 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurophysiological effects of museum modalities on emotional engagement with real artworks
Feb 02, 2026Museums increasingly rely on digital content to support visitors' understanding of artworks, yet little is known about how these formats shape the emotional engagement that underlies meaningful art experiences. This research presents an in-situ EEG study on how digital interpretive content modulate engagement during art viewing. Participants experienced three modalities: direct viewing of a Bruegel painting, a 180° immersive interpretive projection, and a regular, display-based interpretive video. Frontal EEG markers of motivational orientation, internal involvement, perceptual drive, and arousal were extracted using eyes-open baselines and Z-normalized contrasts. Results show modality-specific engagement profiles: display-based interpretive video induced high arousal and fast-band activity, immersive projections promoted calm, presence-oriented absorption, and original artworks reflected internally regulated engagement. These findings, relying on lightweight EEG sensing in an operational cultural environment, suggest that digital interpretive content affects engagement style rather than quantity. This paves the way for new multimodal sensing approaches and enables museums to optimize the modalities and content of their interpretive media.
Conditional Random Fields for Interactive Refinement of Histopathological Predictions
Jan 17, 2026Assisting pathologists in the analysis of histopathological images has high clinical value, as it supports cancer detection and staging. In this context, histology foundation models have recently emerged. Among them, Vision-Language Models (VLMs) provide strong yet imperfect zero-shot predictions. We propose to refine these predictions by adapting Conditional Random Fields (CRFs) to histopathological applications, requiring no additional model training. We present HistoCRF, a CRF-based framework, with a novel definition of the pairwise potential that promotes label diversity and leverages expert annotations. We consider three experiments: without annotations, with expert annotations, and with iterative human-in-the-loop annotations that progressively correct misclassified patches. Experiments on five patch-level classification datasets covering different organs and diseases demonstrate average accuracy gains of 16.0% without annotations and 27.5% with only 100 annotations, compared to zero-shot predictions. Moreover, integrating a human in the loop reaches a further gain of 32.6% with the same number of annotations. The code will be made available on https://github.com/tgodelaine/HistoCRF.
No Need for "Learning" to Defer? A Training Free Deferral Framework to Multiple Experts through Conformal Prediction
Sep 16, 2025AI systems often fail to deliver reliable predictions across all inputs, prompting the need for hybrid human-AI decision-making. Existing Learning to Defer (L2D) approaches address this by training deferral models, but these are sensitive to changes in expert composition and require significant retraining if experts change. We propose a training-free, model- and expert-agnostic framework for expert deferral based on conformal prediction. Our method uses the prediction set generated by a conformal predictor to identify label-specific uncertainty and selects the most discriminative expert using a segregativity criterion, measuring how well an expert distinguishes between the remaining plausible labels. Experiments on CIFAR10-H and ImageNet16-H show that our method consistently outperforms both the standalone model and the strongest expert, with accuracies attaining $99.57\pm0.10\%$ and $99.40\pm0.52\%$, while reducing expert workload by up to a factor of $11$. The method remains robust under degraded expert performance and shows a gradual performance drop in low-information settings. These results suggest a scalable, retraining-free alternative to L2D for real-world human-AI collaboration.
ConfLUNet: Multiple sclerosis lesion instance segmentation in presence of confluent lesions
May 28, 2025Accurate lesion-level segmentation on MRI is critical for multiple sclerosis (MS) diagnosis, prognosis, and disease monitoring. However, current evaluation practices largely rely on semantic segmentation post-processed with connected components (CC), which cannot separate confluent lesions (aggregates of confluent lesion units, CLUs) due to reliance on spatial connectivity. To address this misalignment with clinical needs, we introduce formal definitions of CLUs and associated CLU-aware detection metrics, and include them in an exhaustive instance segmentation evaluation framework. Within this framework, we systematically evaluate CC and post-processing-based Automated Confluent Splitting (ACLS), the only existing methods for lesion instance segmentation in MS. Our analysis reveals that CC consistently underestimates CLU counts, while ACLS tends to oversplit lesions, leading to overestimated lesion counts and reduced precision. To overcome these limitations, we propose ConfLUNet, the first end-to-end instance segmentation framework for MS lesions. ConfLUNet jointly optimizes lesion detection and delineation from a single FLAIR image. Trained on 50 patients, ConfLUNet significantly outperforms CC and ACLS on the held-out test set (n=13) in instance segmentation (Panoptic Quality: 42.0% vs. 37.5%/36.8%; p = 0.017/0.005) and lesion detection (F1: 67.3% vs. 61.6%/59.9%; p = 0.028/0.013). For CLU detection, ConfLUNet achieves the highest F1[CLU] (81.5%), improving recall over CC (+12.5%, p = 0.015) and precision over ACLS (+31.2%, p = 0.003). By combining rigorous definitions, new CLU-aware metrics, a reproducible evaluation framework, and the first dedicated end-to-end model, this work lays the foundation for lesion instance segmentation in MS.
