 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound in Translation: semantic approaches for enhancing AI interpretability in face verification
Jan 06, 2025The increasing complexity of machine learning models in computer vision, particularly in face verification, requires the development of explainable artificial intelligence (XAI) to enhance interpretability and transparency. This study extends previous work by integrating semantic concepts derived from human cognitive processes into XAI frameworks to bridge the comprehension gap between model outputs and human understanding. We propose a novel approach combining global and local explanations, using semantic features defined by user-selected facial landmarks to generate similarity maps and textual explanations via large language models (LLMs). The methodology was validated through quantitative experiments and user feedback, demonstrating improved interpretability. Results indicate that our semantic-based approach, particularly the most detailed set, offers a more nuanced understanding of model decisions than traditional methods. User studies highlight a preference for our semantic explanations over traditional pixelbased heatmaps, emphasizing the benefits of human-centric interpretability in AI. This work contributes to the ongoing efforts to create XAI frameworks that align AI models behaviour with human cognitive processes, fostering trust and acceptance in critical applications.
CIA: Controllable Image Augmentation Framework Based on Stable Diffusion
Nov 25, 2024


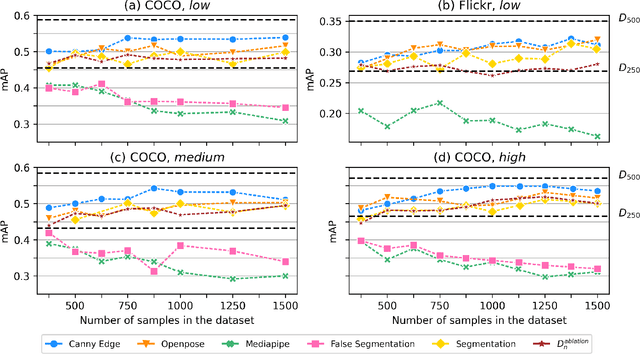
Computer vision tasks such as object detection and segmentation rely on the availability of extensive, accurately annotated datasets. In this work, We present CIA, a modular pipeline, for (1) generating synthetic images for dataset augmentation using Stable Diffusion, (2) filtering out low quality samples using defined quality metrics, (3) forcing the existence of specific patterns in generated images using accurate prompting and ControlNet. In order to show how CIA can be used to search for an optimal augmentation pipeline of training data, we study human object detection in a data constrained scenario, using YOLOv8n on COCO and Flickr30k datasets. We have recorded significant improvement using CIA-generated images, approaching the performances obtained when doubling the amount of real images in the dataset. Our findings suggest that our modular framework can significantly enhance object detection systems, and make it possible for future research to be done on data-constrained scenarios. The framework is available at: github.com/multitel-ai/CIA.
Induced Feature Selection by Structured Pruning
Mar 20, 2023



The advent of sparsity inducing techniques in neural networks has been of a great help in the last few years. Indeed, those methods allowed to find lighter and faster networks, able to perform more efficiently in resource-constrained environment such as mobile devices or highly requested servers. Such a sparsity is generally imposed on the weights of neural networks, reducing the footprint of the architecture. In this work, we go one step further by imposing sparsity jointly on the weights and on the input data. This can be achieved following a three-step process: 1) impose a certain structured sparsity on the weights of the network; 2) track back input features corresponding to zeroed blocks of weight; 3) remove useless weights and input features and retrain the network. Performing pruning both on the network and on input data not only allows for extreme reduction in terms of parameters and operations but can also serve as an interpretation process. Indeed, with the help of data pruning, we now have information about which input feature is useful for the network to keep its performance. Experiments conducted on a variety of architectures and datasets: MLP validated on MNIST, CIFAR10/100 and ConvNets (VGG16 and ResNet18), validated on CIFAR10/100 and CALTECH101 respectively, show that it is possible to achieve additional gains in terms of total parameters and in FLOPs by performing pruning on input data, while also increasing accuracy.
