 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Random Fields for Interactive Refinement of Histopathological Predictions
Jan 17, 2026Assisting pathologists in the analysis of histopathological images has high clinical value, as it supports cancer detection and staging. In this context, histology foundation models have recently emerged. Among them, Vision-Language Models (VLMs) provide strong yet imperfect zero-shot predictions. We propose to refine these predictions by adapting Conditional Random Fields (CRFs) to histopathological applications, requiring no additional model training. We present HistoCRF, a CRF-based framework, with a novel definition of the pairwise potential that promotes label diversity and leverages expert annotations. We consider three experiments: without annotations, with expert annotations, and with iterative human-in-the-loop annotations that progressively correct misclassified patches. Experiments on five patch-level classification datasets covering different organs and diseases demonstrate average accuracy gains of 16.0% without annotations and 27.5% with only 100 annotations, compared to zero-shot predictions. Moreover, integrating a human in the loop reaches a further gain of 32.6% with the same number of annotations. The code will be made available on https://github.com/tgodelaine/HistoCRF.
Leveraging Prediction Entropy for Automatic Prompt Weighting in Zero-Shot Audio-Language Classification
Jan 08, 2026Audio-language models have recently demonstrated strong zero-shot capabilities by leveraging natural-language supervision to classify audio events without labeled training data. Yet, their performance is highly sensitive to the wording of text prompts, with small variations leading to large fluctuations in accuracy. Prior work has mitigated this issue through prompt learning or prompt ensembling. However, these strategies either require annotated data or fail to account for the fact that some prompts may negatively impact performance. In this work, we present an entropy-guided prompt weighting approach that aims to find a robust combination of prompt contributions to maximize prediction confidence. To this end, we formulate a tailored objective function that minimizes prediction entropy to yield new prompt weights, utilizing low-entropy as a proxy for high confidence. Our approach can be applied to individual samples or a batch of audio samples, requiring no additional labels and incurring negligible computational overhead. Experiments on five audio classification datasets covering environmental, urban, and vocal sounds, demonstrate consistent gains compared to classical prompt ensembling methods in a zero-shot setting, with accuracy improvements 5-times larger across the whole benchmark.
Few-Shot Adaptation Benchmark for Remote Sensing Vision-Language Models
Oct 08, 2025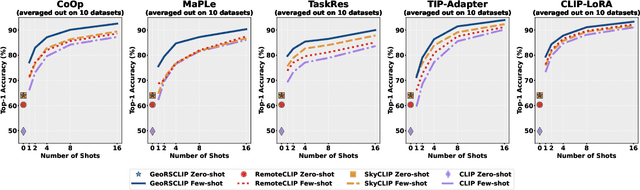



Remote Sensing Vision-Language Models (RSVLMs) have shown remarkable potential thanks to large-scale pretraining, achieving strong zero-shot performance on various tasks. However, their ability to generalize in low-data regimes, such as few-shot learning, remains insufficiently explored. In this work, we present the first structured benchmark for evaluating few-shot adaptation methods on RSVLMs. We conduct comprehensive experiments across ten remote sensing scene classification datasets, applying five widely used few-shot adaptation strategies to three state-of-the-art RSVLMs with varying backbones. Our findings reveal that models with similar zero-shot performance can exhibit markedly different behavior under few-shot adaptation, with some RSVLMs being inherently more amenable to such adaptation than others. The variability of performance and the absence of a clear winner among existing methods highlight the need for the development of more robust methods for few-shot adaptation tailored to RS. To facilitate future research, we provide a reproducible benchmarking framework and open-source code to systematically evaluate RSVLMs under few-shot conditions. The source code is publicly available on Github: https://github.com/elkhouryk/fewshot_RSVLMs
Vocabulary-free few-shot learning for Vision-Language Models
Jun 04, 2025Recent advances in few-shot adaptation for Vision-Language Models (VLMs) have greatly expanded their ability to generalize across tasks using only a few labeled examples. However, existing approaches primarily build upon the strong zero-shot priors of these models by leveraging carefully designed, task-specific prompts. This dependence on predefined class names can restrict their applicability, especially in scenarios where exact class names are unavailable or difficult to specify. To address this limitation, we introduce vocabulary-free few-shot learning for VLMs, a setting where target class instances - that is, images - are available but their corresponding names are not. We propose Similarity Mapping (SiM), a simple yet effective baseline that classifies target instances solely based on similarity scores with a set of generic prompts (textual or visual), eliminating the need for carefully handcrafted prompts. Although conceptually straightforward, SiM demonstrates strong performance, operates with high computational efficiency (learning the mapping typically takes less than one second), and provides interpretability by linking target classes to generic prompts. We believe that our approach could serve as an important baseline for future research in vocabulary-free few-shot learning. Code is available at https://github.com/MaxZanella/vocabulary-free-FSL.
