 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
Segmenting Objectiveness and Task-awareness Unknown Region for Autonomous Driving
Apr 27, 2025With the emergence of transformer-based architectures and large language models (LLMs), the accuracy of road scene perception has substantially advanced. Nonetheless, current road scene segmentation approaches are predominantly trained on closed-set data, resulting in insufficient detection capabilities for out-of-distribution (OOD) objects. To overcome this limitation, road anomaly detection methods have been proposed. However, existing methods primarily depend on image inpainting and OOD distribution detection techniques, facing two critical issues: (1) inadequate consideration of the objectiveness attributes of anomalous regions, causing incomplete segmentation when anomalous objects share similarities with known classes, and (2) insufficient attention to environmental constraints, leading to the detection of anomalies irrelevant to autonomous driving tasks. In this paper, we propose a novel framework termed Segmenting Objectiveness and Task-Awareness (SOTA) for autonomous driving scenes. Specifically, SOTA enhances the segmentation of objectiveness through a Semantic Fusion Block (SFB) and filters anomalies irrelevant to road navigation tasks using a Scene-understanding Guided Prompt-Context Adaptor (SG-PCA). Extensive empirical evaluations on multiple benchmark datasets, including Fishyscapes Lost and Found, Segment-Me-If-You-Can, and RoadAnomaly, demonstrate that the proposed SOTA consistently improves OOD detection performance across diverse detectors, achieving robust and accurate segmentation outcomes.
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
SEGT: A General Spatial Expansion Group Transformer for nuScenes Lidar-based Object Detection Task
Dec 12, 2024

In the technical report, we present a novel transformer-based framework for nuScenes lidar-based object detection task, termed Spatial Expansion Group Transformer (SEGT). To efficiently handle the irregular and sparse nature of point cloud, we propose migrating the voxels into distinct specialized ordered fields with the general spatial expansion strategies, and employ group attention mechanisms to extract the exclusive feature maps within each field. Subsequently, we integrate the feature representations across different ordered fields by alternately applying diverse expansion strategies, thereby enhancing the model's ability to capture comprehensive spatial information. The method was evaluated on the nuScenes lidar-based object detection test dataset, achieving an NDS score of 73.5 without Test-Time Augmentation (TTA) and 74.2 with TTA, demonstrating the effectiveness of the proposed method.
Efficient Semantic Segmentation via Lightweight Multiple-Information Interaction Network
Oct 03, 2024Recently, the integration of the local modeling capabilities of Convolutional Neural Networks (CNNs) with the global dependency strengths of Transformers has created a sensation in the semantic segmentation community. However, substantial computational workloads and high hardware memory demands remain major obstacles to their further application in real-time scenarios. In this work, we propose a lightweight multiple-information interaction network for real-time semantic segmentation, called LMIINet, which effectively combines CNNs and Transformers while reducing redundant computations and memory footprint. It features Lightweight Feature Interaction Bottleneck (LFIB) modules comprising efficient convolutions that enhance context integration. Additionally, improvements are made to the Flatten Transformer by enhancing local and global feature interaction to capture detailed semantic information. The incorporation of a combination coefficient learning scheme in both LFIB and Transformer blocks facilitates improved feature interaction. Extensive experiments demonstrate that LMIINet excels in balancing accuracy and efficiency. With only 0.72M parameters and 11.74G FLOPs, LMIINet achieves 72.0% mIoU at 100 FPS on the Cityscapes test set and 69.94% mIoU at 160 FPS on the CamVid test dataset using a single RTX2080Ti GPU.
Diffusion Models in Low-Level Vision: A Survey
Jun 17, 2024


