 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Investigation into the Evaluation of Explainability Methods
May 25, 2023EXplainable Artificial Intelligence (XAI) aims to help users to grasp the reasoning behind the predictions of an Artificial Intelligence (AI) system. Many XAI approaches have emerged in recent years. Consequently, a subfield related to the evaluation of XAI methods has gained considerable attention, with the aim to determine which methods provide the best explanation using various approaches and criteria. However, the literature lacks a comparison of the evaluation metrics themselves, that one can use to evaluate XAI methods. This work aims to fill this gap by comparing 14 different metrics when applied to nine state-of-the-art XAI methods and three dummy methods (e.g., random saliency maps) used as references. Experimental results show which of these metrics produces highly correlated results, indicating potential redundancy. We also demonstrate the significant impact of varying the baseline hyperparameter on the evaluation metric values. Finally, we use dummy methods to assess the reliability of metrics in terms of ranking, pointing out their limitations.
Urban Sound Classification : striving towards a fair comparison
Oct 22, 2020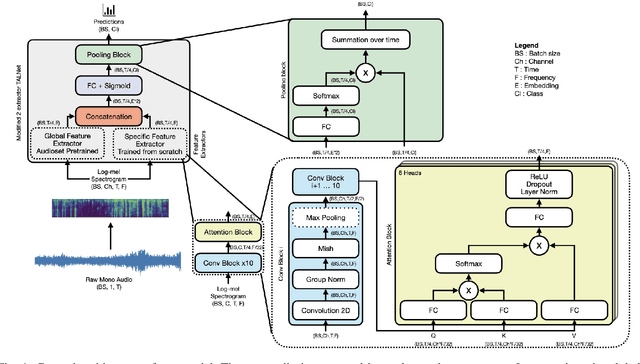
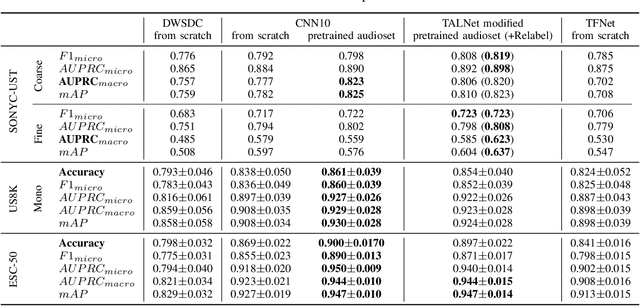
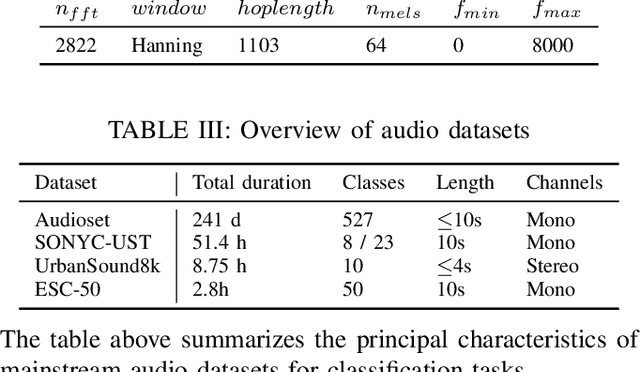
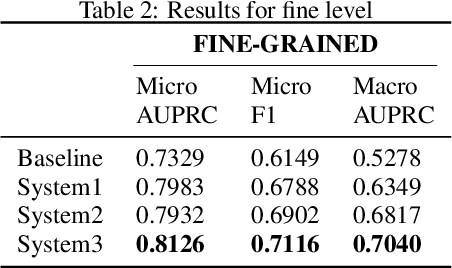
Urban sound classification has been achieving remarkable progress and is still an active research area in audio pattern recognition. In particular, it allows to monitor the noise pollution, which becomes a growing concern for large cities. The contribution of this paper is two-fold. First, we present our DCASE 2020 task 5 winning solution which aims at helping the monitoring of urban noise pollution. It achieves a macro-AUPRC of 0.82 / 0.62 for the coarse / fine classification on validation set. Moreover, it reaches accuracies of 89.7% and 85.41% respectively on ESC-50 and US8k datasets. Second, it is not easy to find a fair comparison and to reproduce the performance of existing models. Sometimes authors copy-pasting the results of the original papers which is not helping reproducibility. As a result, we provide a fair comparison by using the same input representation, metrics and optimizer to assess performances. We preserve data augmentation used by the original papers. We hope this framework could help evaluate new architectures in this field. For better reproducibility, the code is available on our GitHub repository.
