 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIM-based Salient Object Detection Networks with Adaptive Decoders
Apr 29, 2025



Salient Object Detection (SOD) methods can locate objects that stand out in an image, assign higher values to their pixels in a saliency map, and binarize the map outputting a predicted segmentation mask. A recent tendency is to investigate pre-trained lightweight models rather than deep neural networks in SOD tasks, coping with applications under limited computational resources. In this context, we have investigated lightweight networks using a methodology named Feature Learning from Image Markers (FLIM), which assumes that the encoder's kernels can be estimated from marker pixels on discriminative regions of a few representative images. This work proposes flyweight networks, hundreds of times lighter than lightweight models, for SOD by combining a FLIM encoder with an adaptive decoder, whose weights are estimated for each input image by a given heuristic function. Such FLIM networks are trained from three to four representative images only and without backpropagation, making the models suitable for applications under labeled data constraints as well. We study five adaptive decoders; two of them are introduced here. Differently from the previous ones that rely on one neuron per pixel with shared weights, the heuristic functions of the new adaptive decoders estimate the weights of each neuron per pixel. We compare FLIM models with adaptive decoders for two challenging SOD tasks with three lightweight networks from the state-of-the-art, two FLIM networks with decoders trained by backpropagation, and one FLIM network whose labeled markers define the decoder's weights. The experiments demonstrate the advantages of the proposed networks over the baselines, revealing the importance of further investigating such methods in new applications.
Linking data separation, visual separation, and classifier performance using pseudo-labeling by contrastive learning
Feb 06, 2023



Lacking supervised data is an issue while training deep neural networks (DNNs), mainly when considering medical and biological data where supervision is expensive. Recently, Embedded Pseudo-Labeling (EPL) addressed this problem by using a non-linear projection (t-SNE) from a feature space of the DNN to a 2D space, followed by semi-supervised label propagation using a connectivity-based method (OPFSemi). We argue that the performance of the final classifier depends on the data separation present in the latent space and visual separation present in the projection. We address this by first proposing to use contrastive learning to produce the latent space for EPL by two methods (SimCLR and SupCon) and by their combination, and secondly by showing, via an extensive set of experiments, the aforementioned correlations between data separation, visual separation, and classifier performance. We demonstrate our results by the classification of five real-world challenging image datasets of human intestinal parasites with only 1% supervised samples.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Intestinal Parasites Classification Using Deep Belief Networks
Jan 17, 2021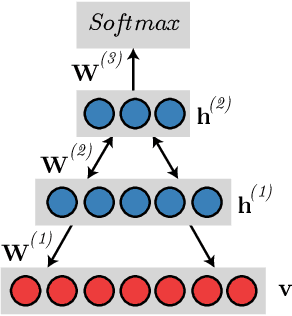

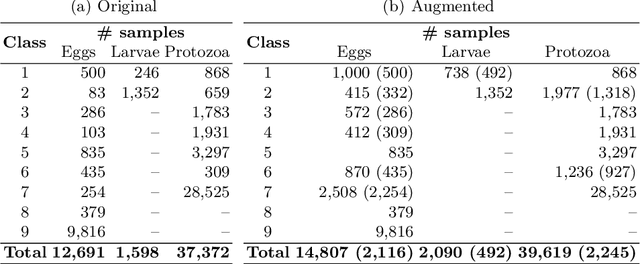
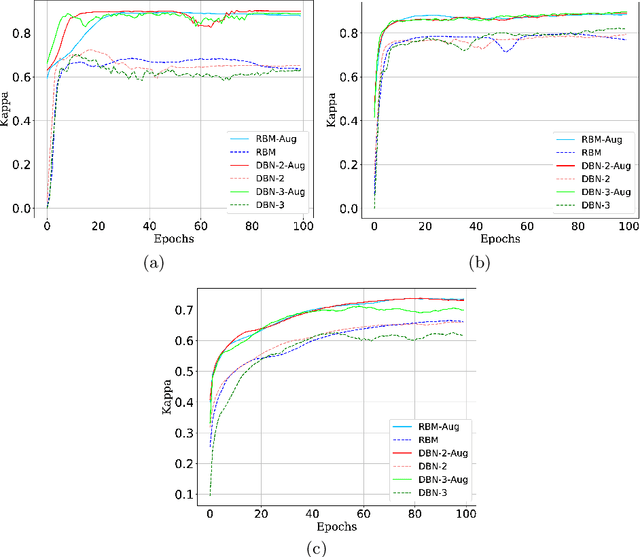
Currently, approximately $4$ billion people are infected by intestinal parasites worldwide. Diseases caused by such infections constitute a public health problem in most tropical countries, leading to physical and mental disorders, and even death to children and immunodeficient individuals. Although subjected to high error rates, human visual inspection is still in charge of the vast majority of clinical diagnoses. In the past years, some works addressed intelligent computer-aided intestinal parasites classification, but they usually suffer from misclassification due to similarities between parasites and fecal impurities. In this paper, we introduce Deep Belief Networks to the context of automatic intestinal parasites classification. Experiments conducted over three datasets composed of eggs, larvae, and protozoa provided promising results, even considering unbalanced classes and also fecal impurities.
