 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients of unitary optical neural networks using parameter-shift rule
Jun 13, 2025This paper explores the application of the parameter-shift rule (PSR) for computing gradients in unitary optical neural networks (UONNs). While backpropagation has been fundamental to training conventional neural networks, its implementation in optical neural networks faces significant challenges due to the physical constraints of optical systems. We demonstrate how PSR, which calculates gradients by evaluating functions at shifted parameter values, can be effectively adapted for training UONNs constructed from Mach-Zehnder interferometer meshes. The method leverages the inherent Fourier series nature of optical interference in these systems to compute exact analytical gradients directly from hardware measurements. This approach offers a promising alternative to traditional in silico training methods and circumvents the limitations of both finite difference approximations and all-optical backpropagation implementations. We present the theoretical framework and practical methodology for applying PSR to optimize phase parameters in optical neural networks, potentially advancing the development of efficient hardware-based training strategies for optical computing systems.
Partially Recentralization Softmax Loss for Vision-Language Models Robustness
Feb 06, 2024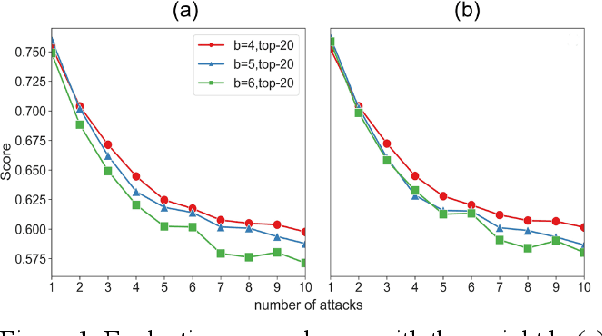
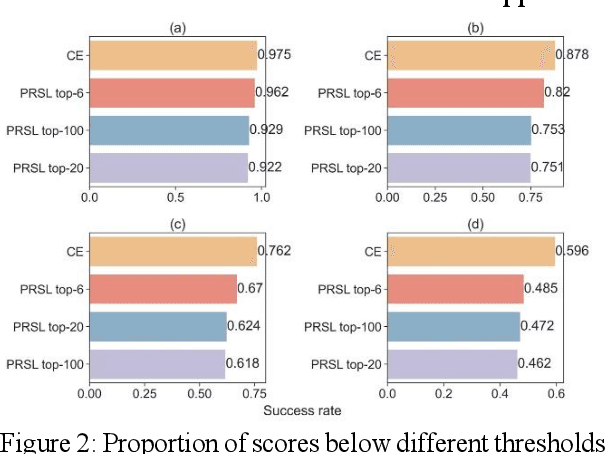
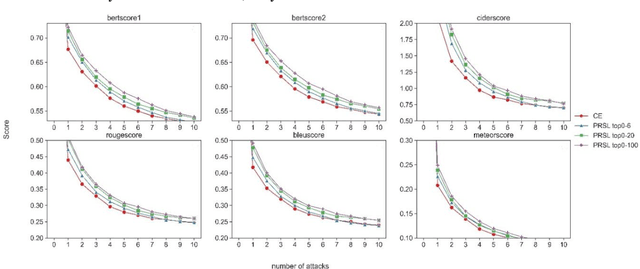
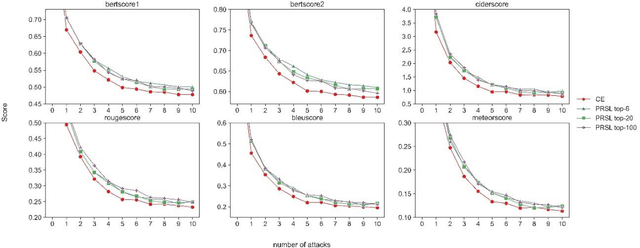
As Large Language Models make a breakthrough in natural language processing tasks (NLP), multimodal technique becomes extremely popular. However, it has been shown that multimodal NLP are vulnerable to adversarial attacks, where the outputs of a model can be dramatically changed by a perturbation to the input. While several defense techniques have been proposed both in computer vision and NLP models, the multimodal robustness of models have not been fully explored. In this paper, we study the adversarial robustness provided by modifying loss function of pre-trained multimodal models, by restricting top K softmax outputs. Based on the evaluation and scoring, our experiments show that after a fine-tuning, adversarial robustness of pre-trained models can be significantly improved, against popular attacks. Further research should be studying, such as output diversity, generalization and the robustness-performance trade-off of this kind of loss functions. Our code will be available after this paper is accepted
Distribution-restrained Softmax Loss for the Model Robustness
Mar 22, 2023



Recently, the robustness of deep learning models has received widespread attention, and various methods for improving model robustness have been proposed, including adversarial training, model architecture modification, design of loss functions, certified defenses, and so on. However, the principle of the robustness to attacks is still not fully understood, also the related research is still not sufficient. Here, we have identified a significant factor that affects the robustness of models: the distribution characteristics of softmax values for non-real label samples. We found that the results after an attack are highly correlated with the distribution characteristics, and thus we proposed a loss function to suppress the distribution diversity of softmax. A large number of experiments have shown that our method can improve robustness without significant time consumption.
