 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetics as Structural Harm: Algorithmic Lookism Across Text-to-Image Generation and Classification
Jan 15, 2026This paper examines algorithmic lookism-the systematic preferential treatment based on physical appearance-in text-to-image (T2I) generative AI and a downstream gender classification task. Through the analysis of 26,400 synthetic faces created with Stable Diffusion 2.1 and 3.5 Medium, we demonstrate how generative AI models systematically associate facial attractiveness with positive attributes and vice-versa, mirroring socially constructed biases rather than evidence-based correlations. Furthermore, we find significant gender bias in three gender classification algorithms depending on the attributes of the input faces. Our findings reveal three critical harms: (1) the systematic encoding of attractiveness-positive attribute associations in T2I models; (2) gender disparities in classification systems, where women's faces, particularly those generated with negative attributes, suffer substantially higher misclassification rates than men's; and (3) intensifying aesthetic constraints in newer models through age homogenization, gendered exposure patterns, and geographic reductionism. These convergent patterns reveal algorithmic lookism as systematic infrastructure operating across AI vision systems, compounding existing inequalities through both representation and recognition. Disclaimer: This work includes visual and textual content that reflects stereotypical associations between physical appearance and socially constructed attributes, including gender, race, and traits associated with social desirability. Any such associations found in this study emerge from the biases embedded in generative AI systems-not from empirical truths or the authors' views.
Found in Translation: semantic approaches for enhancing AI interpretability in face verification
Jan 06, 2025The increasing complexity of machine learning models in computer vision, particularly in face verification, requires the development of explainable artificial intelligence (XAI) to enhance interpretability and transparency. This study extends previous work by integrating semantic concepts derived from human cognitive processes into XAI frameworks to bridge the comprehension gap between model outputs and human understanding. We propose a novel approach combining global and local explanations, using semantic features defined by user-selected facial landmarks to generate similarity maps and textual explanations via large language models (LLMs). The methodology was validated through quantitative experiments and user feedback, demonstrating improved interpretability. Results indicate that our semantic-based approach, particularly the most detailed set, offers a more nuanced understanding of model decisions than traditional methods. User studies highlight a preference for our semantic explanations over traditional pixelbased heatmaps, emphasizing the benefits of human-centric interpretability in AI. This work contributes to the ongoing efforts to create XAI frameworks that align AI models behaviour with human cognitive processes, fostering trust and acceptance in critical applications.
User Preferences for Large Language Model versus Template-Based Explanations of Movie Recommendations: A Pilot Study
Sep 10, 2024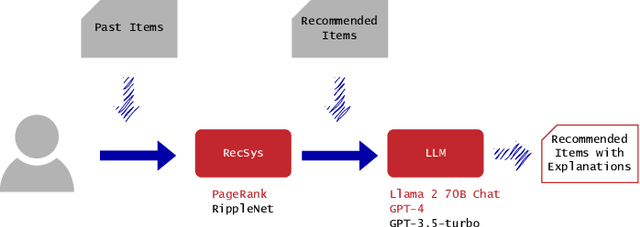
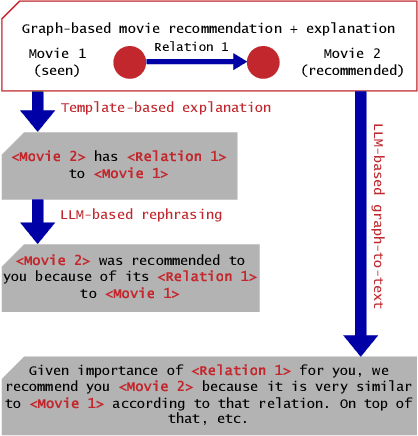

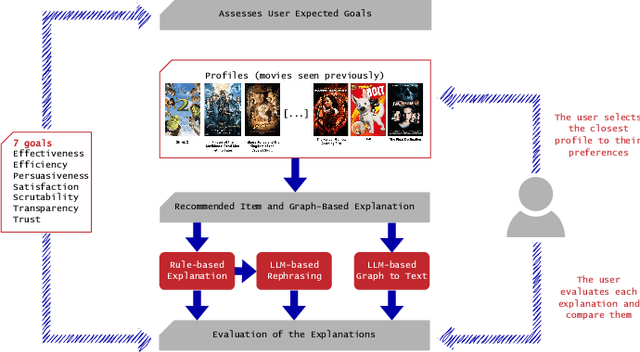
Recommender systems have become integral to our digital experiences, from online shopping to streaming platforms. Still, the rationale behind their suggestions often remains opaque to users. While some systems employ a graph-based approach, offering inherent explainability through paths associating recommended items and seed items, non-experts could not easily understand these explanations. A popular alternative is to convert graph-based explanations into textual ones using a template and an algorithm, which we denote here as ''template-based'' explanations. Yet, these can sometimes come across as impersonal or uninspiring. A novel method would be to employ large language models (LLMs) for this purpose, which we denote as ''LLM-based''. To assess the effectiveness of LLMs in generating more resonant explanations, we conducted a pilot study with 25 participants. They were presented with three explanations: (1) traditional template-based, (2) LLM-based rephrasing of the template output, and (3) purely LLM-based explanations derived from the graph-based explanations. Although subject to high variance, preliminary findings suggest that LLM-based explanations may provide a richer and more engaging user experience, further aligning with user expectations. This study sheds light on the potential limitations of current explanation methods and offers promising directions for leveraging large language models to improve user satisfaction and trust in recommender systems.
An Experimental Investigation into the Evaluation of Explainability Methods
May 25, 2023EXplainable Artificial Intelligence (XAI) aims to help users to grasp the reasoning behind the predictions of an Artificial Intelligence (AI) system. Many XAI approaches have emerged in recent years. Consequently, a subfield related to the evaluation of XAI methods has gained considerable attention, with the aim to determine which methods provide the best explanation using various approaches and criteria. However, the literature lacks a comparison of the evaluation metrics themselves, that one can use to evaluate XAI methods. This work aims to fill this gap by comparing 14 different metrics when applied to nine state-of-the-art XAI methods and three dummy methods (e.g., random saliency maps) used as references. Experimental results show which of these metrics produces highly correlated results, indicating potential redundancy. We also demonstrate the significant impact of varying the baseline hyperparameter on the evaluation metric values. Finally, we use dummy methods to assess the reliability of metrics in terms of ranking, pointing out their limitations.