Learning CNN filters from user-drawn image markers for coconut-tree image classification
Aug 27, 2020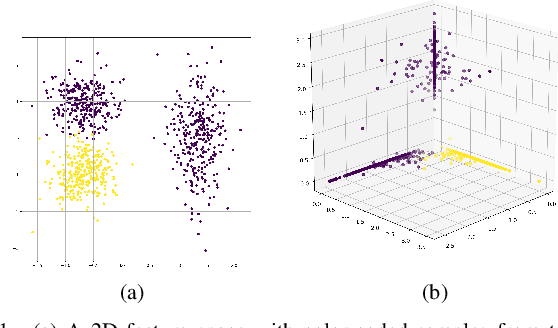
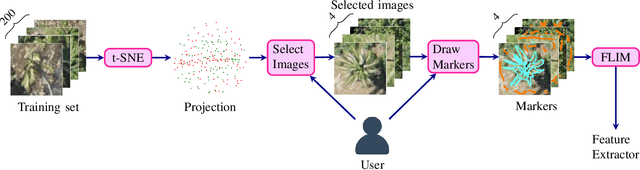


Identifying species of trees in aerial images is essential for land-use classification, plantation monitoring, and impact assessment of natural disasters. The manual identification of trees in aerial images is tedious, costly, and error-prone, so automatic classification methods are necessary. Convolutional Neural Network (CNN) models have well succeeded in image classification applications from different domains. However, CNN models usually require intensive manual annotation to create large training sets. One may conceptually divide a CNN into convolutional layers for feature extraction and fully connected layers for feature space reduction and classification. We present a method that needs a minimal set of user-selected images to train the CNN's feature extractor, reducing the number of required images to train the fully connected layers. The method learns the filters of each convolutional layer from user-drawn markers in image regions that discriminate classes, allowing better user control and understanding of the training process. It does not rely on optimization based on backpropagation, and we demonstrate its advantages on the binary classification of coconut-tree aerial images against one of the most popular CNN models.
Semi-supervised deep learning based on label propagation in a 2D embedded space
Aug 02, 2020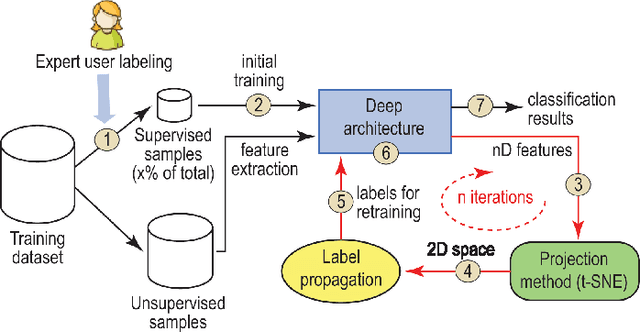
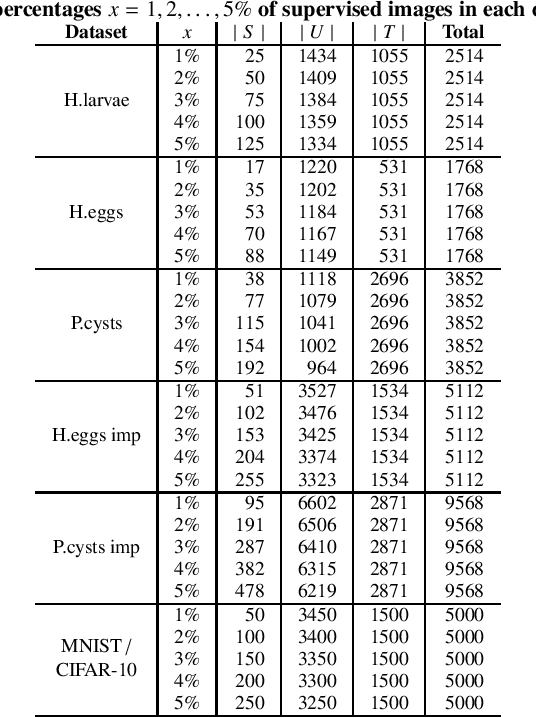

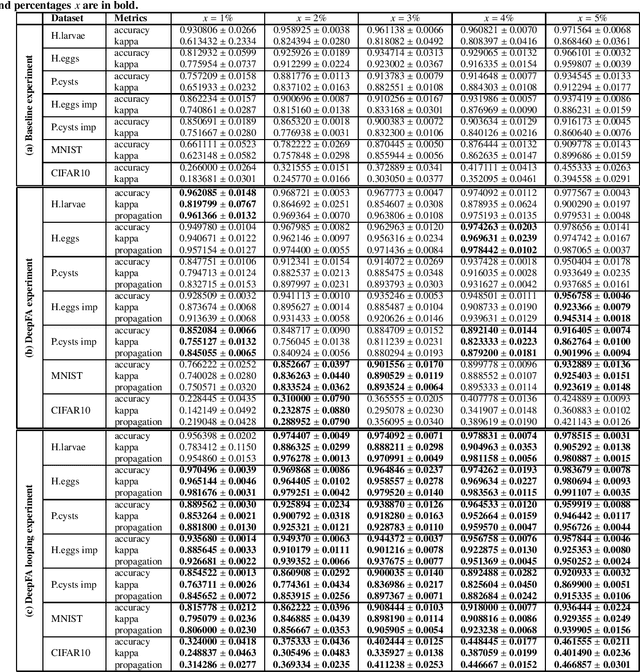
While convolutional neural networks need large labeled sets for training images, expert human supervision of such datasets can be very laborious. Proposed solutions propagate labels from a small set of supervised images to a large set of unsupervised ones to obtain sufficient truly-and-artificially