Exploring Foundation Models Fine-Tuning for Cytology Classification
Nov 22, 2024
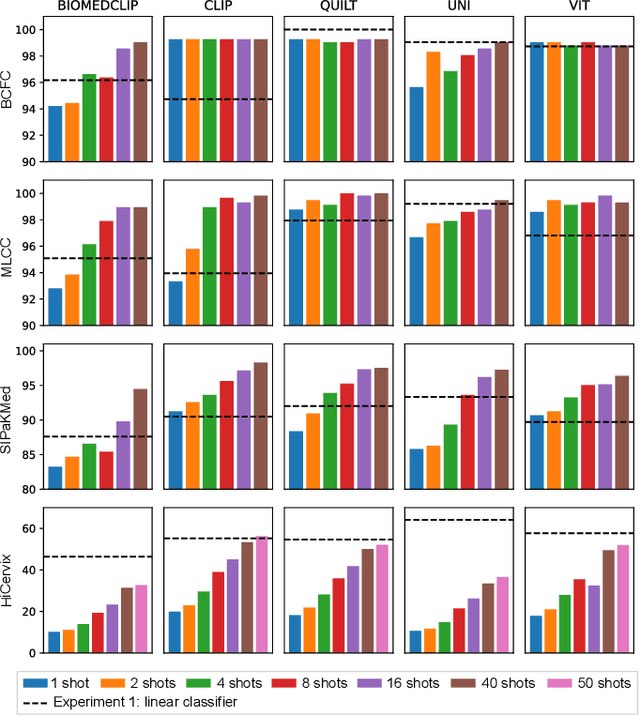

Cytology slides are essential tools in diagnosing and staging cancer, but their analysis is time-consuming and costly. Foundation models have shown great potential to assist in these tasks. In this paper, we explore how existing foundation models can be applied to cytological classification. More particularly, we focus on low-rank adaptation, a parameter-efficient fine-tuning method suited to few-shot learning. We evaluated five foundation models across four cytological classification datasets. Our results demonstrate that fine-tuning the pre-trained backbones with LoRA significantly improves model performance compared to fine-tuning only the classifier head, achieving state-of-the-art results on both simple and complex classification tasks while requiring fewer data samples.
Physically Interpretable Probabilistic Domain Characterization
Nov 22, 2024Characterizing domains is essential for models analyzing dynamic environments, as it allows them to adapt to evolving conditions or to hand the task over to backup systems when facing conditions outside their operational domain. Existing solutions typically characterize a domain by solving a regression or classification problem, which limits their applicability as they only provide a limited summarized description of the domain. In this paper, we present a novel approach to domain characterization by characterizing domains as probability distributions. Particularly, we develop a method to predict the likelihood of different weather conditions from images captured by vehicle-mounted cameras by estimating distributions of physical parameters using normalizing flows. To validate our proposed approach, we conduct experiments within the context of autonomous vehicles, focusing on predicting the distribution of weather parameters to characterize the operational domain. This domain is characterized by physical parameters (absolute characterization) and arbitrarily predefined domains (relative characterization). Finally, we evaluate whether a system can safely operate in a target domain by comparing it to multiple source domains where safety has already been established. This approach holds significant potential, as accurate weather prediction and effective domain adaptation are crucial for autonomous systems to adjust to dynamic environmental conditions.
Enhancing Remote Sensing Vision-Language Models for Zero-Shot Scene Classification
Sep 01, 2024


Vision-Language Models for remote sensing have shown promising uses thanks to their extensive pretraining. However, their conventional usage in zero-shot scene classification methods still involves dividing large images into patches and making independent predictions, i.e., inductive inference, thereby limiting their effectiveness by ignoring valuable contextual information. Our approach tackles this issue by utilizing initial predictions based on text prompting and patch affinity relationships from the image encoder to enhance zero-shot capabilities through transductive inference, all without the need for supervision and at a minor computational cost. Experiments on 10 remote sensing datasets with state-of-the-art Vision-Language Models demonstrate significant accuracy improvements over inductive zero-shot classification. Our source code is publicly available on Github: https://github.com/elkhouryk/RS-TransCLIP
Multi-Stream Cellular Test-Time Adaptation of Real-Time Models Evolving in Dynamic Environments
Apr 27, 2024In the era of the Internet of Things (IoT), objects connect through a dynamic network, empowered by technologies like 5G, enabling real-time data sharing. However, smart objects, notably autonomous vehicles, face challenges in critical local computations due to limited resources. Lightweight AI models offer a solution but struggle with diverse data distributions. To address this limitation, we propose a novel Multi-Stream Cellular Test-Time Adaptation (MSC-TTA) setup where models adapt on the fly to a dynamic environment divided into cells. Then, we propose a real-time adaptive student-teacher method that leverages the multiple streams available in each cell to quickly adapt to changing data distributions. We validate our methodology in the context of autonomous vehicles navigating across cells defined based on location and weather conditions. To facilitate future benchmarking, we release a new multi-stream large-scale synthetic semantic segmentation dataset, called DADE, and show that our multi-stream approach outperforms a single-stream baseline. We believe that our work will open research opportunities in the IoT and 5G eras, offering solutions for real-time model adaptation.