People Tracking and Re-Identifying in Distributed Contexts: Extension Study of PoseTReID
May 25, 2022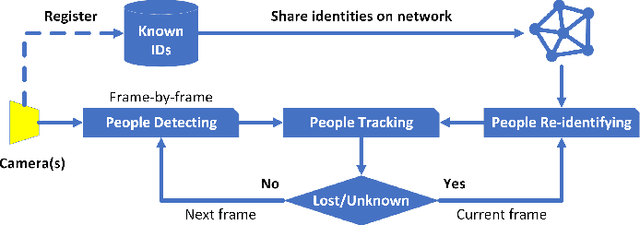



In our previous paper, we introduced PoseTReID which is a generic framework for real-time 2D multi-person tracking in distributed interaction spaces where long-term people's identities are important for other studies such as behavior analysis, etc. In this paper, we introduce a further study of PoseTReID framework in order to give a more complete comprehension of the framework. We use a well-known bounding box detector YOLO (v4) for the detection to compare to OpenPose which was used in our last paper, and we use SORT and DeepSORT to compare to centroid which was also used previously, and most importantly for the re-identification, we use a bunch of deep leaning methods such as MLFN, OSNet, and OSNet-AIN with our custom classification layer to compare to FaceNet which was also used earlier in our last paper. By evaluating on our PoseTReID datasets, even though those deep learning re-identification methods are designed for only short-term re-identification across multiple cameras or videos, it is worth showing that they give impressive results which boost the overall tracking performance of PoseTReID framework regardless the type of tracking method. At the same time, we also introduce our research-friendly and open source Python toolbox pyppbox, which is purely written in Python and contains all sub-modules which are used in this study along with real-time online and offline evaluations for our PoseTReID datasets. This pyppbox is available on GitHub https://github.com/rathaumons/pyppbox .
Improve Convolutional Neural Network Pruning by Maximizing Filter Variety
Mar 11, 2022
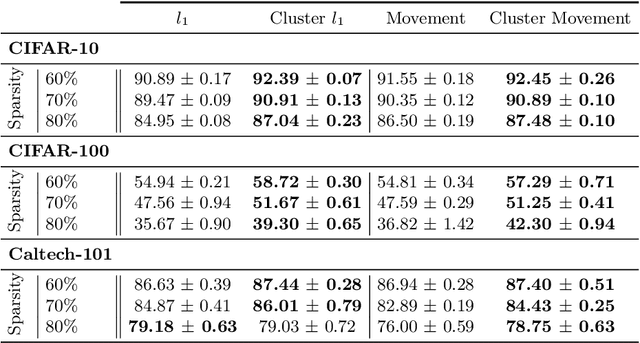

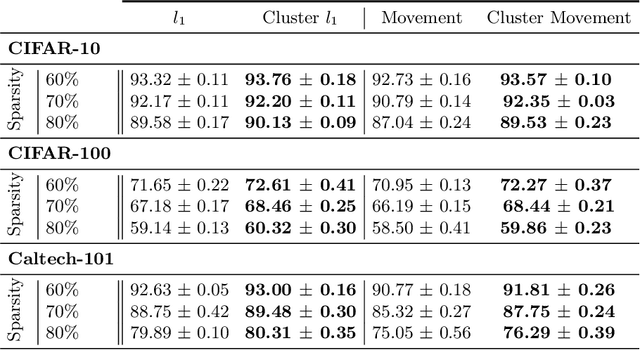
Neural network pruning is a widely used strategy for reducing model storage and computing requirements. It allows to lower the complexity of the network by introducing sparsity in the weights. Because taking advantage of sparse matrices is still challenging, pruning is often performed in a structured way, i.e. removing entire convolution filters in the case of ConvNets, according to a chosen pruning criteria. Common pruning criteria, such as l1-norm or movement, usually do not consider the individual utility of filters, which may lead to: (1) the removal of filters exhibiting rare, thus