 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-domain performance analysis with scores tailored to user preferences
Dec 09, 2025The performance of algorithms, methods, and models tends to depend heavily on the distribution of cases on which they are applied, this distribution being specific to the applicative domain. After performing an evaluation in several domains, it is highly informative to compute a (weighted) mean performance and, as shown in this paper, to scrutinize what happens during this averaging. To achieve this goal, we adopt a probabilistic framework and consider a performance as a probability measure (e.g., a normalized confusion matrix for a classification task). It appears that the corresponding weighted mean is known to be the summarization, and that only some remarkable scores assign to the summarized performance a value equal to a weighted arithmetic mean of the values assigned to the domain-specific performances. These scores include the family of ranking scores, a continuum parameterized by user preferences, and that the weights to consider in the arithmetic mean depend on the user preferences. Based on this, we rigorously define four domains, named easiest, most difficult, preponderant, and bottleneck domains, as functions of user preferences. After establishing the theory in a general setting, regardless of the task, we develop new visual tools for two-class classification.
A Methodology to Evaluate Strategies Predicting Rankings on Unseen Domains
May 21, 2025


Frequently, multiple entities (methods, algorithms, procedures, solutions, etc.) can be developed for a common task and applied across various domains that differ in the distribution of scenarios encountered. For example, in computer vision, the input data provided to image analysis methods depend on the type of sensor used, its location, and the scene content. However, a crucial difficulty remains: can we predict which entities will perform best in a new domain based on assessments on known domains, without having to carry out new and costly evaluations? This paper presents an original methodology to address this question, in a leave-one-domain-out fashion, for various application-specific preferences. We illustrate its use with 30 strategies to predict the rankings of 40 entities (unsupervised background subtraction methods) on 53 domains (videos).
A Hitchhiker's Guide to Understanding Performances of Two-Class Classifiers
Dec 05, 2024Properly understanding the performances of classifiers is essential in various scenarios. However, the literature often relies only on one or two standard scores to compare classifiers, which fails to capture the nuances of application-specific requirements, potentially leading to suboptimal classifier selection. Recently, a paper on the foundations of the theory of performance-based ranking introduced a tool, called the Tile, that organizes an infinity of ranking scores into a 2D map. Thanks to the Tile, it is now possible to evaluate and compare classifiers efficiently, displaying all possible application-specific preferences instead of having to rely on a pair of scores. In this paper, we provide a first hitchhiker's guide for understanding the performances of two-class classifiers by presenting four scenarios, each showcasing a different user profile: a theoretical analyst, a method designer, a benchmarker, and an application developer. Particularly, we show that we can provide different interpretative flavors that are adapted to the user's needs by mapping different values on the Tile. As an illustration, we leverage the newly introduced Tile tool and the different flavors to rank and analyze the performances of 74 state-of-the-art semantic segmentation models in two-class classification through the eyes of the four user profiles. Through these user profiles, we demonstrate that the Tile effectively captures the behavior of classifiers in a single visualization, while accommodating an infinite number of ranking scores.
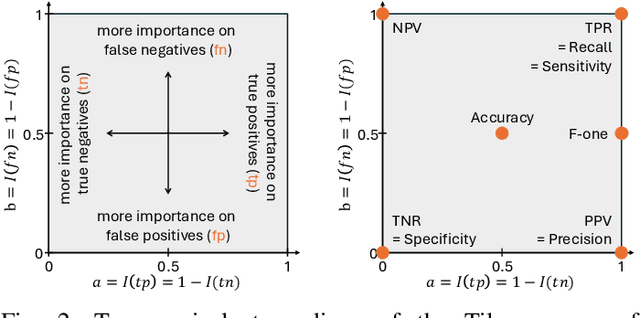
The Tile: A 2D Map of Ranking Scores for Two-Class Classification
Dec 05, 2024



In the computer vision and machine learning communities, as well as in many other research domains, rigorous evaluation of any new method, including classifiers, is essential. One key component of the evaluation process is the ability to compare and rank methods. However, ranking classifiers and accurately comparing their performances, especially when taking application-specific preferences into account, remains challenging. For instance, commonly used evaluation tools like Receiver Operating Characteristic (ROC) and Precision/Recall (PR) spaces display performances based on two scores. Hence, they are inherently limited in their ability to compare classifiers across a broader range of scores and lack the capability to establish a clear ranking among classifiers. In this paper, we present a novel versatile tool, named the Tile, that organizes an infinity of ranking scores in a single 2D map for two-class classifiers, including common evaluation scores such as the accuracy, the true positive rate, the positive predictive value, Jaccard's coefficient, and all F-beta scores. Furthermore, we study the properties of the underlying ranking scores, such as the influence of the priors or the correspondences with the ROC space, and depict how to characterize any other score by comparing them to the Tile. Overall, we demonstrate that the Tile is a powerful tool that effectively captures all the rankings in a single visualization and allows interpreting them.
