 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork-Wide Traffic Volume Estimation from Speed Profiles using a Spatio-Temporal Graph Neural Network with Directed Spatial Attention
Dec 15, 2025Existing traffic volume estimation methods typically address either forecasting traffic on sensor-equipped roads or spatially imputing missing volumes using nearby sensors. While forecasting models generally disregard unmonitored roads by design, spatial imputation methods explicitly address network-wide estimation; yet this approach relies on volume data at inference time, limiting its applicability in sensor-scarce cities. Unlike traffic volume data, probe vehicle speeds and static road attributes are more broadly accessible and support full coverage of road segments in most urban networks. In this work, we present the Hybrid Directed-Attention Spatio-Temporal Graph Neural Network (HDA-STGNN), an inductive deep learning framework designed to tackle the network-wide volume estimation problem. Our approach leverages speed profiles, static road attributes, and road network topology to predict daily traffic volume profiles across all road segments in the network. To evaluate the effectiveness of our approach, we perform extensive ablation studies that demonstrate the model's capacity to capture complex spatio-temporal dependencies and highlight the value of topological information for accurate network-wide traffic volume estimation without relying on volume data at inference time.
FLIM-based Salient Object Detection Networks with Adaptive Decoders
Apr 29, 2025



Salient Object Detection (SOD) methods can locate objects that stand out in an image, assign higher values to their pixels in a saliency map, and binarize the map outputting a predicted segmentation mask. A recent tendency is to investigate pre-trained lightweight models rather than deep neural networks in SOD tasks, coping with applications under limited computational resources. In this context, we have investigated lightweight networks using a methodology named Feature Learning from Image Markers (FLIM), which assumes that the encoder's kernels can be estimated from marker pixels on discriminative regions of a few representative images. This work proposes flyweight networks, hundreds of times lighter than lightweight models, for SOD by combining a FLIM encoder with an adaptive decoder, whose weights are estimated for each input image by a given heuristic function. Such FLIM networks are trained from three to four representative images only and without backpropagation, making the models suitable for applications under labeled data constraints as well. We study five adaptive decoders; two of them are introduced here. Differently from the previous ones that rely on one neuron per pixel with shared weights, the heuristic functions of the new adaptive decoders estimate the weights of each neuron per pixel. We compare FLIM models with adaptive decoders for two challenging SOD tasks with three lightweight networks from the state-of-the-art, two FLIM networks with decoders trained by backpropagation, and one FLIM network whose labeled markers define the decoder's weights. The experiments demonstrate the advantages of the proposed networks over the baselines, revealing the importance of further investigating such methods in new applications.
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
Feb 17, 2025We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the violation-of-expectation framework, we find that video prediction models trained to predict outcomes in a learned representation space demonstrate an understanding of various intuitive physics properties, such as object permanence and shape consistency. In contrast, video prediction in pixel space and multimodal large language models, which reason through text, achieve performance closer to chance. Our comparisons of these architectures reveal that jointly learning an abstract representation space while predicting missing parts of sensory input, akin to predictive coding, is sufficient to acquire an understanding of intuitive physics, and that even models trained on one week of unique video achieve above chance performance. This challenges the idea that core knowledge -- a set of innate systems to help understand the world -- needs to be hardwired to develop an understanding of intuitive physics.
