 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Block-Diagonal Coupling for Resource-Efficient Training of Vision Models
May 22, 2026Training high-capacity vision models from scratch requires substantial computational resources. To improve training efficiency of a wide target model, existing growth methods often assume the availability of narrower models, obscuring the true computational cost of the entire pipeline. We propose an efficient training protocol, RBDC, that builds wide models by coupling in a parameter-free block-diagonal way narrower, independently trained models in a recursive way. This allows a flexible allocation of the training budget available across all the models involved. Evaluated with vision transformers (DeiT) and convolutional networks (ResNet) on ImageNet, our RBDC training protocol shows a much better efficiency than models trained from scratch with the standard protocol, yielding 30% FLOPs reduction at similar test accuracies. It also achieves higher performances at same training FLOPs than training protocols from the model growth literature. Finally, we show that our models can serve as better backbones than their original counterparts for downstream object detection and instance segmentation tasks.
Towards Athlete Fatigue Assessment from Association Football Videos
Apr 07, 2026Fatigue monitoring is central in association football due to its links with injury risk and tactical performance. However, objective fatigue-related indicators are commonly derived from subjective self-reported metrics, biomarkers derived from laboratory tests, or, more recently, intrusive sensors such as heart monitors or GPS tracking data. This paper studies whether monocular broadcast videos can provide spatio-temporal signals of sufficient quality to support fatigue-oriented analysis. Building on state-of-the-art Game State Reconstruction methods, we extract player trajectories in pitch coordinates and propose a novel kinematics processing algorithm to obtain temporally consistent speed and acceleration estimates from reconstructed tracks. We then construct acceleration--speed (A-S) profiles from these signals and analyze their behavior as fatigue-related performance indicators. We evaluate the full pipeline on the public SoccerNet-GSR benchmark, considering both 30-second clips and a complete 45-minute half to examine short-term reliability and longer-term temporal consistency. Our results indicate that monocular GSR can recover kinematic patterns that are compatible with A-S profiling while also revealing sensitivity to trajectory noise, calibration errors, and temporal discontinuities inherent to broadcast footage. These findings support monocular broadcast video as a low-cost basis for fatigue analysis and delineate the methodological challenges for future research.
TrackMAE: Video Representation Learning via Track Mask and Predict
Mar 28, 2026Masked video modeling (MVM) has emerged as a simple and scalable self-supervised pretraining paradigm, but only encodes motion information implicitly, limiting the encoding of temporal dynamics in the learned representations. As a result, such models struggle on motion-centric tasks that require fine-grained motion awareness. To address this, we propose TrackMAE, a simple masked video modeling paradigm that explicitly uses motion information as a reconstruction signal. In TrackMAE, we use an off-the-shelf point tracker to sparsely track points in the input videos, generating motion trajectories. Furthermore, we exploit the extracted trajectories to improve random tube masking with a motion-aware masking strategy. We enhance video representations learned in both pixel and feature semantic reconstruction spaces by providing a complementary supervision signal in the form of motion targets. We evaluate on six datasets across diverse downstream settings and find that TrackMAE consistently outperforms state-of-the-art video self-supervised learning baselines, learning more discriminative and generalizable representations. Code available at https://github.com/rvandeghen/TrackMAE
Nexels: Neurally-Textured Surfels for Real-Time Novel View Synthesis with Sparse Geometries
Dec 15, 2025Though Gaussian splatting has achieved impressive results in novel view synthesis, it requires millions of primitives to model highly textured scenes, even when the geometry of the scene is simple. We propose a representation that goes beyond point-based rendering and decouples geometry and appearance in order to achieve a compact representation. We use surfels for geometry and a combination of a global neural field and per-primitive colours for appearance. The neural field textures a fixed number of primitives for each pixel, ensuring that the added compute is low. Our representation matches the perceptual quality of 3D Gaussian splatting while using $9.7\times$ fewer primitives and $5.5\times$ less memory on outdoor scenes and using $31\times$ fewer primitives and $3.7\times$ less memory on indoor scenes. Our representation also renders twice as fast as existing textured primitives while improving upon their visual quality.
