 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Superpixel Segmentation Methods Influence Deforestation Image Classification?
Oct 06, 2025
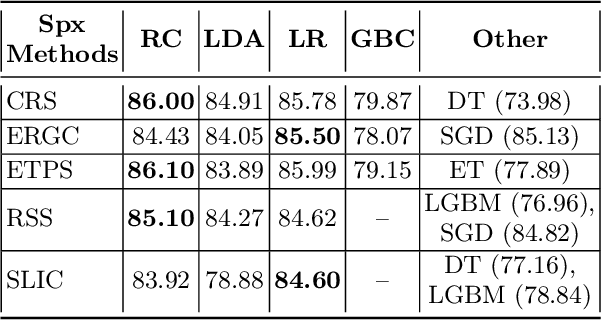

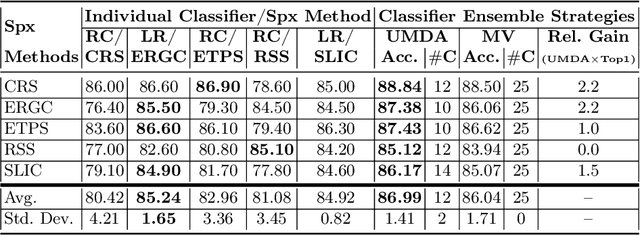
Image segmentation is a crucial step in various visual applications, including environmental monitoring through remote sensing. In the context of the ForestEyes project, which combines citizen science and machine learning to detect deforestation in tropical forests, image segments are used for labeling by volunteers and subsequent model training. Traditionally, the Simple Linear Iterative Clustering (SLIC) algorithm is adopted as the segmentation method. However, recent studies have indicated that other superpixel-based methods outperform SLIC in remote sensing image segmentation, and might suggest that they are more suitable for the task of detecting deforested areas. In this sense, this study investigated the impact of the four best segmentation methods, together with SLIC, on the training of classifiers for the target application. Initially, the results showed little variation in performance among segmentation methods, even when selecting the top five classifiers using the PyCaret AutoML library. However, by applying a classifier fusion approach (ensemble of classifiers), noticeable improvements in balanced accuracy were observed, highlighting the importance of both the choice of segmentation method and the combination of machine learning-based models for deforestation detection tasks.
FLIM-based Salient Object Detection Networks with Adaptive Decoders
Apr 29, 2025



Salient Object Detection (SOD) methods can locate objects that stand out in an image, assign higher values to their pixels in a saliency map, and binarize the map outputting a predicted segmentation mask. A recent tendency is to investigate pre-trained lightweight models rather than deep neural networks in SOD tasks, coping with applications under limited computational resources. In this context, we have investigated lightweight networks using a methodology named Feature Learning from Image Markers (FLIM), which assumes that the encoder's kernels can be estimated from marker pixels on discriminative regions of a few representative images. This work proposes flyweight networks, hundreds of times lighter than lightweight models, for SOD by combining a FLIM encoder with an adaptive decoder, whose weights are estimated for each input image by a given heuristic function. Such FLIM networks are trained from three to four representative images only and without backpropagation, making the models suitable for applications under labeled data constraints as well. We study five adaptive decoders; two of them are introduced here. Differently from the previous ones that rely on one neuron per pixel with shared weights, the heuristic functions of the new adaptive decoders estimate the weights of each neuron per pixel. We compare FLIM models with adaptive decoders for two challenging SOD tasks with three lightweight networks from the state-of-the-art, two FLIM networks with decoders trained by backpropagation, and one FLIM network whose labeled markers define the decoder's weights. The experiments demonstrate the advantages of the proposed networks over the baselines, revealing the importance of further investigating such methods in new applications.
Multi-level Cellular Automata for FLIM networks
Apr 15, 2025The necessity of abundant annotated data and complex network architectures presents a significant challenge in deep-learning Salient Object Detection (deep SOD) and across the broader deep-learning landscape. This challenge is particularly acute in medical applications in developing countries with limited computational resources. Combining modern and classical techniques offers a path to maintaining competitive performance while enabling practical applications. Feature Learning from Image Markers (FLIM) methodology empowers experts to design convolutional encoders through user-drawn markers, with filters learned directly from these annotations. Recent findings demonstrate that coupling a FLIM encoder with an adaptive decoder creates a flyweight network suitable for SOD, requiring significantly fewer parameters than lightweight models and eliminating the need for backpropagation. Cellular Automata (CA) methods have proven successful in data-scarce scenarios but require proper initialization -- typically through user input, priors, or randomness. We propose a practical intersection of these approaches: using FLIM networks to initialize CA states with expert knowledge without requiring user interaction for each image. By decoding features from each level of a FLIM network, we can initialize multiple CAs simultaneously, creating a multi-level framework. Our method leverages the hierarchical knowledge encoded across different network layers, merging multiple saliency maps into a high-quality final output that functions as a CA ensemble. Benchmarks across two challenging medical datasets demonstrate the competitiveness of our multi-level CA approach compared to established models in the deep SOD literature.