important and discriminative behaviour, and (2) the retaining of filters with redundant information. In this paper, we present a technique solving those two issues, and which can be appended to any pruning criteria. This technique ensures that the criteria of selection focuses on redundant filters, while retaining the rare ones, thus maximizing the variety of remaining filters. The experimental results, carried out on different datasets (CIFAR-10, CIFAR-100 and CALTECH-101) and using different architectures (VGG-16 and ResNet-18) demonstrate that it is possible to achieve similar sparsity levels while maintaining a higher performance when appending our filter selection technique to pruning criteria. Moreover, we assess the quality of the found sparse sub-networks by applying the Lottery Ticket Hypothesis and find that the addition of our method allows to discover better performing tickets in most cases
An Experimental Study of the Impact of Pre-training on the Pruning of a Convolutional Neural Network
Dec 15, 2021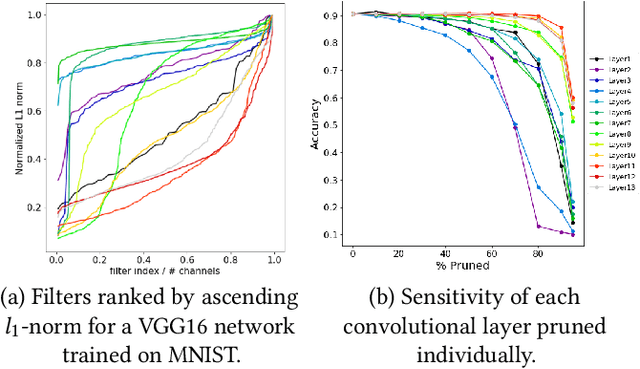
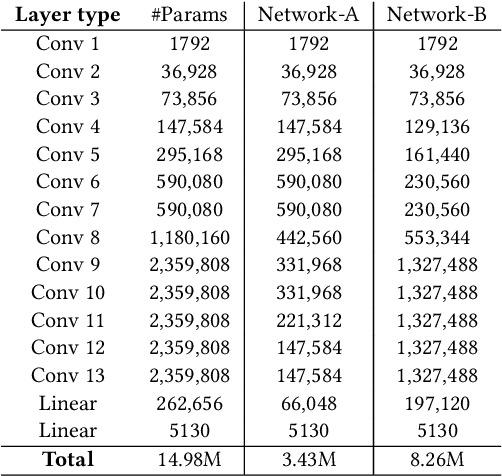
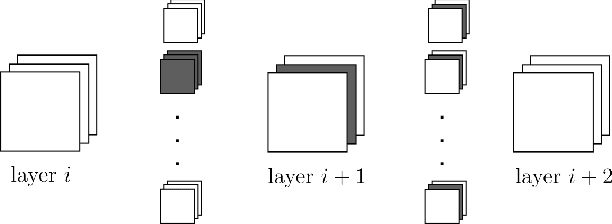
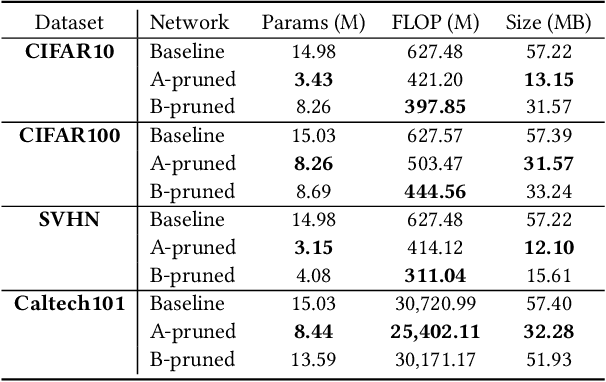
In recent years, deep neural networks have known a wide success in various application domains. However, they require important computational and memory resources, which severely hinders their deployment, notably on mobile devices or for real-time applications. Neural networks usually involve a large number of parameters, which correspond to the weights of the network. Such parameters, obtained with the help of a training process, are determinant for the performance of the network. However, they are also highly redundant. The pruning methods notably attempt to reduce the size of the parameter set, by identifying and removing the irrelevant weights. In this paper, we examine the impact of the training strategy on the pruning efficiency. Two training modalities are considered and compared: (1) fine-tuned and (2) from scratch. The experimental results obtained on four datasets (CIFAR10, CIFAR100, SVHN and Caltech101) and for two different CNNs (VGG16 and MobileNet) demonstrate that a network that has been pre-trained on a large corpus (e.g. ImageNet) and then fine-tuned on a particular dataset can be pruned much more efficiently (up to 80% of parameter reduction) than the same network trained from scratch.