CRNNs for Urban Sound Tagging with spatiotemporal context
Sep 30, 2020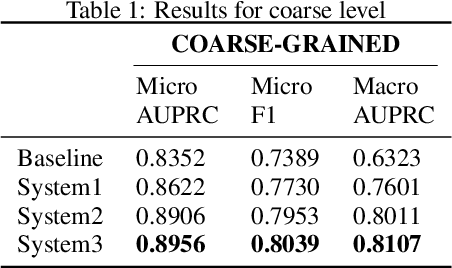
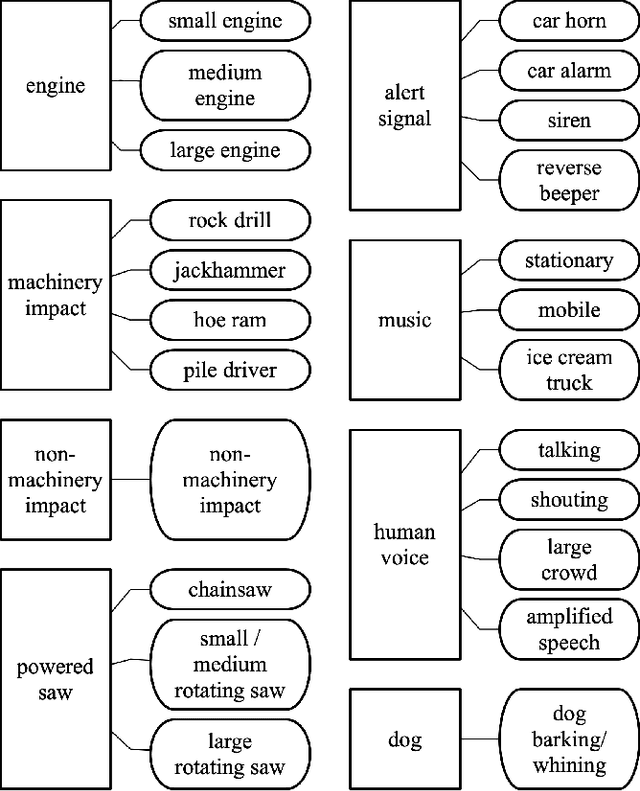
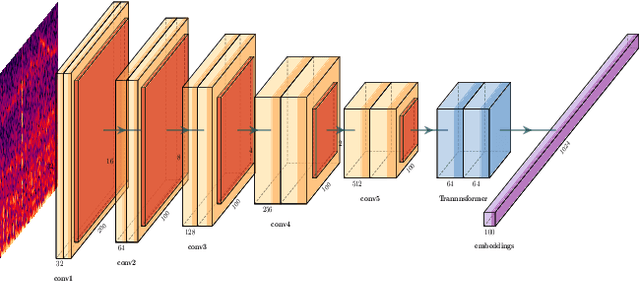
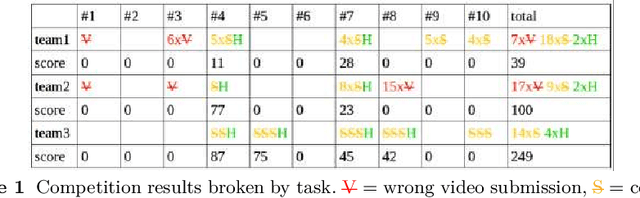
This paper describes CRNNs we used to participate in Task 5 of the DCASE 2020 challenge. This task focuses on hierarchical multilabel urban sound tagging with spatiotemporal context. The code is available on our GitHub repository at https://github.com/multitel-ai/urban-sound-tagging.
Proceedings of eNTERFACE 2015 Workshop on Intelligent Interfaces
Jan 19, 2018
The 11th Summer Workshop on Multimodal Interfaces eNTERFACE 2015 was hosted by the Numediart Institute of Creative Technologies of the University of Mons from August 10th to September 2015. During the four weeks, students and researchers from all over the world came together in the Numediart Institute of the University of Mons to work on eight selected projects structured around intelligent interfaces. Eight projects were selected and their reports are shown here.
A study of parameters affecting visual saliency assessment
Jul 22, 2013

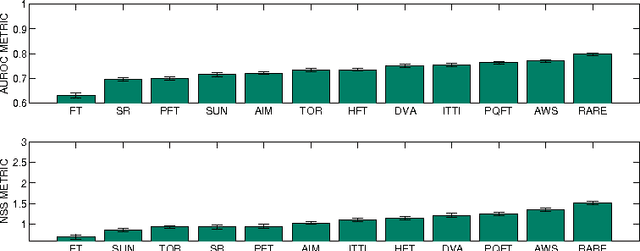

Since the early 2000s, computational visual saliency has been a very active research area. Each year, more and more new models are published in the main computer vision conferences. Nowadays, one of the big challenges is to find a way to fairly evaluate all of these models. In this paper, a new framework is proposed to assess models of visual saliency. This evaluation is divided into three experiments leading to the proposition of a new evaluation framework. Each experiment is based on a basic question: 1) there are two ground truths for saliency evaluation: what are the differences between eye fixations and manually segmented salient regions?, 2) the properties of the salient regions: for example, do large, medium and small salient regions present different difficulties for saliency models? and 3) the metrics used to assess saliency models: what advantages would there be to mix them with PCA? Statistical analysis is used here to answer each of these three questions.