Foundations of the Theory of Performance-Based Ranking
Dec 05, 2024
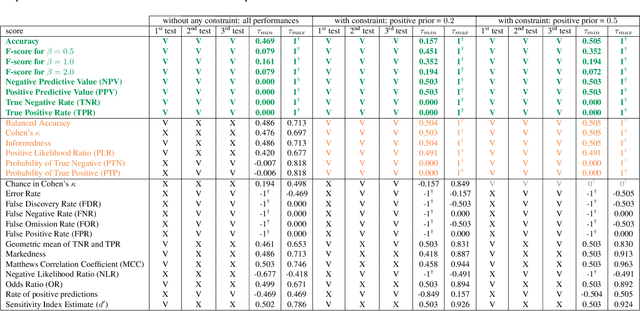
Ranking entities such as algorithms, devices, methods, or models based on their performances, while accounting for application-specific preferences, is a challenge. To address this challenge, we establish the foundations of a universal theory for performance-based ranking. First, we introduce a rigorous framework built on top of both the probability and order theories. Our new framework encompasses the elements necessary to (1) manipulate performances as mathematical objects, (2) express which performances are worse than or equivalent to others, (3) model tasks through a variable called satisfaction, (4) consider properties of the evaluation, (5) define scores, and (6) specify application-specific preferences through a variable called importance. On top of this framework, we propose the first axiomatic definition of performance orderings and performance-based rankings. Then, we introduce a universal parametric family of scores, called ranking scores, that can be used to establish rankings satisfying our axioms, while considering application-specific preferences. Finally, we show, in the case of two-class classification, that the family of ranking scores encompasses well-known performance scores, including the accuracy, the true positive rate (recall, sensitivity), the true negative rate (specificity), the positive predictive value (precision), and F1. However, we also show that some other scores commonly used to compare classifiers are unsuitable to derive performance orderings satisfying the axioms. Therefore, this paper provides the computer vision and machine learning communities with a rigorous framework for evaluating and ranking entities.
Physically Interpretable Probabilistic Domain Characterization
Nov 22, 2024Characterizing domains is essential for models analyzing dynamic environments, as it allows them to adapt to evolving conditions or to hand the task over to backup systems when facing conditions outside their operational domain. Existing solutions typically characterize a domain by solving a regression or classification problem, which limits their applicability as they only provide a limited summarized description of the domain. In this paper, we present a novel approach to domain characterization by characterizing domains as probability distributions. Particularly, we develop a method to predict the likelihood of different weather conditions from images captured by vehicle-mounted cameras by estimating distributions of physical parameters using normalizing flows. To validate our proposed approach, we conduct experiments within the context of autonomous vehicles, focusing on predicting the distribution of weather parameters to characterize the operational domain. This domain is characterized by physical parameters (absolute characterization) and arbitrarily predefined domains (relative characterization). Finally, we evaluate whether a system can safely operate in a target domain by comparing it to multiple source domains where safety has already been established. This approach holds significant potential, as accurate weather prediction and effective domain adaptation are crucial for autonomous systems to adjust to dynamic environmental conditions.
Mixture Domain Adaptation to Improve Semantic Segmentation in Real-World Surveillance
Nov 18, 2022Various tasks encountered in real-world surveillance can be addressed by determining posteriors (e.g. by Bayesian inference or machine learning), based on which critical decisions must be taken. However, the surveillance domain (acquisition device, operating conditions, etc.) is often unknown, which prevents any possibility of scene-specific optimization. In this paper, we define a probabilistic framework and present a formal proof of an algorithm for the unsupervised many-to-infinity domain adaptation of posteriors. Our proposed algorithm is applicable when the probability measure associated with the target domain is a convex combination of the probability measures of the source domains. It makes use of source models and a domain discriminator model trained off-line to compute posteriors adapted on the fly to the target domain. Finally, we show the effectiveness of our algorithm for the task of semantic segmentation in real-world surveillance. The code is publicly available at https://github.com/rvandeghen/MDA.