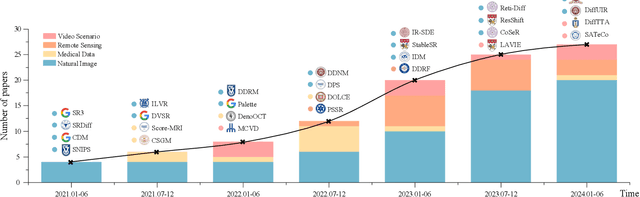
Deep generative models have garnered significant attention in low-level vision tasks due to their generative capabilities. Among them, diffusion model-based solutions, characterized by a forward diffusion process and a reverse denoising process, have emerged as widely acclaimed for their ability to produce samples of superior quality and diversity. This ensures the generation of visually compelling results with intricate texture information. Despite their remarkable success, a noticeable gap exists in a comprehensive survey that amalgamates these pioneering diffusion model-based works and organizes the corresponding threads. This paper proposes the comprehensive review of diffusion model-based techniques. We present three generic diffusion modeling frameworks and explore their correlations with other deep generative models, establishing the theoretical foundation. Following this, we introduce a multi-perspective categorization of diffusion models, considering both the underlying framework and the target task. Additionally, we summarize extended diffusion models applied in other tasks, including medical, remote sensing, and video scenarios. Moreover, we provide an overview of commonly used benchmarks and evaluation metrics. We conduct a thorough evaluation, encompassing both performance and efficiency, of diffusion model-based techniques in three prominent tasks. Finally, we elucidate the limitations of current diffusion models and propose seven intriguing directions for future research. This comprehensive examination aims to facilitate a profound understanding of the landscape surrounding denoising diffusion models in the context of low-level vision tasks. A curated list of diffusion model-based techniques in over 20 low-level vision tasks can be found at https://github.com/ChunmingHe/awesome-diffusion-models-in-low-level-vision.
Image Content Generation with Causal Reasoning
Dec 12, 2023The emergence of ChatGPT has once again sparked research in generative artificial intelligence (GAI). While people have been amazed by the generated results, they have also noticed the reasoning potential reflected in the generated textual content. However, this current ability for causal reasoning is primarily limited to the domain of language generation, such as in models like GPT-3. In visual modality, there is currently no equivalent research. Considering causal reasoning in visual content generation is significant. This is because visual information contains infinite granularity. Particularly, images can provide more intuitive and specific demonstrations for certain reasoning tasks, especially when compared to coarse-grained text. Hence, we propose a new image generation task called visual question answering with image (VQAI) and establish a dataset of the same name based on the classic \textit{Tom and Jerry} animated series. Additionally, we develop a new paradigm for image generation to tackle the challenges of this task. Finally, we perform extensive experiments and analyses, including visualizations of the generated content and discussions on the potentials and limitations. The code and data are publicly available under the license of CC BY-NC-SA 4.0 for academic and non-commercial usage. The code and dataset are publicly available at: https://github.com/IEIT-AGI/MIX-Shannon/blob/main/projects/VQAI/lgd_vqai.md.
Reti-Diff: Illumination Degradation Image Restoration with Retinex-based Latent Diffusion Model
Nov 20, 2023Illumination degradation image restoration (IDIR) techniques aim to improve the visibility of degraded images and mitigate the adverse effects of deteriorated illumination. Among these algorithms, diffusion model (DM)-based methods have shown promising performance but are often burdened by heavy computational demands and pixel misalignment issues when predicting the image-level distribution. To tackle these problems, we propose to leverage DM within a compact latent space to generate concise guidance priors and introduce a novel solution called Reti-Diff for the IDIR task. Reti-Diff comprises two key components: the Retinex-based latent DM (RLDM) and the Retinex-guided transformer (RGformer). To ensure detailed reconstruction and illumination correction, RLDM is empowered to acquire Retinex knowledge and extract reflectance and illumination priors. These priors are subsequently utilized by RGformer to guide the decomposition of image features into their respective reflectance and illumination components. Following this, RGformer further enhances and consolidates the decomposed features, resulting in the production of refined images with consistent content and robustness to handle complex degradation scenarios. Extensive experiments show that Reti-Diff outperforms existing methods on three IDIR tasks, as well as downstream applications. Code will be available at \url{https://github.com/ChunmingHe/Reti-Diff}.
UniM$^2$AE: Multi-modal Masked Autoencoders with Unified 3D Representation for 3D Perception in Autonomous Driving
Aug 30, 2023



Masked Autoencoders (MAE) play a pivotal role in learning potent representations, delivering outstanding results across various 3D perception tasks essential for autonomous driving. In real-world driving scenarios, it's commonplace to deploy multiple sensors for comprehensive environment perception. While integrating multi-modal features from these sensors can produce rich and powerful features, there is a noticeable gap in MAE methods addressing this integration. This research delves into multi-modal Masked Autoencoders tailored for a unified representation space in autonomous driving, aiming to pioneer a more efficient fusion of two distinct modalities. To intricately marry the semantics inherent in images with the geometric intricacies of LiDAR point clouds, the UniM$^2$AE is proposed. This model stands as a potent yet straightforward, multi-modal self-supervised pre-training framework, mainly consisting of two designs. First, it projects the features from both modalities into a cohesive 3D volume space, ingeniously expanded from the bird's eye view (BEV) to include the height dimension. The extension makes it possible to back-project the informative features, obtained by fusing features from both modalities, into their native modalities to reconstruct the multiple masked inputs. Second, the Multi-modal 3D Interactive Module (MMIM) is invoked to facilitate the efficient inter-modal interaction during the interaction process. Extensive experiments conducted on the nuScenes Dataset attest to the efficacy of UniM$^2$AE, indicating enhancements in 3D object detection and BEV map segmentation by 1.2\%(NDS) and 6.5\% (mIoU), respectively. Code is available at https://github.com/hollow-503/UniM2AE.
Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects
Aug 06, 2023



Camouflaged object detection (COD) is the challenging task of identifying camouflaged objects visually blended into surroundings. Albeit achieving remarkable success, existing COD detectors still struggle to obtain precise results in some challenging cases. To handle this problem, we draw inspiration from the prey-vs-predator game that leads preys to develop better camouflage and predators to acquire more acute vision systems and develop algorithms from both the prey side and the predator side. On the prey side, we propose an adversarial training framework, Camouflageator, which introduces an auxiliary generator to generate more camouflaged objects that are harder for a COD method to detect. Camouflageator trains the generator and detector in an adversarial way such that the enhanced auxiliary generator helps produce a stronger detector. On the predator side, we introduce a novel COD method, called Internal Coherence and Edge Guidance (ICEG), which introduces a camouflaged feature coherence module to excavate the internal coherence of camouflaged objects, striving to obtain more complete segmentation results. Additionally, ICEG proposes a novel edge-guided separated calibration module to remove false predictions to avoid obtaining ambiguous boundaries. Extensive experiments show that ICEG outperforms existing COD detectors and Camouflageator is flexible to improve various COD detectors, including ICEG, which brings state-of-the-art COD performance.