Online Gaussian Test-Time Adaptation of Vision-Language Models
Jan 08, 2025Online test-time adaptation (OTTA) of vision-language models (VLMs) has recently garnered increased attention to take advantage of data observed along a stream to improve future predictions. Unfortunately, existing methods rely on dataset-specific hyperparameters, significantly limiting their adaptability to unseen tasks. In response, we propose Online Gaussian Adaptation (OGA), a novel method that models the likelihoods of visual features using Gaussian distributions and incorporates zero-shot priors into an interpretable Maximum A Posteriori (MAP) estimation framework with fixed hyper-parameters across all datasets. We demonstrate that OGA outperforms state-of-the-art methods on most datasets and runs. Additionally, we show that combining OTTA with popular few-shot techniques (a practical yet overlooked setting in prior research) is highly beneficial. Furthermore, our experimental study reveals that common OTTA evaluation protocols, which average performance over at most three runs per dataset, are inadequate due to the substantial variability observed across runs for all OTTA methods. Therefore, we advocate for more rigorous evaluation practices, including increasing the number of runs and considering additional quantitative metrics, such as our proposed Expected Tail Accuracy (ETA), calculated as the average accuracy in the worst 10% of runs. We hope these contributions will encourage more rigorous and diverse evaluation practices in the OTTA community. Code is available at https://github.com/cfuchs2023/OGA .
Realistic Test-Time Adaptation of Vision-Language Models
Jan 07, 2025



The zero-shot capabilities of Vision-Language Models (VLMs) have been widely leveraged to improve predictive performance. However, previous works on transductive or test-time adaptation (TTA) often make strong assumptions about the data distribution, such as the presence of all classes. Our work challenges these favorable deployment scenarios, and introduces a more realistic evaluation framework, including: (i) a variable number of effective classes for adaptation within a single batch, and (ii) non-i.i.d. batches of test samples in online adaptation settings. We provide comprehensive evaluations, comparisons, and ablation studies that demonstrate how current transductive or TTA methods for VLMs systematically compromise the models' initial zero-shot robustness across various realistic scenarios, favoring performance gains under advantageous assumptions about the test samples' distributions. Furthermore, we introduce StatA, a versatile method that could handle a wide range of deployment scenarios, including those with a variable number of effective classes at test time. Our approach incorporates a novel regularization term designed specifically for VLMs, which acts as a statistical anchor preserving the initial text-encoder knowledge, particularly in low-data regimes. Code available at https://github.com/MaxZanella/StatA.
Physically Interpretable Probabilistic Domain Characterization
Nov 22, 2024Characterizing domains is essential for models analyzing dynamic environments, as it allows them to adapt to evolving conditions or to hand the task over to backup systems when facing conditions outside their operational domain. Existing solutions typically characterize a domain by solving a regression or classification problem, which limits their applicability as they only provide a limited summarized description of the domain. In this paper, we present a novel approach to domain characterization by characterizing domains as probability distributions. Particularly, we develop a method to predict the likelihood of different weather conditions from images captured by vehicle-mounted cameras by estimating distributions of physical parameters using normalizing flows. To validate our proposed approach, we conduct experiments within the context of autonomous vehicles, focusing on predicting the distribution of weather parameters to characterize the operational domain. This domain is characterized by physical parameters (absolute characterization) and arbitrarily predefined domains (relative characterization). Finally, we evaluate whether a system can safely operate in a target domain by comparing it to multiple source domains where safety has already been established. This approach holds significant potential, as accurate weather prediction and effective domain adaptation are crucial for autonomous systems to adjust to dynamic environmental conditions.
