 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Random Fields for Interactive Refinement of Histopathological Predictions
Jan 17, 2026Assisting pathologists in the analysis of histopathological images has high clinical value, as it supports cancer detection and staging. In this context, histology foundation models have recently emerged. Among them, Vision-Language Models (VLMs) provide strong yet imperfect zero-shot predictions. We propose to refine these predictions by adapting Conditional Random Fields (CRFs) to histopathological applications, requiring no additional model training. We present HistoCRF, a CRF-based framework, with a novel definition of the pairwise potential that promotes label diversity and leverages expert annotations. We consider three experiments: without annotations, with expert annotations, and with iterative human-in-the-loop annotations that progressively correct misclassified patches. Experiments on five patch-level classification datasets covering different organs and diseases demonstrate average accuracy gains of 16.0% without annotations and 27.5% with only 100 annotations, compared to zero-shot predictions. Moreover, integrating a human in the loop reaches a further gain of 32.6% with the same number of annotations. The code will be made available on https://github.com/tgodelaine/HistoCRF.
Leveraging Prediction Entropy for Automatic Prompt Weighting in Zero-Shot Audio-Language Classification
Jan 08, 2026Audio-language models have recently demonstrated strong zero-shot capabilities by leveraging natural-language supervision to classify audio events without labeled training data. Yet, their performance is highly sensitive to the wording of text prompts, with small variations leading to large fluctuations in accuracy. Prior work has mitigated this issue through prompt learning or prompt ensembling. However, these strategies either require annotated data or fail to account for the fact that some prompts may negatively impact performance. In this work, we present an entropy-guided prompt weighting approach that aims to find a robust combination of prompt contributions to maximize prediction confidence. To this end, we formulate a tailored objective function that minimizes prediction entropy to yield new prompt weights, utilizing low-entropy as a proxy for high confidence. Our approach can be applied to individual samples or a batch of audio samples, requiring no additional labels and incurring negligible computational overhead. Experiments on five audio classification datasets covering environmental, urban, and vocal sounds, demonstrate consistent gains compared to classical prompt ensembling methods in a zero-shot setting, with accuracy improvements 5-times larger across the whole benchmark.
Few-Shot Adaptation Benchmark for Remote Sensing Vision-Language Models
Oct 08, 2025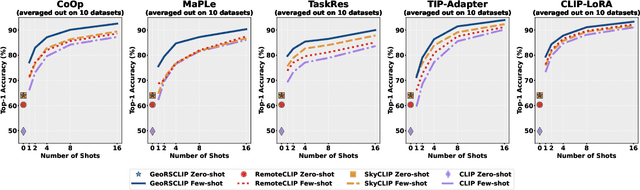



Remote Sensing Vision-Language Models (RSVLMs) have shown remarkable potential thanks to large-scale pretraining, achieving strong zero-shot performance on various tasks. However, their ability to generalize in low-data regimes, such as few-shot learning, remains insufficiently explored. In this work, we present the first structured benchmark for evaluating few-shot adaptation methods on RSVLMs. We conduct comprehensive experiments across ten remote sensing scene classification datasets, applying five widely used few-shot adaptation strategies to three state-of-the-art RSVLMs with varying backbones. Our findings reveal that models with similar zero-shot performance can exhibit markedly different behavior under few-shot adaptation, with some RSVLMs being inherently more amenable to such adaptation than others. The variability of performance and the absence of a clear winner among existing methods highlight the need for the development of more robust methods for few-shot adaptation tailored to RS. To facilitate future research, we provide a reproducible benchmarking framework and open-source code to systematically evaluate RSVLMs under few-shot conditions. The source code is publicly available on Github: https://github.com/elkhouryk/fewshot_RSVLMs
Exploring Foundation Models Fine-Tuning for Cytology Classification
Nov 22, 2024
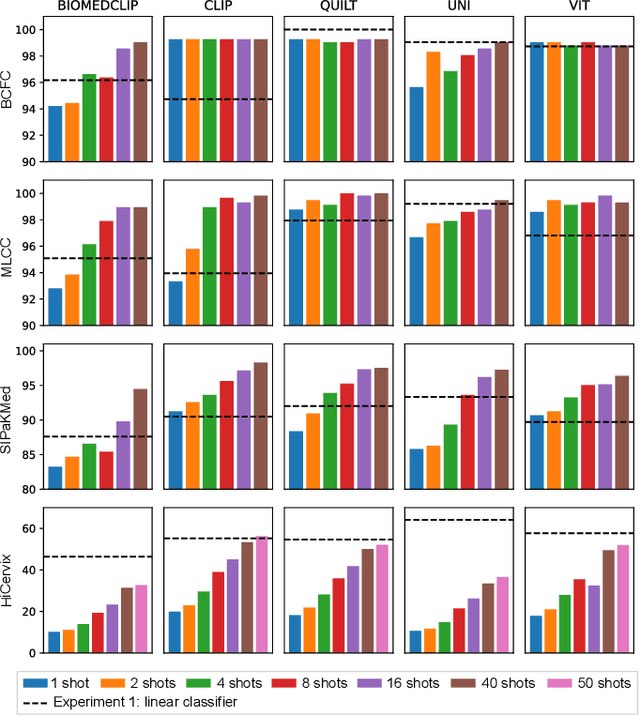

Cytology slides are essential tools in diagnosing and staging cancer, but their analysis is time-consuming and costly. Foundation models have shown great potential to assist in these tasks. In this paper, we explore how existing foundation models can be applied to cytological classification. More particularly, we focus on low-rank adaptation, a parameter-efficient fine-tuning method suited to few-shot learning. We evaluated five foundation models across four cytological classification datasets. Our results demonstrate that fine-tuning the pre-trained backbones with LoRA significantly improves model performance compared to fine-tuning only the classifier head, achieving state-of-the-art results on both simple and complex classification tasks while requiring fewer data samples.
Enhancing Remote Sensing Vision-Language Models for Zero-Shot Scene Classification
Sep 01, 2024


Vision-Language Models for remote sensing have shown promising uses thanks to their extensive pretraining. However, their conventional usage in zero-shot scene classification methods still involves dividing large images into patches and making independent predictions, i.e., inductive inference, thereby limiting their effectiveness by ignoring valuable contextual information. Our approach tackles this issue by utilizing initial predictions based on text prompting and patch affinity relationships from the image encoder to enhance zero-shot capabilities through transductive inference, all without the need for supervision and at a minor computational cost. Experiments on 10 remote sensing datasets with state-of-the-art Vision-Language Models demonstrate significant accuracy improvements over inductive zero-shot classification. Our source code is publicly available on Github: https://github.com/elkhouryk/RS-TransCLIP
Streamlined Hybrid Annotation Framework using Scalable Codestream for Bandwidth-Restricted UAV Object Detection
Feb 07, 2024Emergency response missions depend on the fast relay of visual information, a task to which unmanned aerial vehicles are well adapted. However, the effective use of unmanned aerial vehicles is often compromised by bandwidth limitations that impede fast data transmission, thereby delaying the quick decision-making necessary in emergency situations. To address these challenges, this paper presents a streamlined hybrid annotation framework that utilizes the JPEG 2000 compression algorithm to facilitate object detection under limited bandwidth. The proposed framework employs a fine-tuned deep learning network for initial image annotation at lower resolutions and uses JPEG 2000's scalable codestream to selectively enhance the image resolution in critical areas that require human expert annotation. We show that our proposed hybrid framework reduces the response time by a factor of 34 in emergency situations compared to a baseline approach.