Shape Transformation Driven by Active Contour for Class-Imbalanced Semi-Supervised Medical Image Segmentation
Oct 18, 2024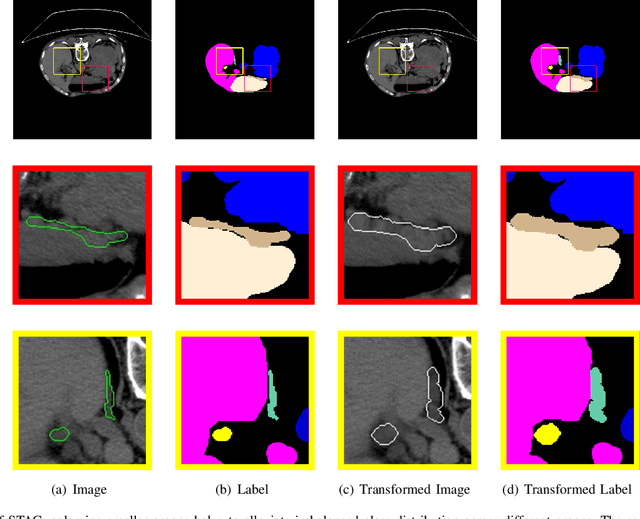
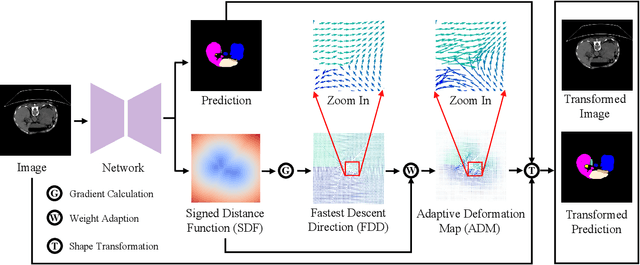
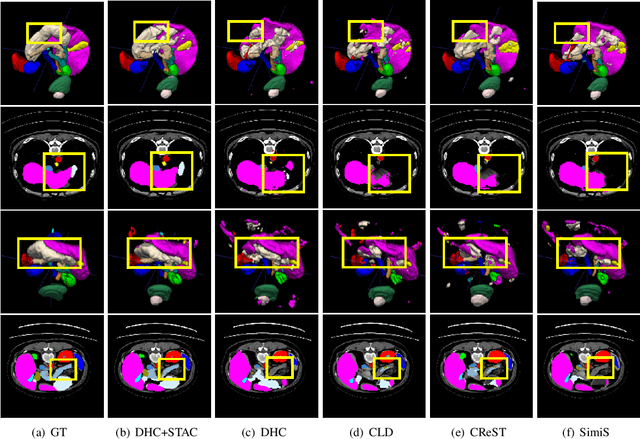
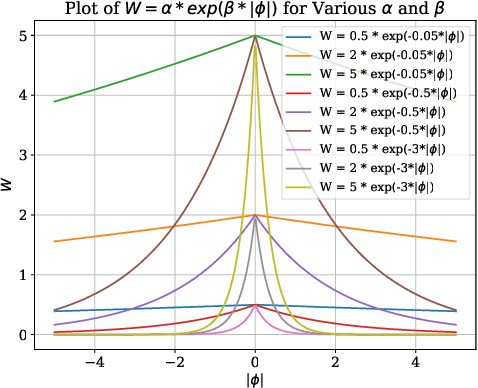
Annotating 3D medical images demands expert knowledge and is time-consuming. As a result, semi-supervised learning (SSL) approaches have gained significant interest in 3D medical image segmentation. The significant size differences among various organs in the human body lead to imbalanced class distribution, which is a major challenge in the real-world application of these SSL approaches. To address this issue, we develop a novel Shape Transformation driven by Active Contour (STAC), that enlarges smaller organs to alleviate imbalanced class distribution across different organs. Inspired by curve evolution theory in active contour methods, STAC employs a signed distance function (SDF) as the level set function, to implicitly represent the shape of organs, and deforms voxels in the direction of the steepest descent of SDF (i.e., the normal vector). To ensure that the voxels far from expansion organs remain unchanged, we design an SDF-based weight function to control the degree of deformation for each voxel. We then use STAC as a data-augmentation process during the training stage. Experimental results on two benchmark datasets demonstrate that the proposed method significantly outperforms some state-of-the-art methods. Source code is publicly available at https://github.com/GuGuLL123/STAC.
Evolutionary Retrofitting
Oct 15, 2024AfterLearnER (After Learning Evolutionary Retrofitting) consists in applying non-differentiable optimization, including evolutionary methods, to refine fully-trained machine learning models by optimizing a set of carefully chosen parameters or hyperparameters of the model, with respect to some actual, exact, and hence possibly non-differentiable error signal, performed on a subset of the standard validation set. The efficiency of AfterLearnER is demonstrated by tackling non-differentiable signals such as threshold-based criteria in depth sensing, the word error rate in speech re-synthesis, image quality in 3D generative adversarial networks (GANs), image generation via Latent Diffusion Models (LDM), the number of kills per life at Doom, computational accuracy or BLEU in code translation, and human appreciations in image synthesis. In some cases, this retrofitting is performed dynamically at inference time by taking into account user inputs. The advantages of AfterLearnER are its versatility (no gradient is needed), the possibility to use non-differentiable feedback including human evaluations, the limited overfitting, supported by a theoretical study and its anytime behavior. Last but not least, AfterLearnER requires only a minimal amount of feedback, i.e., a few dozens to a few hundreds of scalars, rather than the tens of thousands needed in most related published works. Compared to fine-tuning (typically using the same loss, and gradient-based optimization on a smaller but still big dataset at a fine grain), AfterLearnER uses a minimum amount of data on the real objective function without requiring differentiability.
