 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIM-based Salient Object Detection Networks with Adaptive Decoders
Apr 29, 2025



Salient Object Detection (SOD) methods can locate objects that stand out in an image, assign higher values to their pixels in a saliency map, and binarize the map outputting a predicted segmentation mask. A recent tendency is to investigate pre-trained lightweight models rather than deep neural networks in SOD tasks, coping with applications under limited computational resources. In this context, we have investigated lightweight networks using a methodology named Feature Learning from Image Markers (FLIM), which assumes that the encoder's kernels can be estimated from marker pixels on discriminative regions of a few representative images. This work proposes flyweight networks, hundreds of times lighter than lightweight models, for SOD by combining a FLIM encoder with an adaptive decoder, whose weights are estimated for each input image by a given heuristic function. Such FLIM networks are trained from three to four representative images only and without backpropagation, making the models suitable for applications under labeled data constraints as well. We study five adaptive decoders; two of them are introduced here. Differently from the previous ones that rely on one neuron per pixel with shared weights, the heuristic functions of the new adaptive decoders estimate the weights of each neuron per pixel. We compare FLIM models with adaptive decoders for two challenging SOD tasks with three lightweight networks from the state-of-the-art, two FLIM networks with decoders trained by backpropagation, and one FLIM network whose labeled markers define the decoder's weights. The experiments demonstrate the advantages of the proposed networks over the baselines, revealing the importance of further investigating such methods in new applications.
Co-Training with Active Contrastive Learning and Meta-Pseudo-Labeling on 2D Projections for Deep Semi-Supervised Learning
Apr 25, 2025A major challenge that prevents the training of DL models is the limited availability of accurately labeled data. This shortcoming is highlighted in areas where data annotation becomes a time-consuming and error-prone task. In this regard, SSL tackles this challenge by capitalizing on scarce labeled and abundant unlabeled data; however, SoTA methods typically depend on pre-trained features and large validation sets to learn effective representations for classification tasks. In addition, the reduced set of labeled data is often randomly sampled, neglecting the selection of more informative samples. Here, we present active-DeepFA, a method that effectively combines CL, teacher-student-based meta-pseudo-labeling and AL to train non-pretrained CNN architectures for image classification in scenarios of scarcity of labeled and abundance of unlabeled data. It integrates DeepFA into a co-training setup that implements two cooperative networks to mitigate confirmation bias from pseudo-labels. The method starts with a reduced set of labeled samples by warming up the networks with supervised CL. Afterward and at regular epoch intervals, label propagation is performed on the 2D projections of the networks' deep features. Next, the most reliable pseudo-labels are exchanged between networks in a cross-training fashion, while the most meaningful samples are annotated and added into the labeled set. The networks independently minimize an objective loss function comprising supervised contrastive, supervised and semi-supervised loss components, enhancing the representations towards image classification. Our approach is evaluated on three challenging biological image datasets using only 5% of labeled samples, improving baselines and outperforming six other SoTA methods. In addition, it reduces annotation effort by achieving comparable results to those of its counterparts with only 3% of labeled data.