An exploration of the performances achievable by combining unsupervised background subtraction algorithms
Feb 25, 2022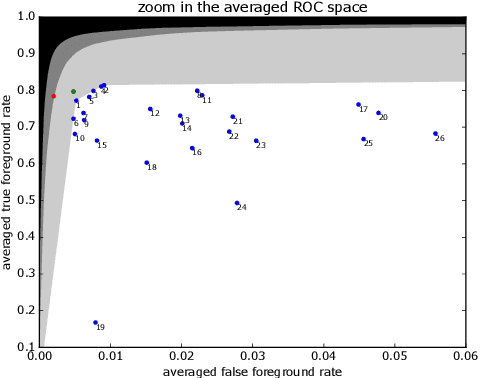
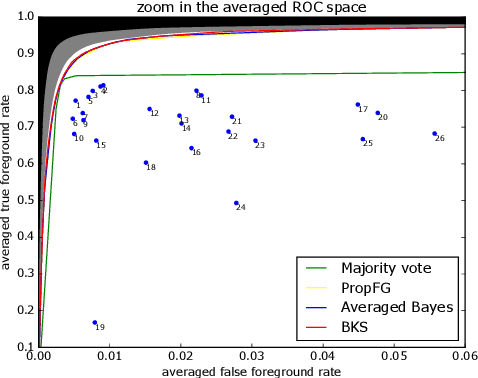
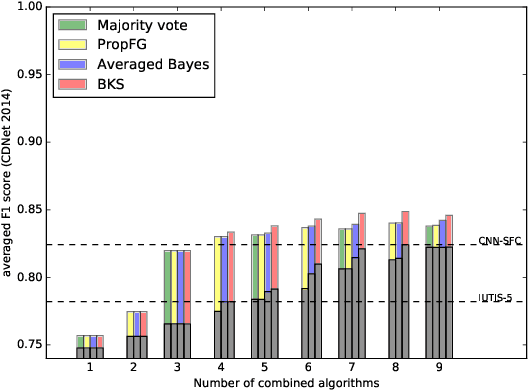
Background subtraction (BGS) is a common choice for performing motion detection in video. Hundreds of BGS algorithms are released every year, but combining them to detect motion remains largely unexplored. We found that combination strategies allow to capitalize on this massive amount of available BGS algorithms, and offer significant space for performance improvement. In this paper, we explore sets of performances achievable by 6 strategies combining, pixelwise, the outputs of 26 unsupervised BGS algorithms, on the CDnet 2014 dataset, both in the ROC space and in terms of the F1 score. The chosen strategies are representative for a large panel of strategies, including both deterministic and non-deterministic ones, voting and learning. In our experiments, we compare our results with the state-of-the-art combinations IUTIS-5 and CNN-SFC, and report six conclusions, among which the existence of an important gap between the performances of the individual algorithms and the best performances achievable by combining them.
Summarizing the performances of a background subtraction algorithm measured on several videos
Feb 13, 2020
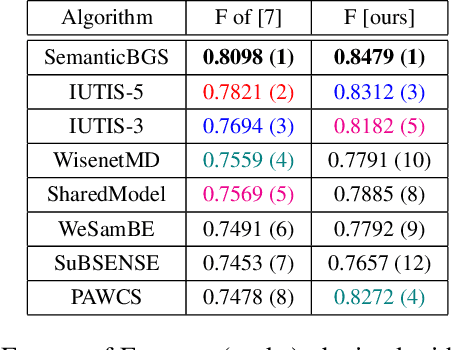
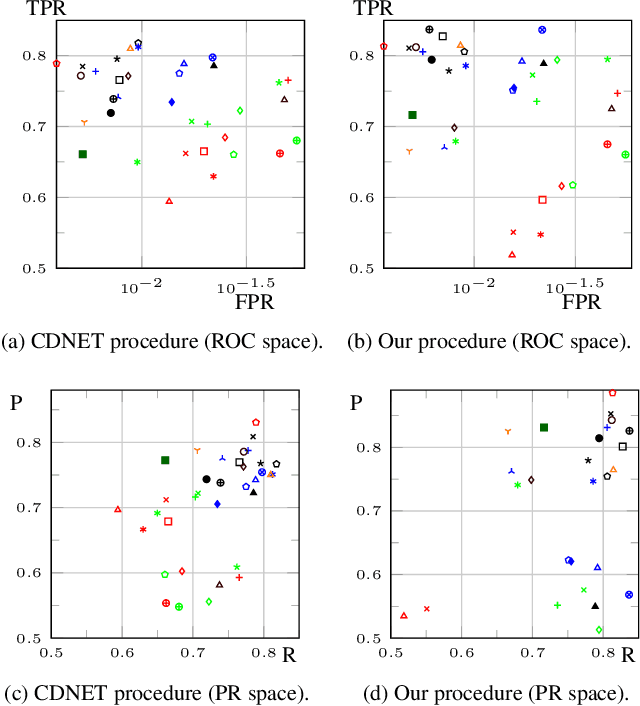
There exist many background subtraction algorithms to detect motion in videos. To help comparing them, datasets with ground-truth data such as CDNET or LASIESTA have been proposed. These datasets organize videos in categories that represent typical challenges for background subtraction. The evaluation procedure promoted by their authors consists in measuring performance indicators for each video separately and to average them hierarchically, within a category first, then between categories, a procedure which we name "summarization". While the summarization by averaging performance indicators is a valuable effort to standardize the evaluation procedure, it has no theoretical justification and it breaks the intrinsic relationships between summarized indicators. This leads to interpretation inconsistencies. In this paper, we present a theoretical approach to summarize the performances for multiple videos that preserves the relationships between performance indicators. In addition, we give formulas and an algorithm to calculate summarized performances. Finally, we showcase our observations on CDNET 2014.