 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe for Efficient SBIR Models: Combining Relative Triplet Loss with Batch Normalization and Knowledge Distillation
May 30, 2023Sketch-Based Image Retrieval (SBIR) is a crucial task in multimedia retrieval, where the goal is to retrieve a set of images that match a given sketch query. Researchers have already proposed several well-performing solutions for this task, but most focus on enhancing embedding through different approaches such as triplet loss, quadruplet loss, adding data augmentation, and using edge extraction. In this work, we tackle the problem from various angles. We start by examining the training data quality and show some of its limitations. Then, we introduce a Relative Triplet Loss (RTL), an adapted triplet loss to overcome those limitations through loss weighting based on anchors similarity. Through a series of experiments, we demonstrate that replacing a triplet loss with RTL outperforms previous state-of-the-art without the need for any data augmentation. In addition, we demonstrate why batch normalization is more suited for SBIR embeddings than l2-normalization and show that it improves significantly the performance of our models. We further investigate the capacity of models required for the photo and sketch domains and demonstrate that the photo encoder requires a higher capacity than the sketch encoder, which validates the hypothesis formulated in [34]. Then, we propose a straightforward approach to train small models, such as ShuffleNetv2 [22] efficiently with a marginal loss of accuracy through knowledge distillation. The same approach used with larger models enabled us to outperform previous state-of-the-art results and achieve a recall of 62.38% at k = 1 on The Sketchy Database [30].
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022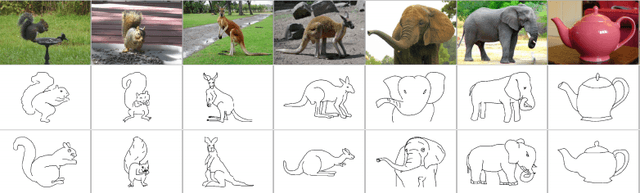
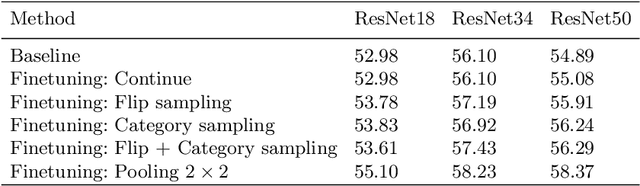


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.
Proceedings of eNTERFACE 2015 Workshop on Intelligent Interfaces
Jan 19, 2018
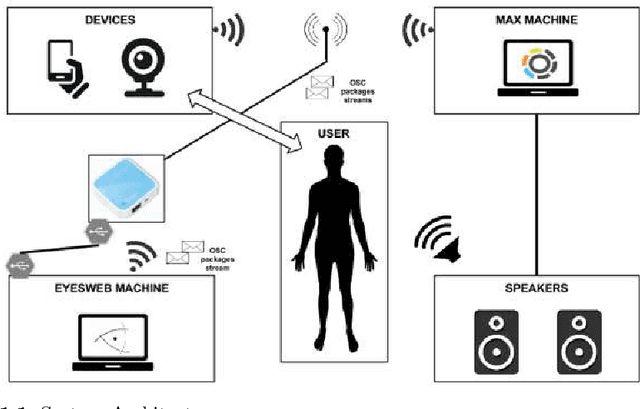
The 11th Summer Workshop on Multimodal Interfaces eNTERFACE 2015 was hosted by the Numediart Institute of Creative Technologies of the University of Mons from August 10th to September 2015. During the four weeks, students and researchers from all over the world came together in the Numediart Institute of the University of Mons to work on eight selected projects structured around intelligent interfaces. Eight projects were selected and their reports are shown here.
Visually Grounded Word Embeddings and Richer Visual Features for Improving Multimodal Neural Machine Translation
Dec 16, 2017

In Multimodal Neural Machine Translation (MNMT), a neural model generates a translated sentence that describes an image, given the image itself and one source descriptions in English. This is considered as the multimodal image caption translation task. The images are processed with Convolutional Neural Network (CNN) to extract visual features exploitable by the translation model. So far, the CNNs used are pre-trained on object detection and localization task. We hypothesize that richer architecture, such as dense captioning models, may be more suitable for MNMT and could lead to improved translations. We extend this intuition to the word-embeddings, where we compute both linguistic and visual representation for our corpus vocabulary. We combine and compare different confi
* Accepted to GLU 2017. arXiv admin note: text overlap with arXiv:1707.00995