 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
A Review on Scientific Knowledge Extraction using Large Language Models in Biomedical Sciences
Dec 04, 2024

The rapid advancement of large language models (LLMs) has opened new boundaries in the extraction and synthesis of medical knowledge, particularly within evidence synthesis. This paper reviews the state-of-the-art applications of LLMs in the biomedical domain, exploring their effectiveness in automating complex tasks such as evidence synthesis and data extraction from a biomedical corpus of documents. While LLMs demonstrate remarkable potential, significant challenges remain, including issues related to hallucinations, contextual understanding, and the ability to generalize across diverse medical tasks. We highlight critical gaps in the current research literature, particularly the need for unified benchmarks to standardize evaluations and ensure reliability in real-world applications. In addition, we propose directions for future research, emphasizing the integration of state-of-the-art techniques such as retrieval-augmented generation (RAG) to enhance LLM performance in evidence synthesis. By addressing these challenges and utilizing the strengths of LLMs, we aim to improve access to medical literature and facilitate meaningful discoveries in healthcare.
BioNeRF: Biologically Plausible Neural Radiance Fields for View Synthesis
Feb 11, 2024This paper presents BioNeRF, a biologically plausible architecture that models scenes in a 3D representation and synthesizes new views through radiance fields. Since NeRF relies on the network weights to store the scene's 3-dimensional representation, BioNeRF implements a cognitive-inspired mechanism that fuses inputs from multiple sources into a memory-like structure, improving the storing capacity and extracting more intrinsic and correlated information. BioNeRF also mimics a behavior observed in pyramidal cells concerning contextual information, in which the memory is provided as the context and combined with the inputs of two subsequent neural models, one responsible for producing the volumetric densities and the other the colors used to render the scene. Experimental results show that BioNeRF outperforms state-of-the-art results concerning a quality measure that encodes human perception in two datasets: real-world images and synthetic data.
Introducing Bode: A Fine-Tuned Large Language Model for Portuguese Prompt-Based Task
Jan 05, 2024Large Language Models (LLMs) are increasingly bringing advances to Natural Language Processing. However, low-resource languages, those lacking extensive prominence in datasets for various NLP tasks, or where existing datasets are not as substantial, such as Portuguese, already obtain several benefits from LLMs, but not to the same extent. LLMs trained on multilingual datasets normally struggle to respond to prompts in Portuguese satisfactorily, presenting, for example, code switching in their responses. This work proposes a fine-tuned LLaMA 2-based model for Portuguese prompts named Bode in two versions: 7B and 13B. We evaluate the performance of this model in classification tasks using the zero-shot approach with in-context learning, and compare it with other LLMs. Our main contribution is to bring an LLM with satisfactory results in the Portuguese language, as well as to provide a model that is free for research or commercial purposes.
Feature Selection and Hyperparameter Fine-tuning in Artificial Neural Networks for Wood Quality Classification
Oct 20, 2023Quality classification of wood boards is an essential task in the sawmill industry, which is still usually performed by human operators in small to median companies in developing countries. Machine learning algorithms have been successfully employed to investigate the problem, offering a more affordable alternative compared to other solutions. However, such approaches usually present some drawbacks regarding the proper selection of their hyperparameters. Moreover, the models are susceptible to the features extracted from wood board images, which influence the induction of the model and, consequently, its generalization power. Therefore, in this paper, we investigate the problem of simultaneously tuning the hyperparameters of an artificial neural network (ANN) as well as selecting a subset of characteristics that better describes the wood board quality. Experiments were conducted over a private dataset composed of images obtained from a sawmill industry and described using different feature descriptors. The predictive performance of the model was compared against five baseline methods as well as a random search, performing either ANN hyperparameter tuning and feature selection. Experimental results suggest that hyperparameters should be adjusted according to the feature set, or the features should be selected considering the hyperparameter values. In summary, the best predictive performance, i.e., a balanced accuracy of $0.80$, was achieved in two distinct scenarios: (i) performing only feature selection, and (ii) performing both tasks concomitantly. Thus, we suggest that at least one of the two approaches should be considered in the context of industrial applications.
Facial Point Graphs for Amyotrophic Lateral Sclerosis Identification
Jul 22, 2023Identifying Amyotrophic Lateral Sclerosis (ALS) in its early stages is essential for establishing the beginning of treatment, enriching the outlook, and enhancing the overall well-being of those affected individuals. However, early diagnosis and detecting the disease's signs is not straightforward. A simpler and cheaper way arises by analyzing the patient's facial expressions through computational methods. When a patient with ALS engages in specific actions, e.g., opening their mouth, the movement of specific facial muscles differs from that observed in a healthy individual. This paper proposes Facial Point Graphs to learn information from the geometry of facial images to identify ALS automatically. The experimental outcomes in the Toronto Neuroface dataset show the proposed approach outperformed state-of-the-art results, fostering promising developments in the area.