Exploring Superpixel Segmentation Methods in the Context of Citizen Science and Deforestation Detection
Nov 26, 2024
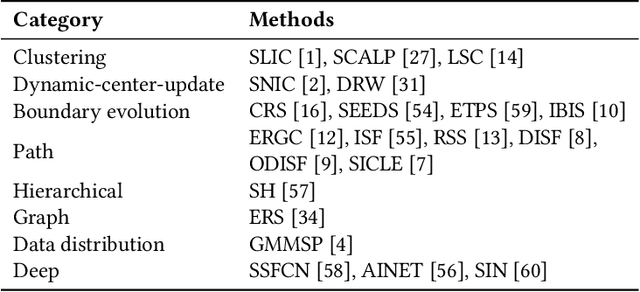

Tropical forests play an essential role in the planet's ecosystem, making the conservation of these biomes a worldwide priority. However, ongoing deforestation and degradation pose a significant threat to their existence, necessitating effective monitoring and the proposal of actions to mitigate the damage caused by these processes. In this regard, initiatives range from government and private sector monitoring programs to solutions based on citizen science campaigns, for example. Particularly in the context of citizen science campaigns, the segmentation of remote sensing images to identify deforested areas and subsequently submit them to analysis by non-specialized volunteers is necessary. Thus, segmentation using superpixel-based techniques proves to be a viable solution for this important task. Therefore, this paper presents an analysis of 22 superpixel-based segmentation methods applied to remote sensing images, aiming to identify which of them are more suitable for generating segments for citizen science campaigns. The results reveal that seven of the segmentation methods outperformed the baseline method (SLIC) currently employed in the ForestEyes citizen science project, indicating an opportunity for improvement in this important stage of campaign development.
How to Identify Good Superpixels for Deforestation Detection on Tropical Rainforests
Sep 06, 2024
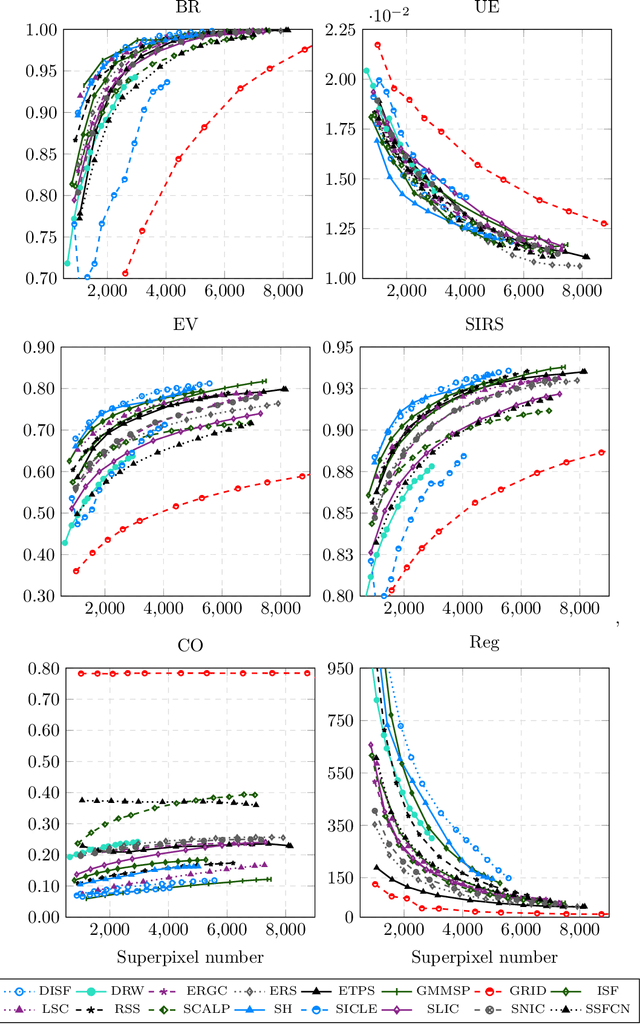
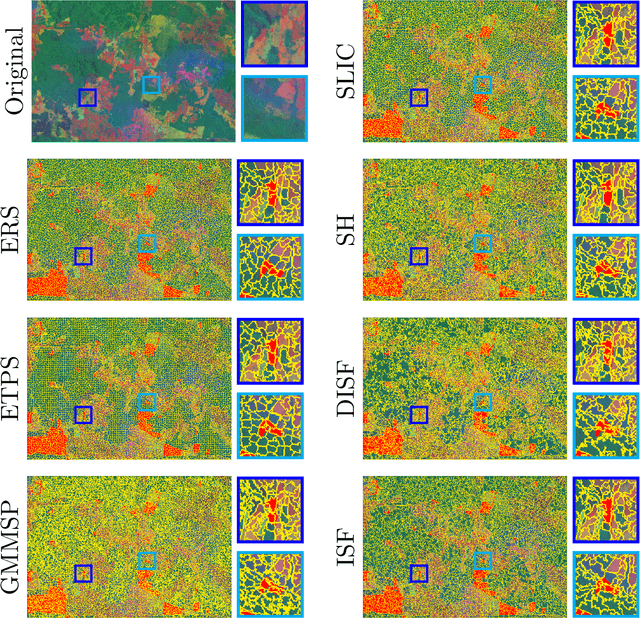
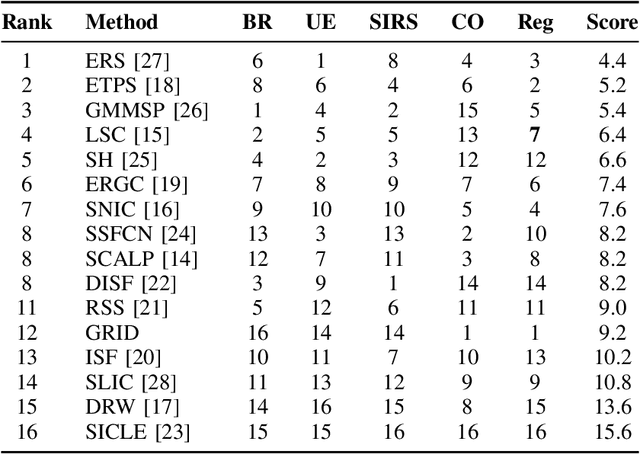
The conservation of tropical forests is a topic of significant social and ecological relevance due to their crucial role in the global ecosystem. Unfortunately, deforestation and degradation impact millions of hectares annually, requiring government or private initiatives for effective forest monitoring. However, identifying