Exploring Foundation Models Fine-Tuning for Cytology Classification
Nov 22, 2024
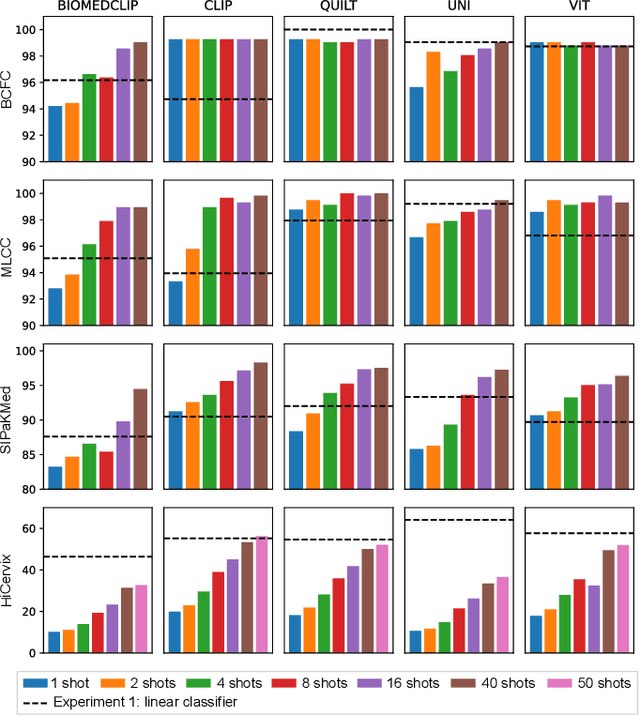

Cytology slides are essential tools in diagnosing and staging cancer, but their analysis is time-consuming and costly. Foundation models have shown great potential to assist in these tasks. In this paper, we explore how existing foundation models can be applied to cytological classification. More particularly, we focus on low-rank adaptation, a parameter-efficient fine-tuning method suited to few-shot learning. We evaluated five foundation models across four cytological classification datasets. Our results demonstrate that fine-tuning the pre-trained backbones with LoRA significantly improves model performance compared to fine-tuning only the classifier head, achieving state-of-the-art results on both simple and complex classification tasks while requiring fewer data samples.
Boosting Vision-Language Models for Histopathology Classification: Predict all at once
Sep 03, 2024The development of vision-language models (VLMs) for histo-pathology has shown promising new usages and zero-shot performances. However, current approaches, which decompose large slides into smaller patches, focus solely on inductive classification, i.e., prediction for each patch is made independently of the other patches in the target test data. We extend the capability of these large models by introducing a transductive approach. By using text-based predictions and affinity relationships among patches, our approach leverages the strong zero-shot capabilities of these new VLMs without any additional labels. Our experiments cover four histopathology datasets and five different VLMs. Operating solely in the embedding space (i.e., in a black-box setting), our approach is highly efficient, processing $10^5$ patches in just a few seconds, and shows significant accuracy improvements over inductive zero-shot classification. Code available at https://github.com/FereshteShakeri/Histo-TransCLIP.
Enhancing Remote Sensing Vision-Language Models for Zero-Shot Scene Classification
Sep 01, 2024


Vision-Language Models for remote sensing have shown promising uses thanks to their extensive pretraining. However, their conventional usage in zero-shot scene classification methods still involves dividing large images into patches and making independent predictions, i.e., inductive inference, thereby limiting their effectiveness by ignoring valuable contextual information. Our approach tackles this issue by utilizing initial predictions based on text prompting and patch affinity relationships from the image encoder to enhance zero-shot capabilities through transductive inference, all without the need for supervision and at a minor computational cost. Experiments on 10 remote sensing datasets with state-of-the-art Vision-Language Models demonstrate significant accuracy improvements over inductive zero-shot classification. Our source code is publicly available on Github: https://github.com/elkhouryk/RS-TransCLIP