the impacts of inaccurate Camera-IMU calibrations, unsynchronized and missing data.
A Unified Framework for Mutual Improvement of SLAM and Semantic Segmentation
Dec 25, 2018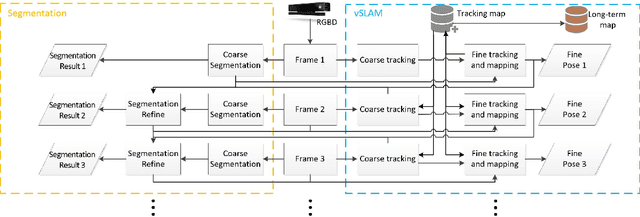
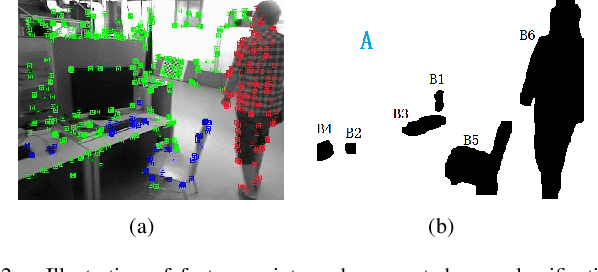
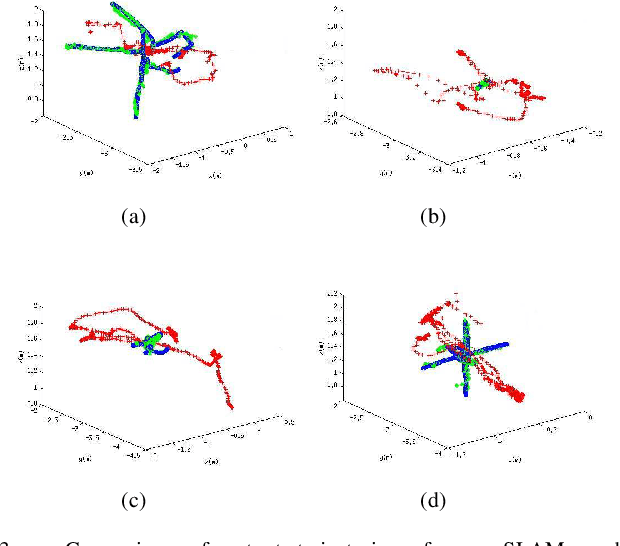

This paper presents a novel framework for simultaneously implementing localization and segmentation, which are two of the most important vision-based tasks for robotics. While the goals and techniques used for them were considered to be different previously, we show that by making use of the intermediate results of the two modules, their performance can be enhanced at the same time. Our framework is able to handle both the instantaneous motion and long-term changes of instances in localization with the help of the segmentation result, which also benefits from the refined 3D pose information. We conduct experiments on various datasets, and prove that our framework works effectively on improving the precision and robustness of the two tasks and outperforms existing localization and segmentation algorithms.