 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry using 3D Geometric Constraints
Jun 28, 2019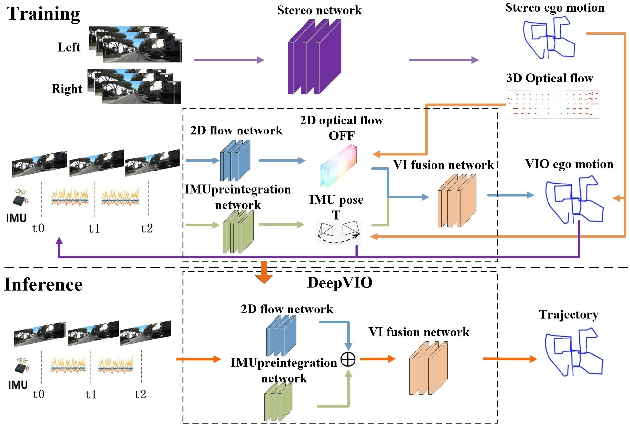
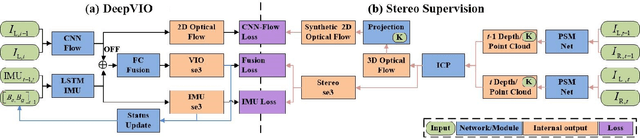


This paper presents an self-supervised deep learning network for monocular visual inertial odometry (named DeepVIO). DeepVIO provides absolute trajectory estimation by directly merging 2D optical flow feature (OFF) and Inertial Measurement Unit (IMU) data. Specifically, it firstly estimates the depth and dense 3D point cloud of each scene by using stereo sequences, and then obtains 3D geometric constraints including 3D optical flow and 6-DoF pose as supervisory signals. Note that such 3D optical flow shows robustness and accuracy to dynamic objects and textureless environments. In DeepVIO training, 2D optical flow network is constrained by the projection of its corresponding 3D optical flow, and LSTM-style IMU preintegration network and the fusion network are learned by minimizing the loss functions from ego-motion constraints. Furthermore, we employ an IMU status update scheme to improve IMU pose estimation through updating the additional gyroscope and accelerometer bias. The experimental results on KITTI and EuRoC datasets show that DeepVIO outperforms state-of-the-art learning based methods in terms of accuracy and data adaptability. Compared to the traditional methods, DeepVIO reduces the impacts of inaccurate Camera-IMU calibrations, unsynchronized and missing data.
Vision-based Robotic Grasping from Object Localization, Pose Estimation, Grasp Detection to Motion Planning: A Review
May 16, 2019



This paper presents a comprehensive survey on vision-based robotic grasping. We concluded four key tasks during robotic grasping, which are object localization, pose estimation, grasp detection and motion planning. In detail, object localization includes object detection and segmentation methods, pose estimation includes RGB-based and RGB-D-based methods, grasp detection includes traditional methods and deep learning-based methods, motion planning includes analytical methods, imitating learning methods, and reinforcement learning methods. Besides, lots of methods accomplish some of the tasks jointly, such as object-detection-combined 6D pose estimation, grasp detection without pose estimation, end-to-end grasp detection, and end-to-end motion planning. These methods are reviewed elaborately in this survey. What's more, related datasets are summarized and comparisons between state-of-the-art methods are given for each task. Challenges about robotic grasping are presented, and future directions in addressing these challenges are also pointed out.
Deep Global-Relative Networks for End-to-End 6-DoF Visual Localization and Odometry
Dec 19, 2018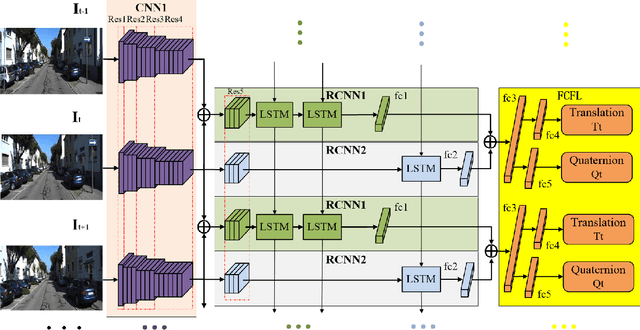

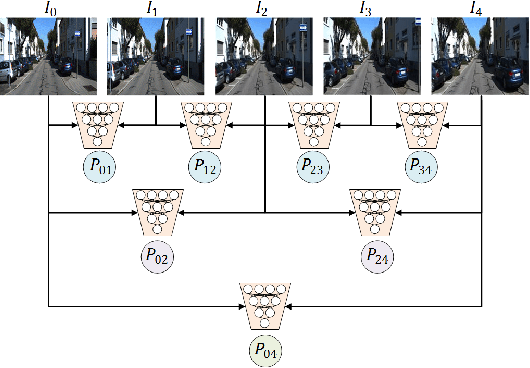

For the autonomous navigation of mobile robots, robust and fast visual localization is a challenging task. Although some end-to-end deep neural networks for 6-DoF Visual Odometry (VO) have been reported with promising results, they are still unable to solve the drift problem in long-range navigation. In this paper, we propose the deep global-relative networks (DGRNets), which is a novel global and relative fusion framework based on Recurrent Convolutional Neural Networks (RCNNs). It is designed to jointly estimate global pose and relative localization from consecutive monocular images. DGRNets include feature extraction sub-networks for discriminative feature selection, RCNNs-type relative pose estimation subnetworks for smoothing the VO trajectory and RCNNs-type global pose regression sub-networks for avoiding the accumulation of pose errors. We also propose two loss functions: the first one consists of Cross Transformation Constraints (CTC) that utilize geometric consistency of the adjacent frames to train a more accurate relative sub-networks, and the second one is composed of CTC and Mean Square Error (MSE) between the predicted pose and ground truth used to train the end-to-end DGRNets. The competitive experiments on indoor Microsoft 7-Scenes and outdoor KITTI dataset show that our DGRNets outperform other learning-based monocular VO methods in terms of pose accuracy.