 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Recentralization Softmax Loss for Vision-Language Models Robustness
Paper and Code
Feb 06, 2024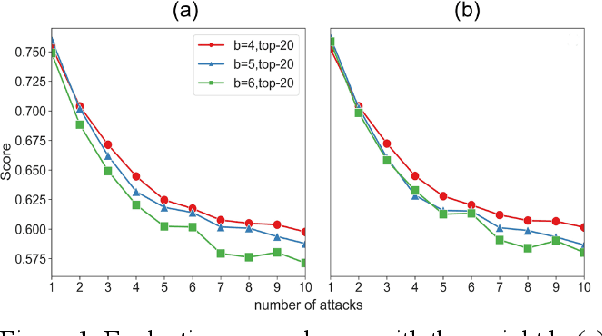
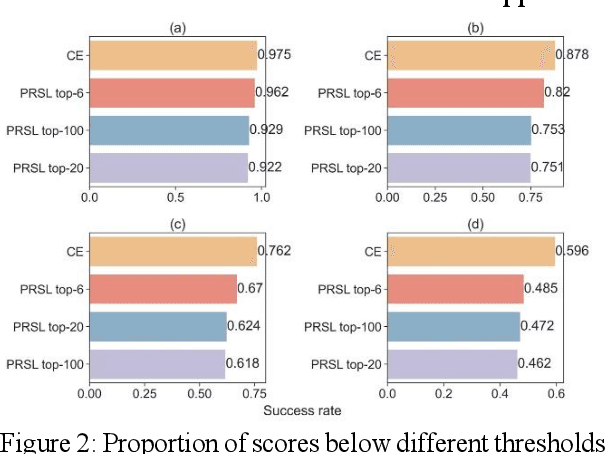
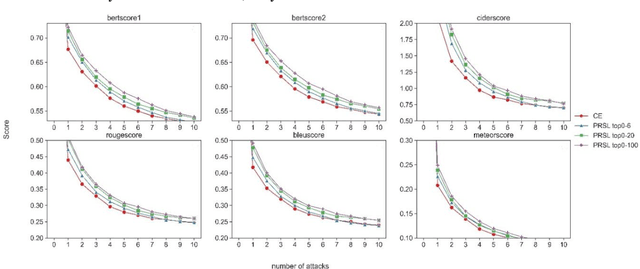
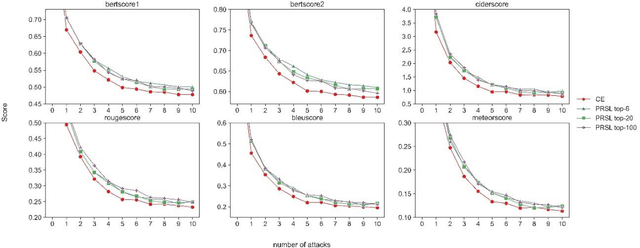
As Large Language Models make a breakthrough in natural language processing tasks (NLP), multimodal technique becomes extremely popular. However, it has been shown that multimodal NLP are vulnerable to adversarial attacks, where the outputs of a model can be dramatically changed by a perturbation to the input. While several defense techniques have been proposed both in computer vision and NLP models, the multimodal robustness of models have not been fully explored. In this paper, we study the adversarial robustness provided by modifying loss function of pre-trained multimodal models, by restricting top K softmax outputs. Based on the evaluation and scoring, our experiments show that after a fine-tuning, adversarial robustness of pre-trained models can be significantly improved, against popular attacks. Further research should be studying, such as output diversity, generalization and the robustness-performance trade-off of this kind of loss functions. Our code will be available after this paper is accepted