 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
BroadTrack: Broadcast Camera Tracking for Soccer
Dec 02, 2024Camera calibration and localization, sometimes simply named camera calibration, enables many applications in the context of soccer broadcasting, for instance regarding the interpretation and analysis of the game, or the insertion of augmented reality graphics for storytelling or refereeing purposes. To contribute to such applications, the research community has typically focused on single-view calibration methods, leveraging the near-omnipresence of soccer field markings in wide-angle broadcast views, but leaving all temporal aspects, if considered at all, to general-purpose tracking or filtering techniques. Only a few contributions have been made to leverage any domain-specific knowledge for this tracking task, and, as a result, there lacks a truly performant and off-the-shelf camera tracking system tailored for soccer broadcasting, specifically for elevated tripod-mounted cameras around the stadium. In this work, we present such a system capable of addressing the task of soccer broadcast camera tracking efficiently, robustly, and accurately, outperforming by far the most precise methods of the state-of-the-art. By combining the available open-source soccer field detectors with carefully designed camera and tripod models, our tracking system, BroadTrack, halves the mean reprojection error rate and gains more than 15% in terms of Jaccard index for camera calibration on the SoccerNet dataset. Furthermore, as the SoccerNet dataset videos are relatively short (30 seconds), we also present qualitative results on a 20-minute broadcast clip to showcase the robustness and the soundness of our system.
SoccerNet 2024 Challenges Results
Sep 16, 2024

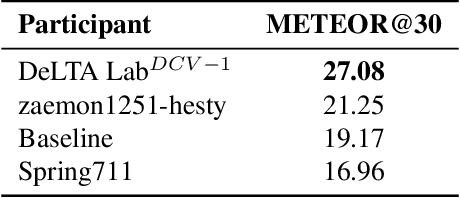
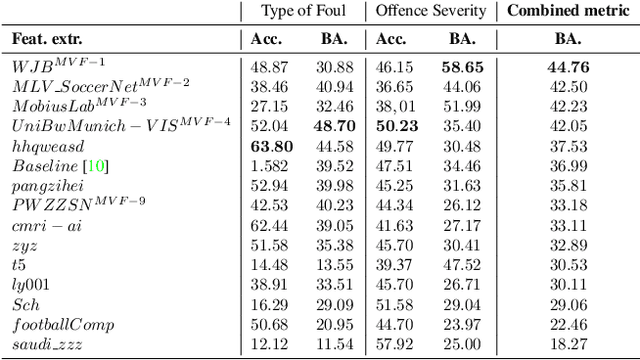
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
A Universal Protocol to Benchmark Camera Calibration for Sports
Apr 15, 2024Camera calibration is a crucial component in the realm of sports analytics, as it serves as the foundation to extract 3D information out of the broadcast images. Despite the significance of camera calibration research in sports analytics, progress is impeded by outdated benchmarking criteria. Indeed, the annotation data and evaluation metrics provided by most currently available benchmarks strongly favor and incite the development of sports field registration methods, i.e. methods estimating homographies that map the sports field plane to the image plane. However, such homography-based methods are doomed to overlook the broader capabilities of camera calibration in bridging the 3D world to the image. In particular, real-world non-planar sports field elements (such as goals, corner flags, baskets, ...) and image distortion caused by broadcast camera lenses are out of the scope of sports field registration methods. To overcome these limitations, we designed a new benchmarking protocol, named ProCC, based on two principles: (1) the protocol should be agnostic to the camera model chosen for a camera calibration method, and (2) the protocol should fairly evaluate camera calibration methods using the reprojection of arbitrary yet accurately known 3D objects. Indirectly, we also provide insights into the metric used in SoccerNet-calibration, which solely relies on image annotation data of viewed 3D objects as ground truth, thus implementing our protocol. With experiments on the World Cup 2014, CARWC, and SoccerNet datasets, we show that our benchmarking protocol provides fairer evaluations of camera calibration methods. By defining our requirements for proper benchmarking, we hope to pave the way for a new stage in camera calibration for sports applications with high accuracy standards.