labeled samples to train a deep neural network model. Yet, such solutions need many supervised images for validation. We present a loop in which a deep neural network (VGG-16) is trained from a set with more correctly labeled samples along iterations, created by using t-SNE to project the features of its last max-pooling layer into a 2D embedded space in which labels are propagated using the Optimum-Path Forest semi-supervised classifier. As the labeled set improves along iterations, it improves the features of the neural network. We show that this can significantly improve classification results on test data (using only 1\% to 5\% of supervised samples) of three private challenging datasets and two public ones.
Semi-Automatic Data Annotation guided by Feature Space Projection
Jul 27, 2020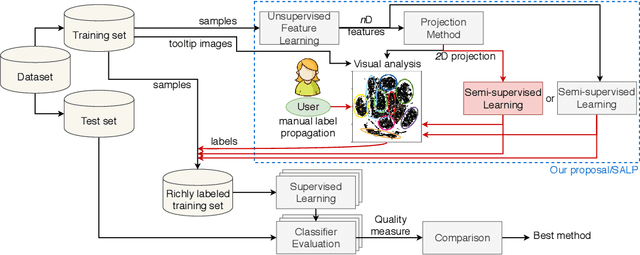
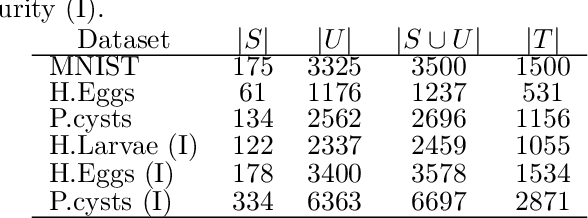

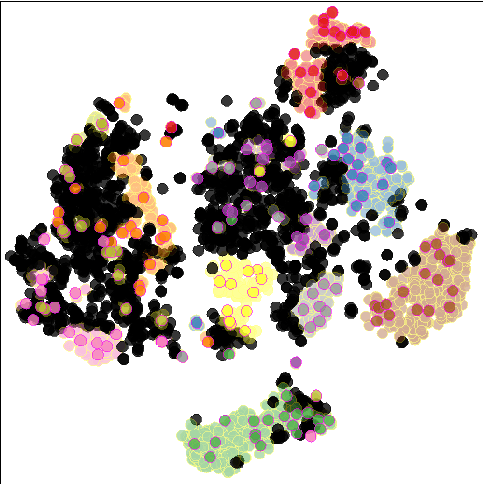
Data annotation using visual inspection (supervision) of each training sample can be laborious. Interactive solutions alleviate this by helping experts propagate labels from a few supervised samples to unlabeled ones based solely on the visual analysis of their feature space projection (with no further sample supervision). We present a semi-automatic data annotation approach based on suitable feature space projection and semi-supervised label estimation. We validate our method on the popular MNIST dataset and on images of human intestinal parasites with and without fecal impurities, a large and diverse dataset that makes classification very hard. We evaluate two approaches for semi-supervised learning from the latent and projection spaces, to choose the one that best reduces user annotation effort and also increases classification accuracy on unseen data. Our results demonstrate the added-value of visual analytics tools that combine complementary abilities of humans and machines for more effective machine learning.
