 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Bode: A Fine-Tuned Large Language Model for Portuguese Prompt-Based Task
Jan 05, 2024Large Language Models (LLMs) are increasingly bringing advances to Natural Language Processing. However, low-resource languages, those lacking extensive prominence in datasets for various NLP tasks, or where existing datasets are not as substantial, such as Portuguese, already obtain several benefits from LLMs, but not to the same extent. LLMs trained on multilingual datasets normally struggle to respond to prompts in Portuguese satisfactorily, presenting, for example, code switching in their responses. This work proposes a fine-tuned LLaMA 2-based model for Portuguese prompts named Bode in two versions: 7B and 13B. We evaluate the performance of this model in classification tasks using the zero-shot approach with in-context learning, and compare it with other LLMs. Our main contribution is to bring an LLM with satisfactory results in the Portuguese language, as well as to provide a model that is free for research or commercial purposes.
PL-kNN: A Parameterless Nearest Neighbors Classifier
Sep 30, 2022

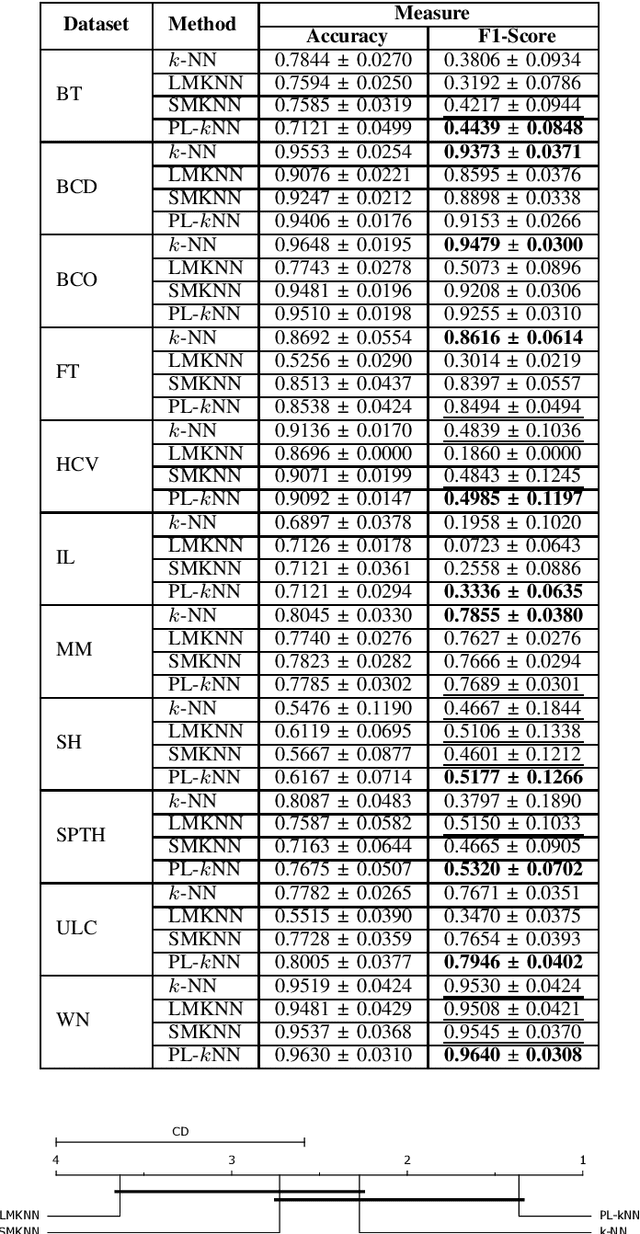
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.
$\text{O}^2$PF: Oversampling via Optimum-Path Forest for Breast Cancer Detection
Jan 14, 2021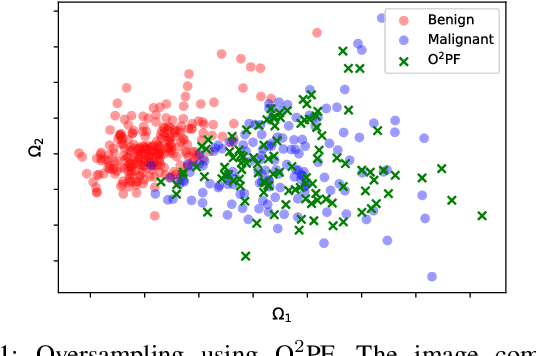
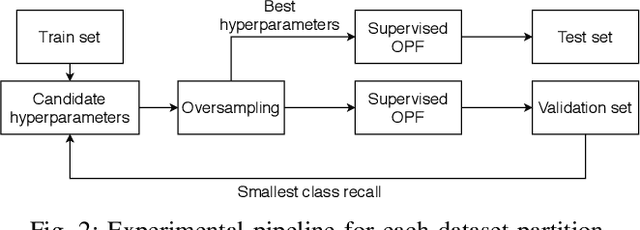
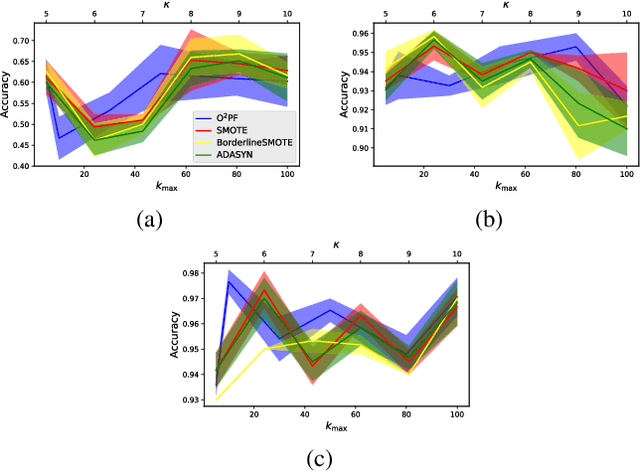
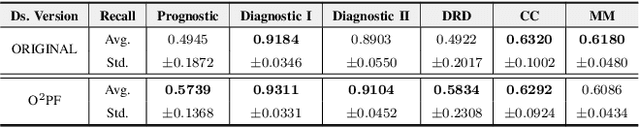
Breast cancer is among the most deadly diseases, distressing mostly women worldwide. Although traditional methods for detection have presented themselves as valid for the task, they still commonly present low accuracies and demand considerable time and effort from professionals. Therefore, a computer-aided diagnosis (CAD) system capable of providing early detection becomes hugely desirable. In the last decade, machine learning-based techniques have been of paramount importance in this context, since they are capable of extracting essential information from data and reasoning about it. However, such approaches still suffer from imbalanced data, specifically on medical issues, where the number of healthy people samples is, in general, considerably higher than the number of patients. Therefore this paper proposes the $\text{O}^2$PF, a data oversampling method based on the unsupervised Optimum-Path Forest Algorithm. Experiments conducted over the full oversampling scenario state the robustness of the model, which is compared against three well-established oversampling methods considering three breast cancer and three general-purpose tasks for medical issues datasets.