 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing image encoders via latent distillation
Jan 09, 2026Deep learning models for image compression often face practical limitations in hardware-constrained applications. Although these models achieve high-quality reconstructions, they are typically complex, heavyweight, and require substantial training data and computational resources. We propose a methodology to partially compress these networks by reducing the size of their encoders. Our approach uses a simplified knowledge distillation strategy to approximate the latent space of the original models with less data and shorter training, yielding lightweight encoders from heavyweight ones. We evaluate the resulting lightweight encoders across two different architectures on the image compression task. Experiments show that our method preserves reconstruction quality and statistical fidelity better than training lightweight encoders with the original loss, making it practical for resource-limited environments.
Found in Translation: semantic approaches for enhancing AI interpretability in face verification
Jan 06, 2025The increasing complexity of machine learning models in computer vision, particularly in face verification, requires the development of explainable artificial intelligence (XAI) to enhance interpretability and transparency. This study extends previous work by integrating semantic concepts derived from human cognitive processes into XAI frameworks to bridge the comprehension gap between model outputs and human understanding. We propose a novel approach combining global and local explanations, using semantic features defined by user-selected facial landmarks to generate similarity maps and textual explanations via large language models (LLMs). The methodology was validated through quantitative experiments and user feedback, demonstrating improved interpretability. Results indicate that our semantic-based approach, particularly the most detailed set, offers a more nuanced understanding of model decisions than traditional methods. User studies highlight a preference for our semantic explanations over traditional pixelbased heatmaps, emphasizing the benefits of human-centric interpretability in AI. This work contributes to the ongoing efforts to create XAI frameworks that align AI models behaviour with human cognitive processes, fostering trust and acceptance in critical applications.
Reasoning with trees: interpreting CNNs using hierarchies
Jun 19, 2024Challenges persist in providing interpretable explanations for neural network reasoning in explainable AI (xAI). Existing methods like Integrated Gradients produce noisy maps, and LIME, while intuitive, may deviate from the model's reasoning. We introduce a framework that uses hierarchical segmentation techniques for faithful and interpretable explanations of Convolutional Neural Networks (CNNs). Our method constructs model-based hierarchical segmentations that maintain the model's reasoning fidelity and allows both human-centric and model-centric segmentation. This approach offers multiscale explanations, aiding bias identification and enhancing understanding of neural network decision-making. Experiments show that our framework, xAiTrees, delivers highly interpretable and faithful model explanations, not only surpassing traditional xAI methods but shedding new light on a novel approach to enhancing xAI interpretability. Code at: https://github.com/CarolMazini/reasoning_with_trees .
Transforming gradient-based techniques into interpretable methods
Jan 25, 2024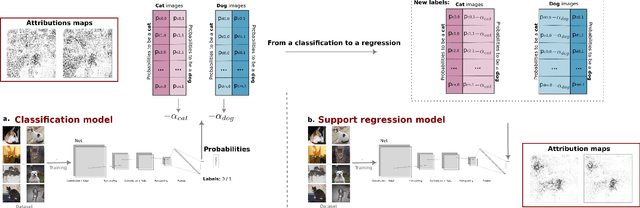
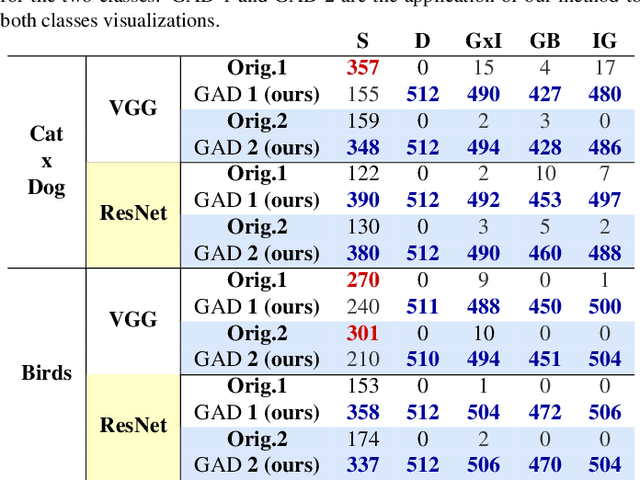

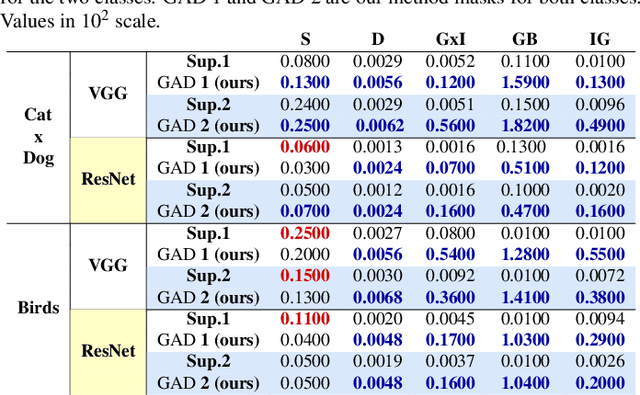
The explication of Convolutional Neural Networks (CNN) through xAI techniques often poses challenges in interpretation. The inherent complexity of input features, notably pixels extracted from images, engenders complex correlations. Gradient-based methodologies, exemplified by Integrated Gradients (IG), effectively demonstrate the significance of these features. Nevertheless, the conversion of these explanations into images frequently yields considerable noise. Presently, we introduce GAD (Gradient Artificial Distancing) as a supportive framework for gradient-based techniques. Its primary objective is to accentuate influential regions by establishing distinctions between classes. The essence of GAD is to limit the scope of analysis during visualization and, consequently reduce image noise. Empirical investigations involving occluded images have demonstrated that the identified regions through this methodology indeed play a pivotal role in facilitating class differentiation.
Unsupervised discovery of Interpretable Visual Concepts
Aug 31, 2023Providing interpretability of deep-learning models to non-experts, while fundamental for a responsible real-world usage, is challenging. Attribution maps from xAI techniques, such as Integrated Gradients, are a typical example of a visualization technique containing a high level of information, but with difficult interpretation. In this paper, we propose two methods, Maximum Activation Groups Extraction (MAGE) and Multiscale Interpretable Visualization (Ms-IV), to explain the model's decision, enhancing global interpretability. MAGE finds, for a given CNN, combinations of features which, globally, form a semantic meaning, that we call concepts. We group these similar feature patterns by clustering in ``concepts'', that we visualize through Ms-IV. This last method is inspired by Occlusion and Sensitivity analysis (incorporating causality), and uses a novel metric, called Class-aware Order Correlation (CaOC), to globally evaluate the most important image regions according to the model's decision space. We compare our approach to xAI methods such as LIME and Integrated Gradients. Experimental results evince the Ms-IV higher localization and faithfulness values. Finally, qualitative evaluation of combined MAGE and Ms-IV demonstrate humans' ability to agree, based on the visualization, on the decision of clusters' concepts; and, to detect, among a given set of networks, the existence of bias.