Dynamic NeRFs for Soccer Scenes
Sep 13, 2023The long-standing problem of novel view synthesis has many applications, notably in sports broadcasting. Photorealistic novel view synthesis of soccer actions, in particular, is of enormous interest to the broadcast industry. Yet only a few industrial solutions have been proposed, and even fewer that achieve near-broadcast quality of the synthetic replays. Except for their setup of multiple static cameras around the playfield, the best proprietary systems disclose close to no information about their inner workings. Leveraging multiple static cameras for such a task indeed presents a challenge rarely tackled in the literature, for a lack of public datasets: the reconstruction of a large-scale, mostly static environment, with small, fast-moving elements. Recently, the emergence of neural radiance fields has induced stunning progress in many novel view synthesis applications, leveraging deep learning principles to produce photorealistic results in the most challenging settings. In this work, we investigate the feasibility of basing a solution to the task on dynamic NeRFs, i.e., neural models purposed to reconstruct general dynamic content. We compose synthetic soccer environments and conduct multiple experiments using them, identifying key components that help reconstruct soccer scenes with dynamic NeRFs. We show that, although this approach cannot fully meet the quality requirements for the target application, it suggests promising avenues toward a cost-efficient, automatic solution. We also make our work dataset and code publicly available, with the goal to encourage further efforts from the research community on the task of novel view synthesis for dynamic soccer scenes. For code, data, and video results, please see https://soccernerfs.isach.be.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Camera Calibration and Player Localization in SoccerNet-v2 and Investigation of their Representations for Action Spotting
Apr 19, 2021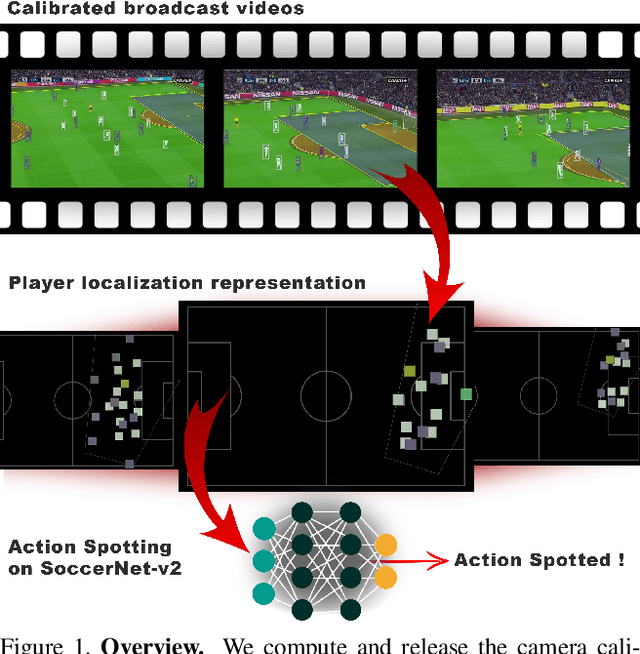

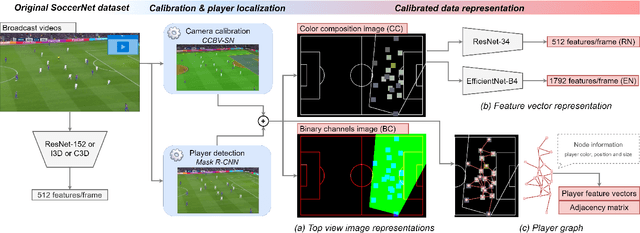
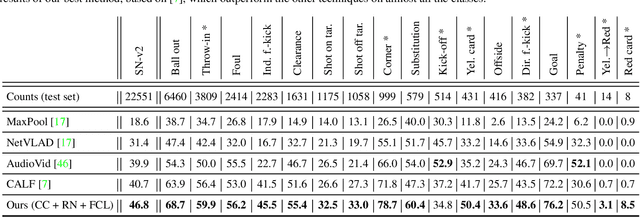
Soccer broadcast video understanding has been drawing a lot of attention in recent years within data scientists and industrial companies. This is mainly due to the lucrative potential unlocked by effective deep learning techniques developed in the field of computer vision. In this work, we focus on the topic of camera calibration and on its current limitations for the scientific community. More precisely, we tackle the absence of a large-scale calibration dataset and of a public calibration network trained on such a dataset. Specifically, we distill a powerful commercial calibration tool in a recent neural network architecture on the large-scale SoccerNet dataset, composed of untrimmed broadcast videos of 500 soccer games. We further release our distilled network, and leverage it to provide 3 ways of representing the calibration results along with player localization. Finally, we exploit those representations within the current best architecture for the action spotting task of SoccerNet-v2, and achieve new state-of-the-art performances.