DeepRare: Generic Unsupervised Visual Attention Models
Sep 23, 2021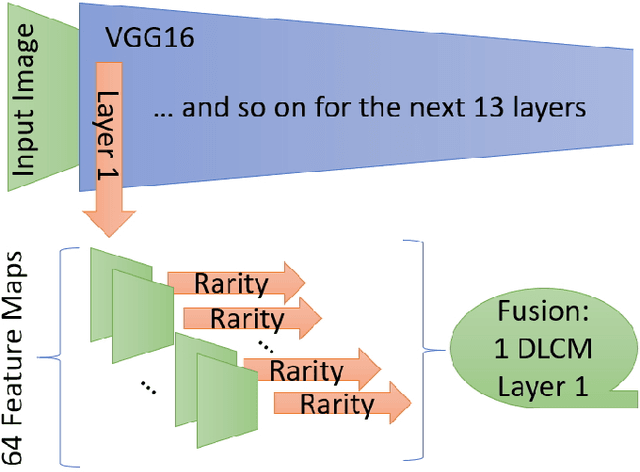
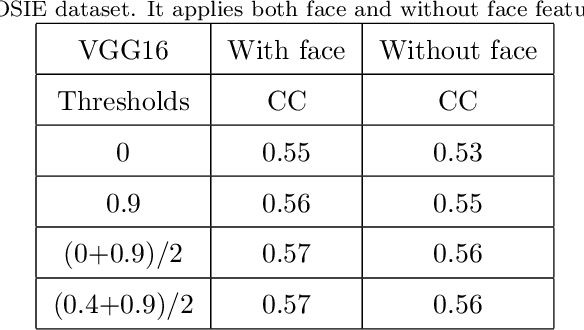

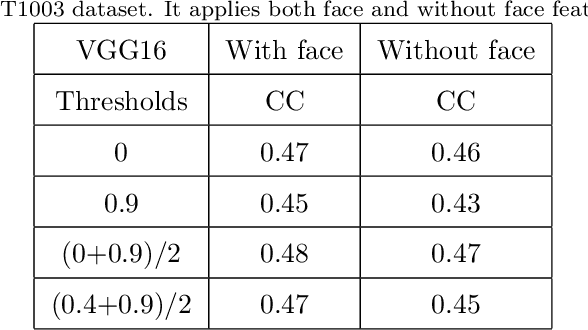
Human visual system is modeled in engineering field providing feature-engineered methods which detect contrasted/surprising/unusual data into images. This data is "interesting" for humans and leads to numerous applications. Deep learning (DNNs) drastically improved the algorithms efficiency on the main benchmark datasets. However, DNN-based models are counter-intuitive: surprising or unusual data is by definition difficult to learn because of its low occurrence probability. In reality, DNN-based models mainly learn top-down features such as faces, text, people, or animals which usually attract human attention, but they have low efficiency in extracting surprising or unusual data in the images. In this paper, we propose a new visual attention model called DeepRare2021 (DR21) which uses the power of DNNs feature extraction and the genericity of feature-engineered algorithms. This algorithm is an evolution of a previous version called DeepRare2019 (DR19) based on a common framework. DR21 1) does not need any training and uses the default ImageNet training, 2) is fast even on CPU, 3) is tested on four very different eye-tracking datasets showing that the DR21 is generic and is always in the within the top models on all datasets and metrics while no other model exhibits such a regularity and genericity. Finally DR21 4) is tested with several network architectures such as VGG16 (V16), VGG19 (V19) and MobileNetV2 (MN2) and 5) it provides explanation and transparency on which parts of the image are the most surprising at different levels despite the use of a DNN-based feature extractor. DeepRare2021 code can be found at https://github.com/numediart/VisualAttention-RareFamil}.
One-Cycle Pruning: Pruning ConvNets Under a Tight Training Budget
Jul 05, 2021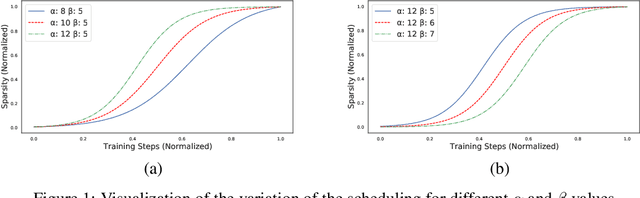
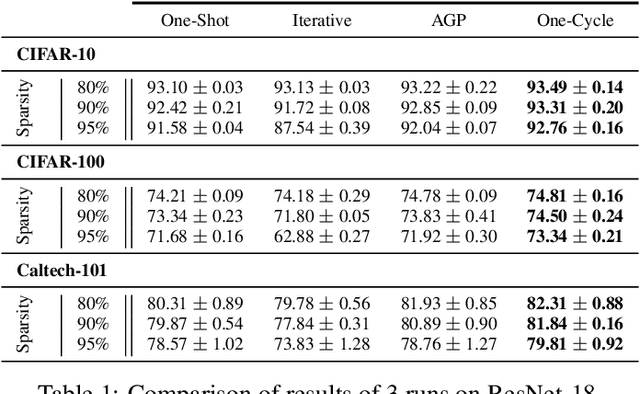
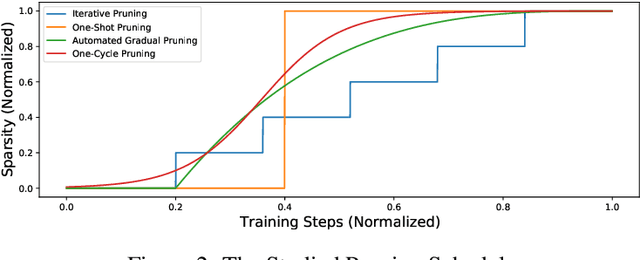

Introducing sparsity in a neural network has been an efficient way to reduce its complexity while keeping its performance almost intact. Most of the time, sparsity is introduced using a three-stage pipeline: 1) train the model to convergence, 2) prune the model according to some criterion, 3) fine-tune the pruned model to recover performance. The last two steps are often performed iteratively, leading to reasonable results but also to a time-consuming and complex process. In our work, we propose to