 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients of unitary optical neural networks using parameter-shift rule
Jun 13, 2025This paper explores the application of the parameter-shift rule (PSR) for computing gradients in unitary optical neural networks (UONNs). While backpropagation has been fundamental to training conventional neural networks, its implementation in optical neural networks faces significant challenges due to the physical constraints of optical systems. We demonstrate how PSR, which calculates gradients by evaluating functions at shifted parameter values, can be effectively adapted for training UONNs constructed from Mach-Zehnder interferometer meshes. The method leverages the inherent Fourier series nature of optical interference in these systems to compute exact analytical gradients directly from hardware measurements. This approach offers a promising alternative to traditional in silico training methods and circumvents the limitations of both finite difference approximations and all-optical backpropagation implementations. We present the theoretical framework and practical methodology for applying PSR to optimize phase parameters in optical neural networks, potentially advancing the development of efficient hardware-based training strategies for optical computing systems.
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
Partially Recentralization Softmax Loss for Vision-Language Models Robustness
Feb 06, 2024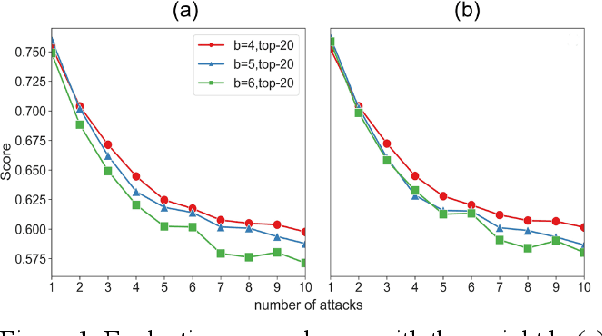
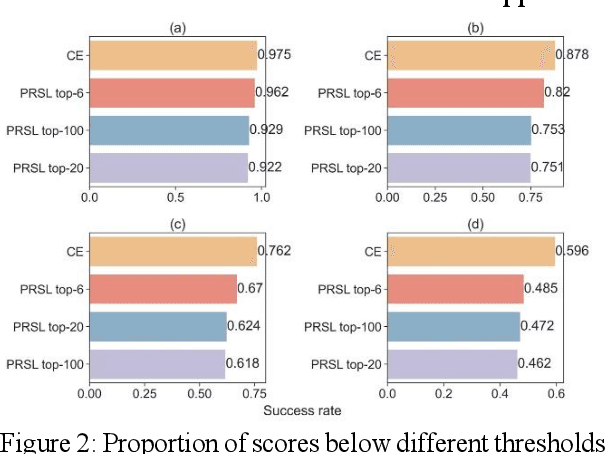
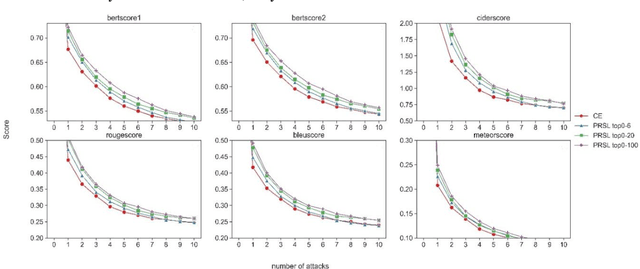
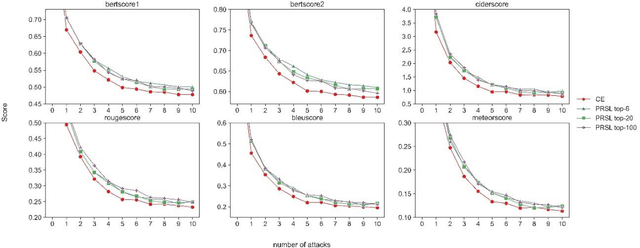
As Large Language Models make a breakthrough in natural language processing tasks (NLP), multimodal technique becomes extremely popular. However, it has been shown that multimodal NLP are vulnerable to adversarial attacks, where the outputs of a model can be dramatically changed by a perturbation to the input. While several defense techniques have been proposed both in computer vision and NLP models, the multimodal robustness of models have not been fully explored. In this paper, we study the adversarial robustness provided by modifying loss function of pre-trained multimodal models, by restricting top K softmax outputs. Based on the evaluation and scoring, our experiments show that after a fine-tuning, adversarial robustness of pre-trained models can be significantly improved, against popular attacks. Further research should be studying, such as output diversity, generalization and the robustness-performance trade-off of this kind of loss functions. Our code will be available after this paper is accepted
Image Content Generation with Causal Reasoning
Dec 12, 2023The emergence of ChatGPT has once again sparked research in generative artificial intelligence (GAI). While people have been amazed by the generated results, they have also noticed the reasoning potential reflected in the generated textual content. However, this current ability for causal reasoning is primarily limited to the domain of language generation, such as in models like GPT-3. In visual modality, there is currently no equivalent research. Considering causal reasoning in visual content generation is significant. This is because visual information contains infinite granularity. Particularly, images can provide more intuitive and specific demonstrations for certain reasoning tasks, especially when compared to coarse-grained text. Hence, we propose a new image generation task called visual question answering with image (VQAI) and establish a dataset of the same name based on the classic \textit{Tom and Jerry} animated series. Additionally, we develop a new paradigm for image generation to tackle the challenges of this task. Finally, we perform extensive experiments and analyses, including visualizations of the generated content and discussions on the potentials and limitations. The code and data are publicly available under the license of CC BY-NC-SA 4.0 for academic and non-commercial usage. The code and dataset are publicly available at: https://github.com/IEIT-AGI/MIX-Shannon/blob/main/projects/VQAI/lgd_vqai.md.