Multi-domain performance analysis with scores tailored to user preferences
Dec 09, 2025The performance of algorithms, methods, and models tends to depend heavily on the distribution of cases on which they are applied, this distribution being specific to the applicative domain. After performing an evaluation in several domains, it is highly informative to compute a (weighted) mean performance and, as shown in this paper, to scrutinize what happens during this averaging. To achieve this goal, we adopt a probabilistic framework and consider a performance as a probability measure (e.g., a normalized confusion matrix for a classification task). It appears that the corresponding weighted mean is known to be the summarization, and that only some remarkable scores assign to the summarized performance a value equal to a weighted arithmetic mean of the values assigned to the domain-specific performances. These scores include the family of ranking scores, a continuum parameterized by user preferences, and that the weights to consider in the arithmetic mean depend on the user preferences. Based on this, we rigorously define four domains, named easiest, most difficult, preponderant, and bottleneck domains, as functions of user preferences. After establishing the theory in a general setting, regardless of the task, we develop new visual tools for two-class classification.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Triangle Splatting for Real-Time Radiance Field Rendering
May 25, 2025



The field of computer graphics was revolutionized by models such as Neural Radiance Fields and 3D Gaussian Splatting, displacing triangles as the dominant representation for photogrammetry. In this paper, we argue for a triangle comeback. We develop a differentiable renderer that directly optimizes triangles via end-to-end gradients. We achieve this by rendering each triangle as differentiable splats, combining the efficiency of triangles with the adaptive density of representations based on independent primitives. Compared to popular 2D and 3D Gaussian Splatting methods, our approach achieves higher visual fidelity, faster convergence, and increased rendering throughput. On the Mip-NeRF360 dataset, our method outperforms concurrent non-volumetric primitives in visual fidelity and achieves higher perceptual quality than the state-of-the-art Zip-NeRF on indoor scenes. Triangles are simple, compatible with standard graphics stacks and GPU hardware, and highly efficient: for the \textit{Garden} scene, we achieve over 2,400 FPS at 1280x720 resolution using an off-the-shelf mesh renderer. These results highlight the efficiency and effectiveness of triangle-based representations for high-quality novel view synthesis. Triangles bring us closer to mesh-based optimization by combining classical computer graphics with modern differentiable rendering frameworks. The project page is https://trianglesplatting.github.io/
A Methodology to Evaluate Strategies Predicting Rankings on Unseen Domains
May 21, 2025


Frequently, multiple entities (methods, algorithms, procedures, solutions, etc.) can be developed for a common task and applied across various domains that differ in the distribution of scenarios encountered. For example, in computer vision, the input data provided to image analysis methods depend on the type of sensor used, its location, and the scene content. However, a crucial difficulty remains: can we predict which entities will perform best in a new domain based on assessments on known domains, without having to carry out new and costly evaluations? This paper presents an original methodology to address this question, in a leave-one-domain-out fashion, for various application-specific preferences. We illustrate its use with 30 strategies to predict the rankings of 40 entities (unsupervised background subtraction methods) on 53 domains (videos).
Action Anticipation from SoccerNet Football Video Broadcasts
Apr 16, 2025Artificial intelligence has revolutionized the way we analyze sports videos, whether to understand the actions of games in long untrimmed videos or to anticipate the player's motion in future frames. Despite these efforts, little attention has been given to anticipating game actions before they occur. In this work, we introduce the task of action anticipation for football broadcast videos, which consists in predicting future actions in unobserved future frames, within a five- or ten-second anticipation window. To benchmark this task, we release a new dataset, namely the SoccerNet Ball Action Anticipation dataset, based on SoccerNet Ball Action Spotting. Additionally, we propose a Football Action ANticipation TRAnsformer (FAANTRA), a baseline method that adapts FUTR, a state-of-the-art action anticipation model, to predict ball-related actions. To evaluate action anticipation, we introduce new metrics, including mAP@$\delta$, which evaluates the temporal precision of predicted future actions, as well as mAP@$\infty$, which evaluates their occurrence within the anticipation window. We also conduct extensive ablation studies to examine the impact of various task settings, input configurations, and model architectures. Experimental results highlight both the feasibility and challenges of action anticipation in football videos, providing valuable insights into the design of predictive models for sports analytics. By forecasting actions before they unfold, our work will enable applications in automated broadcasting, tactical analysis, and player decision-making. Our dataset and code are publicly available at https://github.com/MohamadDalal/FAANTRA.
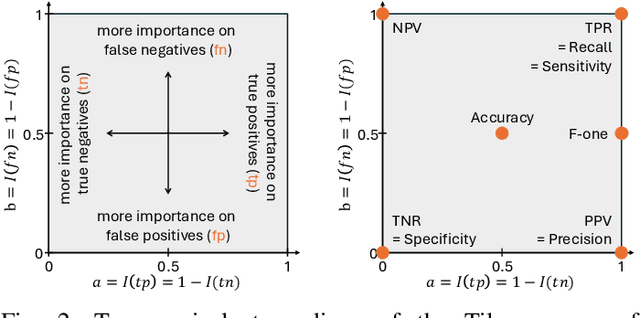
A Hitchhiker's Guide to Understanding Performances of Two-Class Classifiers
Dec 05, 2024Properly understanding the performances of classifiers is essential in various scenarios. However, the literature often relies only on one or two standard scores to compare classifiers, which fails to capture the nuances of application-specific requirements, potentially leading to suboptimal classifier selection. Recently, a paper on the foundations of the theory of performance-based ranking introduced a tool, called the Tile, that organizes an infinity of ranking scores into a 2D map. Thanks to the Tile, it is now possible to evaluate and compare classifiers efficiently, displaying all possible application-specific preferences instead of having to rely on a pair of scores. In this paper, we provide a first hitchhiker's guide for understanding the performances of two-class classifiers by presenting four scenarios, each showcasing a different user profile: a theoretical analyst, a method designer, a benchmarker, and an application developer. Particularly, we show that we can provide different interpretative flavors that are adapted to the user's needs by mapping different values on the Tile. As an illustration, we leverage the newly introduced Tile tool and the different flavors to rank and analyze the performances of 74 state-of-the-art semantic segmentation models in two-class classification through the eyes of the four user profiles. Through these user profiles, we demonstrate that the Tile effectively captures the behavior of classifiers in a single visualization, while accommodating an infinite number of ranking scores.