Flyweight FLIM Networks for Salient Object Detection in Biomedical Images
Apr 15, 2025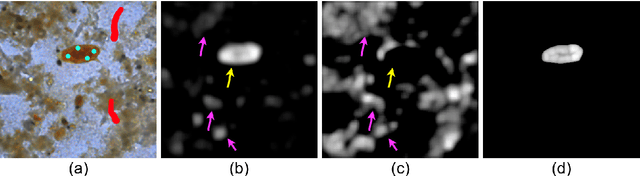

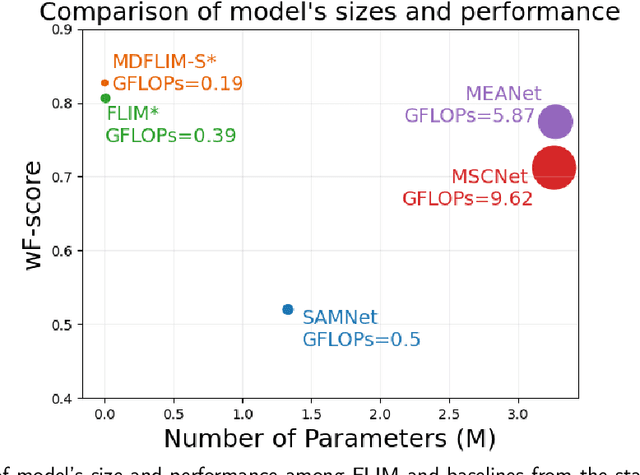
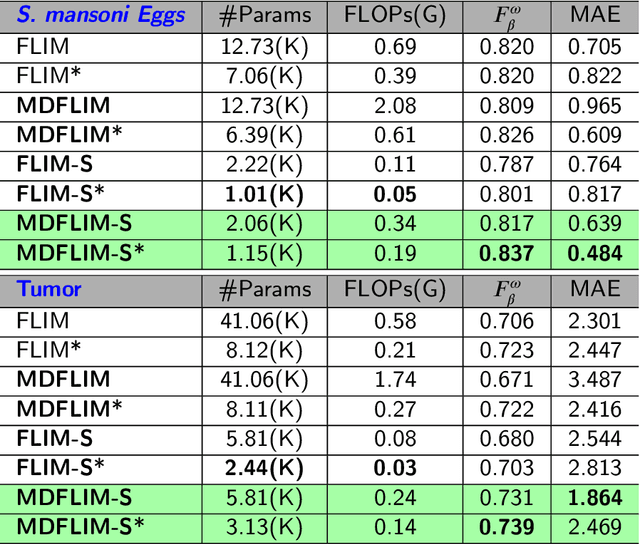
Salient Object Detection (SOD) with deep learning often requires substantial computational resources and large annotated datasets, making it impractical for resource-constrained applications. Lightweight models address computational demands but typically strive in complex and scarce labeled-data scenarios. Feature Learning from Image Markers (FLIM) learns an encoder's convolutional kernels among image patches extracted from discriminative regions marked on a few representative images, dismissing large annotated datasets, pretraining, and backpropagation. Such a methodology exploits information redundancy commonly found in biomedical image applications. This study presents methods to learn dilated-separable convolutional kernels and multi-dilation layers without backpropagation for FLIM networks. It also proposes a novel network simplification method to reduce kernel redundancy and encoder size. By combining a FLIM encoder with an adaptive decoder, a concept recently introduced to estimate a pointwise convolution per image, this study presents very efficient (named flyweight) SOD models for biomedical images. Experimental results in challenging datasets demonstrate superior efficiency and effectiveness to lightweight models. By requiring significantly fewer parameters and floating-point operations, the results show competitive effectiveness to heavyweight models. These advances highlight the potential of FLIM networks for data-limited and resource-constrained applications with information redundancy.
Multi-level Cellular Automata for FLIM networks
Apr 15, 2025The necessity of abundant annotated data and complex network architectures presents a significant challenge in deep-learning Salient Object Detection (deep SOD) and across the broader deep-learning landscape. This challenge is particularly acute in medical applications in developing countries with limited computational resources. Combining modern and classical techniques offers a path to maintaining competitive performance while enabling practical applications. Feature Learning from Image Markers (FLIM) methodology empowers experts to design convolutional encoders through user-drawn markers, with filters learned directly from these annotations. Recent findings demonstrate that coupling a FLIM encoder with an adaptive decoder creates a flyweight network suitable for SOD, requiring significantly fewer parameters than lightweight models and eliminating the need for backpropagation. Cellular Automata (CA) methods have proven successful in data-scarce scenarios but require proper initialization -- typically through user input, priors, or randomness. We propose a practical intersection of these approaches: using FLIM networks to initialize CA states with expert knowledge without requiring user interaction for each image. By decoding features from each level of a FLIM network, we can initialize multiple CAs simultaneously, creating a multi-level framework. Our method leverages the hierarchical knowledge encoded across different network layers, merging multiple saliency maps into a high-quality final output that functions as a CA ensemble. Benchmarks across two challenging medical datasets demonstrate the competitiveness of our multi-level CA approach compared to established models in the deep SOD literature.