SGED: A Benchmark dataset for Performance Evaluation of Spiking Gesture Emotion Recognition
Apr 28, 2023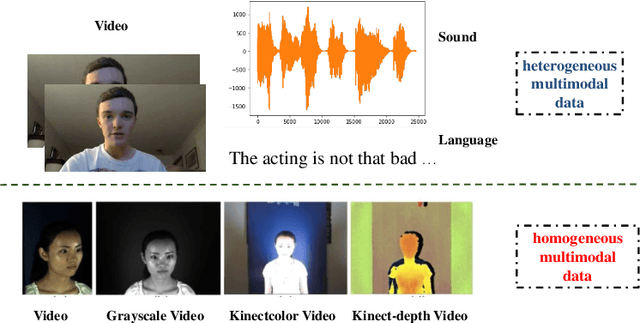
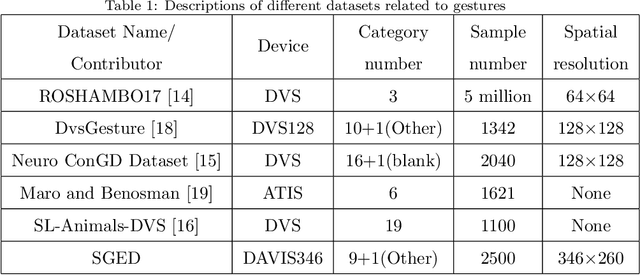

In the field of affective computing, researchers in the community have promoted the performance of models and algorithms by using the complementarity of multimodal information. However, the emergence of more and more modal information makes the development of datasets unable to keep up with the progress of existing modal sensing equipment. Collecting and studying multimodal data is a complex and significant work. In order to supplement the challenge of partial missing of community data. We collected and labeled a new homogeneous multimodal gesture emotion recognition dataset based on the analysis of the existing data sets. This data set complements the defects of homogeneous multimodal data and provides a new research direction for emotion recognition. Moreover, we propose a pseudo dual-flow network based on this dataset, and verify the application potential of this dataset in the affective computing community. The experimental results demonstrate that it is feasible to use the traditional visual information and spiking visual information based on homogeneous multimodal data for visual emotion recognition.The dataset is available at \url{https://github.com/201528014227051/SGED}
Distribution-restrained Softmax Loss for the Model Robustness
Mar 22, 2023



Recently, the robustness of deep learning models has received widespread attention, and various methods for improving model robustness have been proposed, including adversarial training, model architecture modification, design of loss functions, certified defenses, and so on. However, the principle of the robustness to attacks is still not fully understood, also the related research is still not sufficient. Here, we have identified a significant factor that affects the robustness of models: the distribution characteristics of softmax values for non-real label samples. We found that the results after an attack are highly correlated with the distribution characteristics, and thus we proposed a loss function to suppress the distribution diversity of softmax. A large number of experiments have shown that our method can improve robustness without significant time consumption.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Towards interpreting computer vision based on transformation invariant optimization
Jun 18, 2021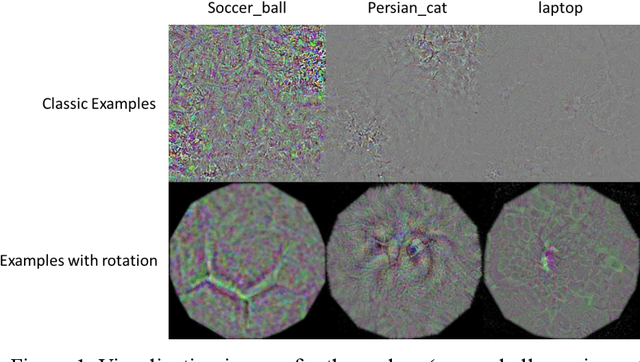
Interpreting how does deep neural networks (DNNs) make predictions is a vital field in artificial intelligence, which hinders wide applications of DNNs. Visualization of learned representations helps we humans understand the vision of DNNs. In this work, visualized images that can activate the neural network to the target classes are generated by back-propagation method. Here, rotation and scaling operations are applied to introduce the transformation invariance in the image generating process, which we find a significant improvement on visualization effect. Finally, we show some cases that such method can help us to gain insight into neural networks.