Mixture Domain Adaptation to Improve Semantic Segmentation in Real-World Surveillance
Nov 18, 2022Various tasks encountered in real-world surveillance can be addressed by determining posteriors (e.g. by Bayesian inference or machine learning), based on which critical decisions must be taken. However, the surveillance domain (acquisition device, operating conditions, etc.) is often unknown, which prevents any possibility of scene-specific optimization. In this paper, we define a probabilistic framework and present a formal proof of an algorithm for the unsupervised many-to-infinity domain adaptation of posteriors. Our proposed algorithm is applicable when the probability measure associated with the target domain is a convex combination of the probability measures of the source domains. It makes use of source models and a domain discriminator model trained off-line to compute posteriors adapted on the fly to the target domain. Finally, we show the effectiveness of our algorithm for the task of semantic segmentation in real-world surveillance. The code is publicly available at https://github.com/rvandeghen/MDA.
Forward Error Correction applied to JPEG-XS codestreams
Jul 11, 2022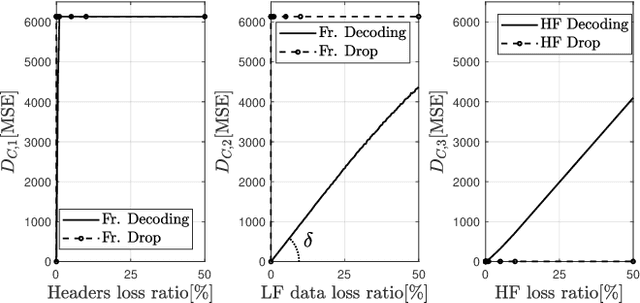
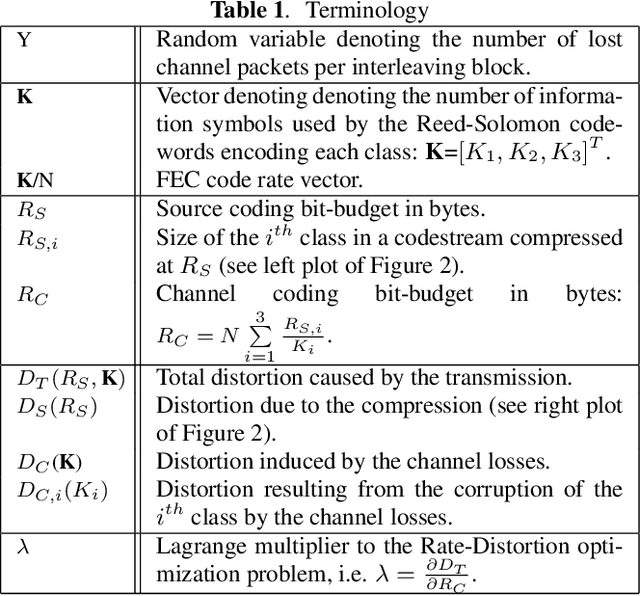
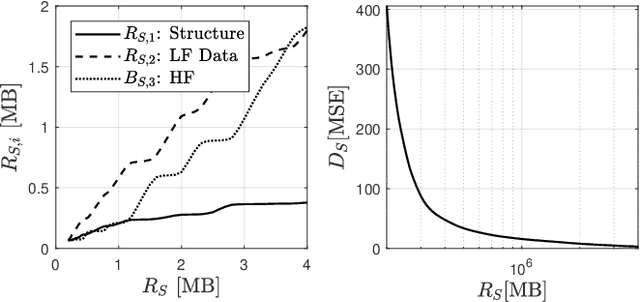
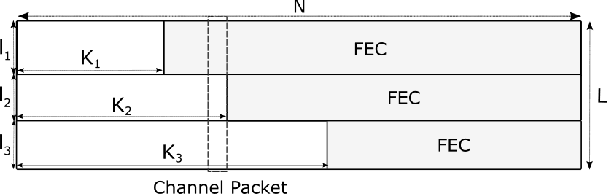
JPEG-XS offers low complexity image compression for applications with constrained but reasonable bit-rate, and low latency. Our paper explores the deployment of JPEG-XS on lossy packet networks. To preserve low latency, Forward Error Correction (FEC) is envisioned as the protection mechanism of interest. Despite the JPEG-XS codestream is not scalable in essence, we observe that the loss of a codestream fraction impacts the decoded image quality differently, depending on whether this codestream fraction corresponds to codestream headers, to coefficients significance information, or to low/high frequency data, respectively. Hence, we propose a rate-distortion optimal unequal error protection scheme that adapts the redundancy level of Reed-Solomon codes according to the rate of channel losses and the type of information protected by the code. Our experiments demonstrate that, at 5% loss rates, it reduces the Mean Squared Error by up to 92% and 65%, compared to a transmission without and with optimal but equal protection, respectively.