Extractive Text Summarization Using Generalized Additive Models with Interactions for Sentence Selection
Dec 21, 2022Automatic Text Summarization (ATS) is becoming relevant with the growth of textual data; however, with the popularization of public large-scale datasets, some recent machine learning approaches have focused on dense models and architectures that, despite producing notable results, usually turn out in models difficult to interpret. Given the challenge behind interpretable learning-based text summarization and the importance it may have for evolving the current state of the ATS field, this work studies the application of two modern Generalized Additive Models with interactions, namely Explainable Boosting Machine and GAMI-Net, to the extractive summarization problem based on linguistic features and binary classification.
A survey on text generation using generative adversarial networks
Dec 20, 2022This work presents a thorough review concerning recent studies and text generation advancements using Generative Adversarial Networks. The usage of adversarial learning for text generation is promising as it provides alternatives to generate the so-called "natural" language. Nevertheless, adversarial text generation is not a simple task as its foremost architecture, the Generative Adversarial Networks, were designed to cope with continuous information (image) instead of discrete data (text). Thus, most works are based on three possible options, i.e., Gumbel-Softmax differentiation, Reinforcement Learning, and modified training objectives. All alternatives are reviewed in this survey as they present the most recent approaches for generating text using adversarial-based techniques. The selected works were taken from renowned databases, such as Science Direct, IEEEXplore, Springer, Association for Computing Machinery, and arXiv, whereas each selected work has been critically analyzed and assessed to present its objective, methodology, and experimental results.
Improving Pre-Trained Weights Through Meta-Heuristics Fine-Tuning
Dec 19, 2022Machine Learning algorithms have been extensively researched throughout the last decade, leading to unprecedented advances in a broad range of applications, such as image classification and reconstruction, object recognition, and text categorization. Nonetheless, most Machine Learning algorithms are trained via derivative-based optimizers, such as the Stochastic Gradient Descent, leading to possible local optimum entrapments and inhibiting them from achieving proper performances. A bio-inspired alternative to traditional optimization techniques, denoted as meta-heuristic, has received significant attention due to its simplicity and ability to avoid local optimums imprisonment. In this work, we propose to use meta-heuristic techniques to fine-tune pre-trained weights, exploring additional regions of the search space, and improving their effectiveness. The experimental evaluation comprises two classification tasks (image and text) and is assessed under four literature datasets. Experimental results show nature-inspired algorithms' capacity in exploring the neighborhood of pre-trained weights, achieving superior results than their counterpart pre-trained architectures. Additionally, a thorough analysis of distinct architectures, such as Multi-Layer Perceptron and Recurrent Neural Networks, attempts to visualize and provide more precise insights into the most critical weights to be fine-tuned in the learning process.
PL-kNN: A Parameterless Nearest Neighbors Classifier
Sep 30, 2022

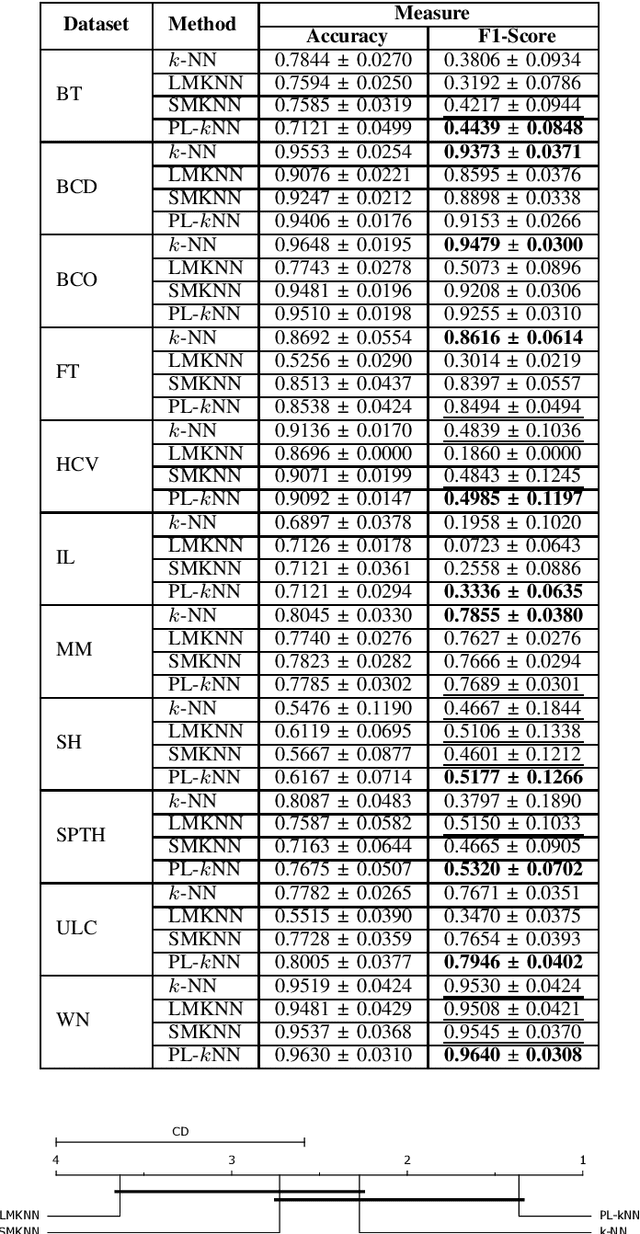
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.