deforested regions in satellite images is challenging due to data imbalance, image resolution, low-contrast regions, and occlusion. Superpixel segmentation can overcome these drawbacks, reducing workload and preserving important image boundaries. However, most works for remote sensing images do not exploit recent superpixel methods. In this work, we evaluate 16 superpixel methods in satellite images to support a deforestation detection system in tropical forests. We also assess the performance of superpixel methods for the target task, establishing a relationship with segmentation methodological evaluation. According to our results, ERS, GMMSP, and DISF perform best on UE, BR, and SIRS, respectively, whereas ERS has the best trade-off with CO and Reg. In classification, SH, DISF, and ISF perform best on RGB, UMDA, and PCA compositions, respectively. According to our experiments, superpixel methods with better trade-offs between delineation, homogeneity, compactness, and regularity are more suitable for identifying good superpixels for deforestation detection tasks.
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021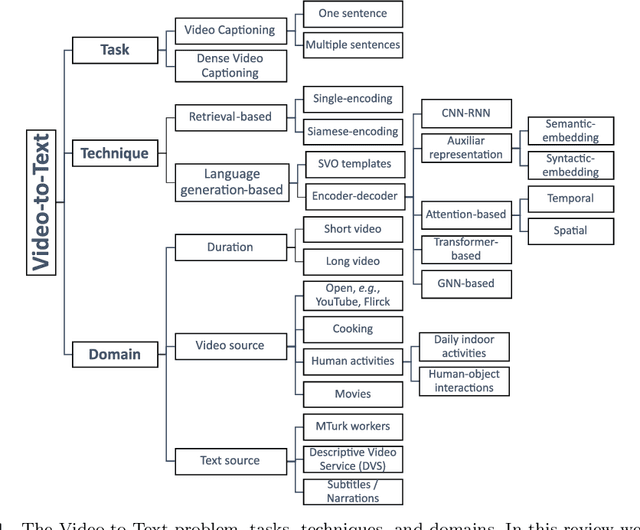
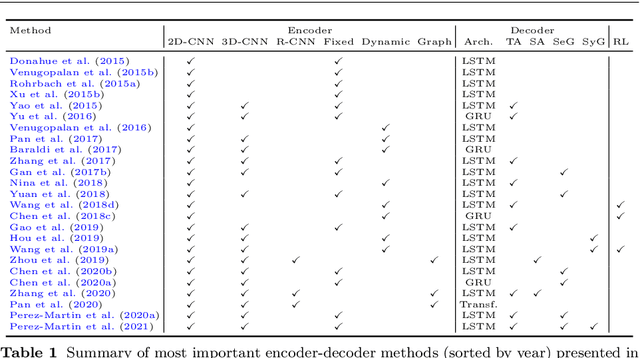
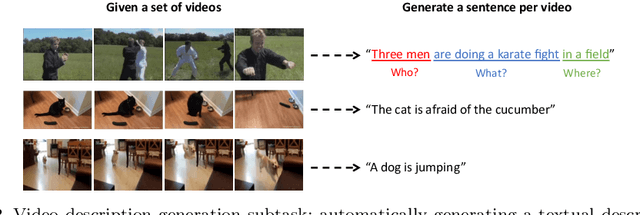
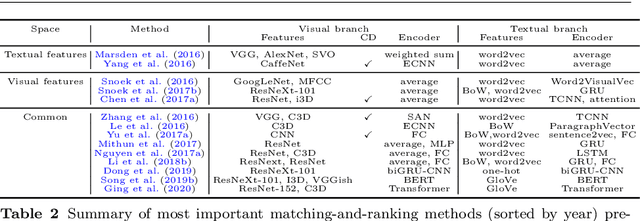
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
A Mid-level Video Representation based on Binary Descriptors: A Case Study for Pornography Detection
May 12, 2016
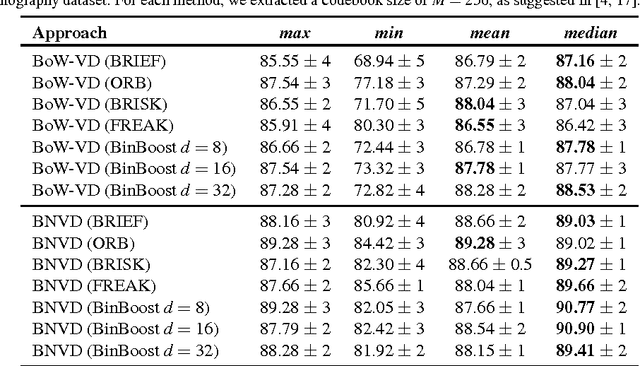
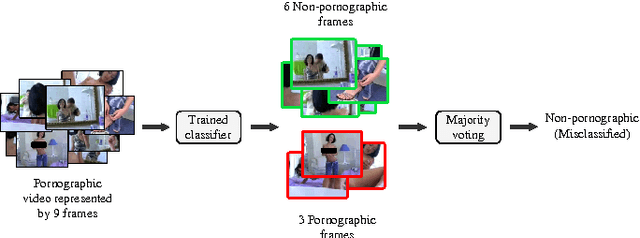

With the growing amount of inappropriate content on the Internet, such as pornography, arises the need to detect and filter such material. The reason for this is given by the fact that such content is often prohibited in certain environments (e.g., schools and workplaces) or for certain publics (e.g., children). In recent years, many works have been mainly focused on detecting pornographic images and videos based on visual content, particularly