OPFython: A Python-Inspired Optimum-Path Forest Classifier
Jan 28, 2020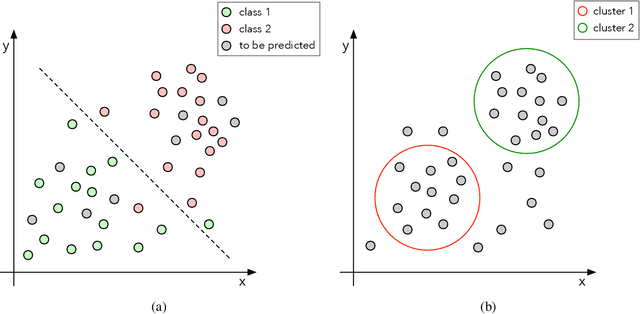
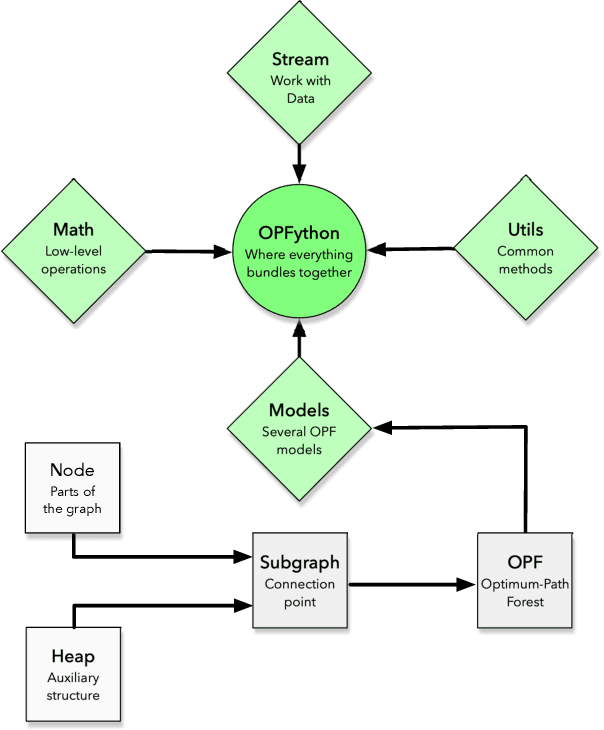
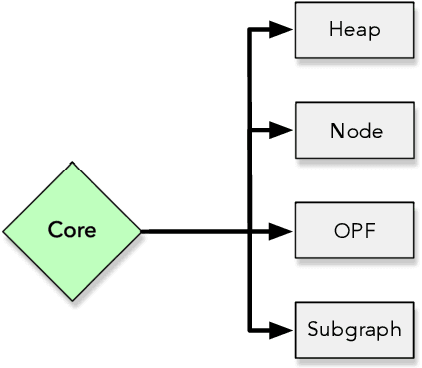
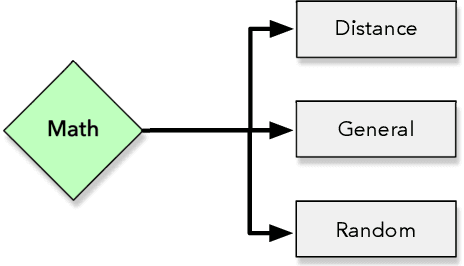
Machine learning techniques have been paramount throughout the last years, being applied in a wide range of tasks, such as classification, object recognition, person identification, image segmentation, among others. Nevertheless, conventional classification algorithms, e.g., Logistic Regression, Decision Trees, Bayesian classifiers, might lack complexity and diversity, not being suitable when dealing with real-world data. A recent graph-inspired classifier, known as the Optimum-Path Forest, has proven to be a state-of-the-art technique, comparable to Support Vector Machines and even surpassing it in some tasks. In this paper, we propose a Python-based Optimum-Path Forest framework, denoted as OPFython, where all of its functions and classes are based upon the original C language implementation. Additionally, as OPFython is a Python-based library, it provides a more friendly environment and a faster prototyping workspace than the C language.