Reasoning with trees: interpreting CNNs using hierarchies
Jun 19, 2024Challenges persist in providing interpretable explanations for neural network reasoning in explainable AI (xAI). Existing methods like Integrated Gradients produce noisy maps, and LIME, while intuitive, may deviate from the model's reasoning. We introduce a framework that uses hierarchical segmentation techniques for faithful and interpretable explanations of Convolutional Neural Networks (CNNs). Our method constructs model-based hierarchical segmentations that maintain the model's reasoning fidelity and allows both human-centric and model-centric segmentation. This approach offers multiscale explanations, aiding bias identification and enhancing understanding of neural network decision-making. Experiments show that our framework, xAiTrees, delivers highly interpretable and faithful model explanations, not only surpassing traditional xAI methods but shedding new light on a novel approach to enhancing xAI interpretability. Code at: https://github.com/CarolMazini/reasoning_with_trees .
Quantile Activation: departing from single point estimation for better generalization across distortions
May 19, 2024



A classifier is, in its essence, a function which takes an input and returns the class of the input and implicitly assumes an underlying distribution. We argue in this article that one has to move away from this basic tenet to obtain generalisation across distributions. Specifically, the class of the sample should depend on the points from its context distribution for better generalisation across distributions. How does one achieve this? The key idea is to adapt the outputs of each neuron of the network to its context distribution. We propose quantile activation, QACT, which, in simple terms, outputs the relative quantile of the sample in its context distribution, instead of the actual values in traditional networks. The scope of this article is to validate the proposed activation across several experimental settings, and compare it with conventional techniques. For this, we use the datasets developed to test robustness against distortions CIFAR10C, CIFAR100C, MNISTC, TinyImagenetC, and show that we achieve a significantly higher generalisation across distortions than the conventional classifiers, across different architectures. Although this paper is only a proof of concept, we surprisingly find that this approach outperforms DINOv2(small) at large distortions, even though DINOv2 is trained with a far bigger network on a considerably larger dataset.
Learning and Leveraging World Models in Visual Representation Learning
Mar 01, 2024


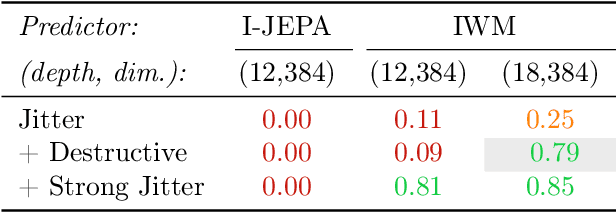
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of an input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space. We study the recipe of learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods. Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modelling.
A Novel Approach to Regularising 1NN classifier for Improved Generalization
Feb 13, 2024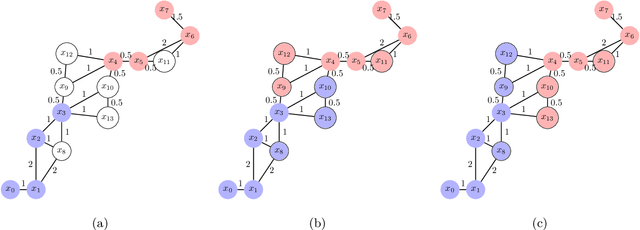



In this paper, we propose a class of non-parametric classifiers, that learn arbitrary boundaries and generalize well. Our approach is based on a novel way to regularize 1NN classifiers using a greedy approach. We refer to this class of classifiers as Watershed Classifiers. 1NN classifiers are known to trivially over-fit but have very large VC dimension, hence do not generalize well. We show that watershed classifiers can find arbitrary boundaries on any dense enough dataset, and, at the same time, have very small VC dimension; hence a watershed classifier leads to good generalization. Traditional approaches to regularize 1NN classifiers are to consider $K$ nearest neighbours. Neighbourhood component analysis (NCA) proposes a way to learn representations consistent with ($n-1$) nearest neighbour classifier, where $n$ denotes the size of the dataset. In this article, we propose a loss function which can learn representations consistent with watershed classifiers, and show that it outperforms the NCA baseline.
Clustering Dynamics for Improved Speed Prediction Deriving from Topographical GPS Registrations
Feb 12, 2024A persistent challenge in the field of Intelligent Transportation Systems is to extract accurate traffic insights from geographic regions with scarce or no data coverage. To this end, we propose solutions for speed prediction using sparse GPS data points and their associated topographical and road design features. Our goal is to investigate whether we can use similarities in the terrain and infrastructure to train a machine learning model that can predict speed in regions where we lack transportation data. For this we create a Temporally Orientated Speed Dictionary Centered on Topographically Clustered Roads, which helps us to provide speed correlations to selected feature configurations. Our results show qualitative and quantitative improvement over new and standard regression methods. The presented framework provides a fresh perspective on devising strategies for missing data traffic analysis.