get rid of the first step of the pipeline and to combine the two other steps in a single pruning-training cycle, allowing the model to jointly learn for the optimal weights while being pruned. We do this by introducing a novel pruning schedule, named One-Cycle Pruning, which starts pruning from the beginning of the training, and until its very end. Adopting such a schedule not only leads to better performing pruned models but also drastically reduces the training budget required to prune a model. Experiments are conducted on a variety of architectures (VGG-16 and ResNet-18) and datasets (CIFAR-10, CIFAR-100 and Caltech-101), and for relatively high sparsity values (80%, 90%, 95% of weights removed). Our results show that One-Cycle Pruning consistently outperforms commonly used pruning schedules such as One-Shot Pruning, Iterative Pruning and Automated Gradual Pruning, on a fixed training budget.
Proceedings of eNTERFACE 2015 Workshop on Intelligent Interfaces
Jan 19, 2018
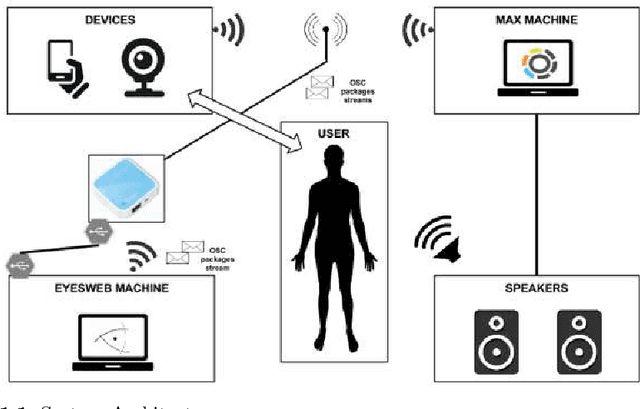
The 11th Summer Workshop on Multimodal Interfaces eNTERFACE 2015 was hosted by the Numediart Institute of Creative Technologies of the University of Mons from August 10th to September 2015. During the four weeks, students and researchers from all over the world came together in the Numediart Institute of the University of Mons to work on eight selected projects structured around intelligent interfaces. Eight projects were selected and their reports are shown here.
A study of parameters affecting visual saliency assessment
Jul 22, 2013

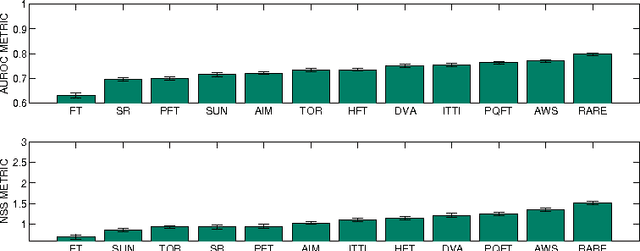

Since the early 2000s, computational visual saliency has been a very active research area. Each year, more and more new models are published in the main computer vision conferences. Nowadays, one of the big challenges is to find a way to fairly evaluate all of these models. In this paper, a new framework is proposed to assess models of visual saliency. This evaluation is divided into three experiments leading to the proposition of a new evaluation framework. Each experiment is based on a basic question: 1) there are two ground truths for saliency evaluation: what are the differences between eye fixations and manually segmented salient regions?, 2) the properties of the salient regions: for example, do large, medium and small salient regions present different difficulties for saliency models? and 3) the metrics used to assess saliency models: what advantages would there be to mix them with PCA? Statistical analysis is used here to answer each of these three questions.