FOMTrace: Interactive Video Segmentation By Image Graphs and Fuzzy Object Models
Jun 10, 2016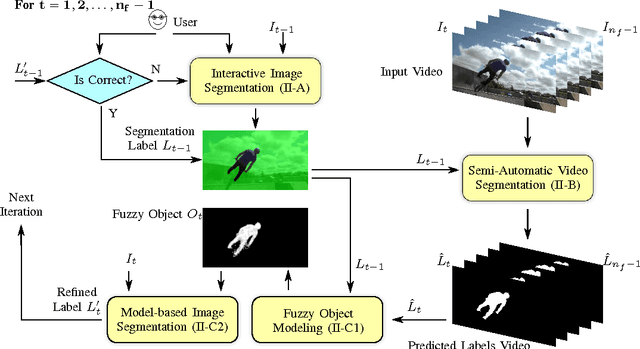


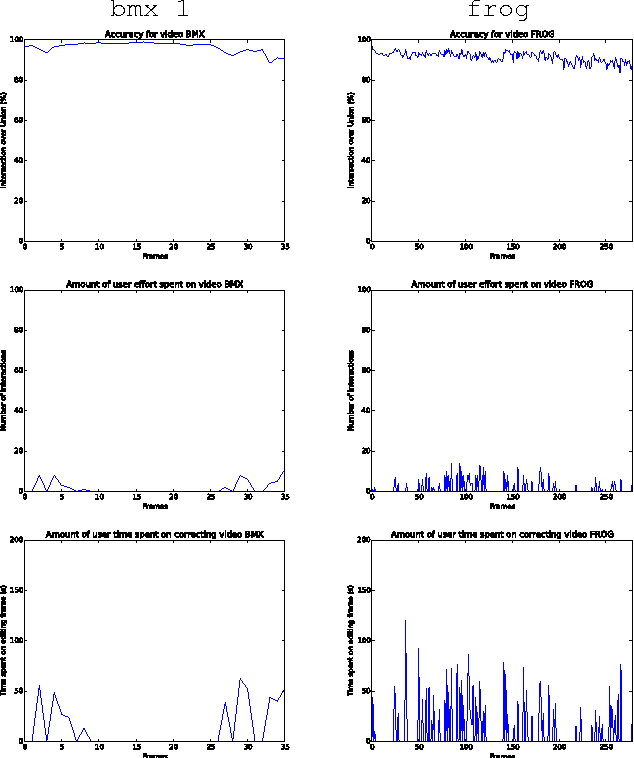
Common users have changed from mere consumers to active producers of multimedia data content. Video editing plays an important role in this scenario, calling for simple segmentation tools that can handle fast-moving and deformable video objects with possible occlusions, color similarities with the background, among other challenges. We present an interactive video segmentation method, named FOMTrace, which addresses the problem in an effective and efficient way. From a user-provided object mask in a first frame, the method performs semi-automatic video segmentation on a spatiotemporal superpixel-graph, and then estimates a Fuzzy Object Model (FOM), which refines segmentation of the second frame by constraining delineation on a pixel-graph within a region where the object's boundary is expected to be. The user can correct/accept the refined object mask in the second frame, which is then similarly used to improve the spatiotemporal video segmentation of the remaining frames. Both steps are repeated alternately, within interactive response times, until the segmentation refinement of the final frame is accepted by the user. Extensive experiments demonstrate FOMTrace's ability for tracing objects in comparison with state-of-the-art approaches for interactive video segmentation, supervised, and unsupervised object tracking.