Towards interpreting computer vision based on transformation invariant optimization
Jun 18, 2021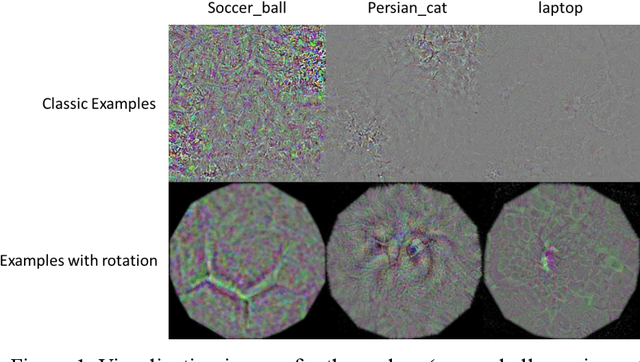
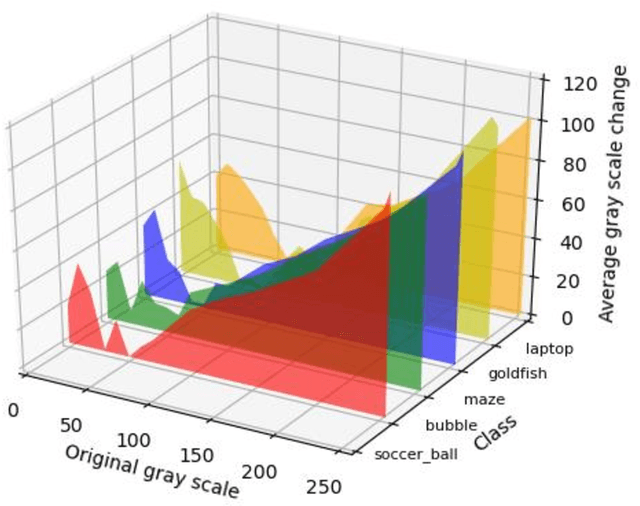
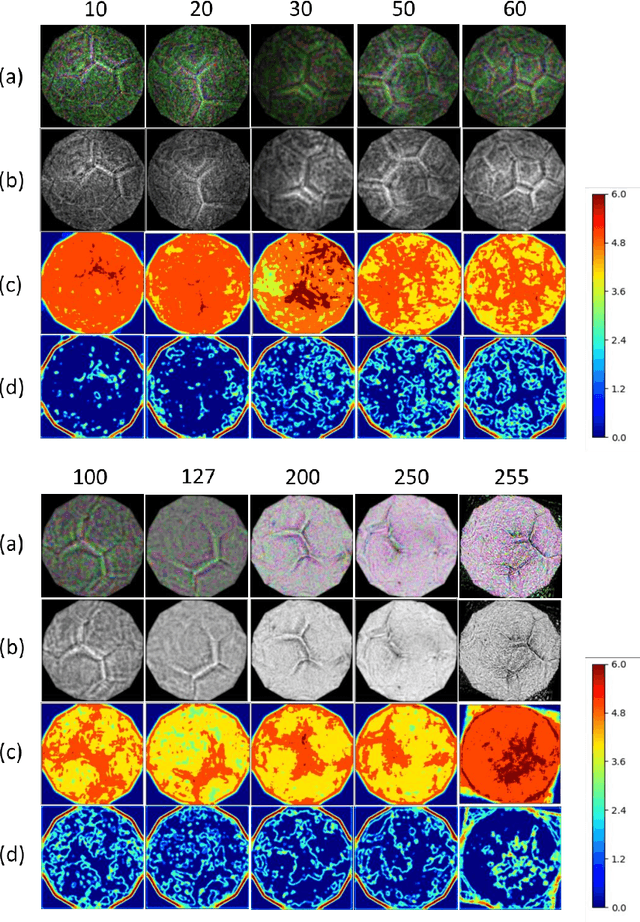
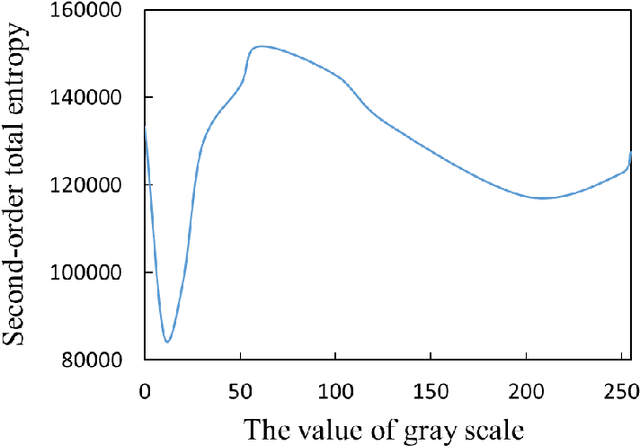
Interpreting how does deep neural networks (DNNs) make predictions is a vital field in artificial intelligence, which hinders wide applications of DNNs. Visualization of learned representations helps we humans understand the vision of DNNs. In this work, visualized images that can activate the neural network to the target classes are generated by back-propagation method. Here, rotation and scaling operations are applied to introduce the transformation invariance in the image generating process, which we find a significant improvement on visualization effect. Finally, we show some cases that such method can help us to gain insight into neural networks.