 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Random Fields for Interactive Refinement of Histopathological Predictions
Jan 17, 2026Assisting pathologists in the analysis of histopathological images has high clinical value, as it supports cancer detection and staging. In this context, histology foundation models have recently emerged. Among them, Vision-Language Models (VLMs) provide strong yet imperfect zero-shot predictions. We propose to refine these predictions by adapting Conditional Random Fields (CRFs) to histopathological applications, requiring no additional model training. We present HistoCRF, a CRF-based framework, with a novel definition of the pairwise potential that promotes label diversity and leverages expert annotations. We consider three experiments: without annotations, with expert annotations, and with iterative human-in-the-loop annotations that progressively correct misclassified patches. Experiments on five patch-level classification datasets covering different organs and diseases demonstrate average accuracy gains of 16.0% without annotations and 27.5% with only 100 annotations, compared to zero-shot predictions. Moreover, integrating a human in the loop reaches a further gain of 32.6% with the same number of annotations. The code will be made available on https://github.com/tgodelaine/HistoCRF.
Physically Interpretable Probabilistic Domain Characterization
Nov 22, 2024Characterizing domains is essential for models analyzing dynamic environments, as it allows them to adapt to evolving conditions or to hand the task over to backup systems when facing conditions outside their operational domain. Existing solutions typically characterize a domain by solving a regression or classification problem, which limits their applicability as they only provide a limited summarized description of the domain. In this paper, we present a novel approach to domain characterization by characterizing domains as probability distributions. Particularly, we develop a method to predict the likelihood of different weather conditions from images captured by vehicle-mounted cameras by estimating distributions of physical parameters using normalizing flows. To validate our proposed approach, we conduct experiments within the context of autonomous vehicles, focusing on predicting the distribution of weather parameters to characterize the operational domain. This domain is characterized by physical parameters (absolute characterization) and arbitrarily predefined domains (relative characterization). Finally, we evaluate whether a system can safely operate in a target domain by comparing it to multiple source domains where safety has already been established. This approach holds significant potential, as accurate weather prediction and effective domain adaptation are crucial for autonomous systems to adjust to dynamic environmental conditions.
Enhancing Remote Sensing Vision-Language Models for Zero-Shot Scene Classification
Sep 01, 2024


Vision-Language Models for remote sensing have shown promising uses thanks to their extensive pretraining. However, their conventional usage in zero-shot scene classification methods still involves dividing large images into patches and making independent predictions, i.e., inductive inference, thereby limiting their effectiveness by ignoring valuable contextual information. Our approach tackles this issue by utilizing initial predictions based on text prompting and patch affinity relationships from the image encoder to enhance zero-shot capabilities through transductive inference, all without the need for supervision and at a minor computational cost. Experiments on 10 remote sensing datasets with state-of-the-art Vision-Language Models demonstrate significant accuracy improvements over inductive zero-shot classification. Our source code is publicly available on Github: https://github.com/elkhouryk/RS-TransCLIP
Mixture Domain Adaptation to Improve Semantic Segmentation in Real-World Surveillance
Nov 18, 2022Various tasks encountered in real-world surveillance can be addressed by determining posteriors (e.g. by Bayesian inference or machine learning), based on which critical decisions must be taken. However, the surveillance domain (acquisition device, operating conditions, etc.) is often unknown, which prevents any possibility of scene-specific optimization. In this paper, we define a probabilistic framework and present a formal proof of an algorithm for the unsupervised many-to-infinity domain adaptation of posteriors. Our proposed algorithm is applicable when the probability measure associated with the target domain is a convex combination of the probability measures of the source domains. It makes use of source models and a domain discriminator model trained off-line to compute posteriors adapted on the fly to the target domain. Finally, we show the effectiveness of our algorithm for the task of semantic segmentation in real-world surveillance. The code is publicly available at https://github.com/rvandeghen/MDA.
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022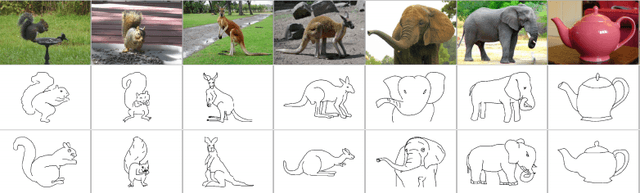
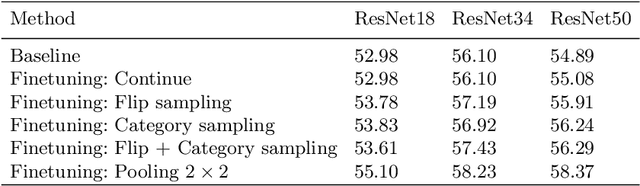


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.