on the detection of skin color. Although these approaches provide good results, they generally have the disadvantage of a high false positive rate since not all images with large areas of skin exposure are necessarily pornographic images, such as people wearing swimsuits or images related to sports. Local feature based approaches with Bag-of-Words models (BoW) have been successfully applied to visual recognition tasks in the context of pornography detection. Even though existing methods provide promising results, they use local feature descriptors that require a high computational processing time yielding high-dimensional vectors. In this work, we propose an approach for pornography detection based on local binary feature extraction and BossaNova image representation, a BoW model extension that preserves more richly the visual information. Moreover, we propose two approaches for video description based on the combination of mid-level representations namely BossaNova Video Descriptor (BNVD) and BoW Video Descriptor (BoW-VD). The proposed techniques are promising, achieving an accuracy of 92.40%, thus reducing the classification error by 16% over the current state-of-the-art local features approach on the Pornography dataset.
An efficient hierarchical graph based image segmentation
Jun 13, 2012



Hierarchical image segmentation provides region-oriented scalespace, i.e., a set of image segmentations at different detail levels in which the segmentations at finer levels are nested with respect to those at coarser levels. Most image segmentation algorithms, such as region merging algorithms, rely on a criterion for merging that does not lead to a hierarchy, and for which the tuning of the parameters can be difficult. In this work, we propose a hierarchical graph based image segmentation relying on a criterion popularized by Felzenzwalb and Huttenlocher. We illustrate with both real and synthetic images, showing efficiency, ease of use, and robustness of our method.