 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overlooked Role of Context-Sensitive Dendrites
Aug 20, 2024To date, most dendritic studies have predominantly focused on the apical zone of pyramidal two-point neurons (TPNs) receiving only feedback (FB) connections from higher perceptual layers and using them for learning. Recent cellular neurophysiology and computational neuroscience studies suggests that the apical input (context), coming from feedback and lateral connections, is multifaceted and far more diverse, with greater implications for ongoing learning and processing in the brain than previously realized. In addition to the FB, the apical tuft receives signals from neighboring cells of the same network as proximal (P) context, other parts of the brain as distal (D) context, and overall coherent information across the network as universal (U) context. The integrated context (C) amplifies and suppresses the transmission of coherent and conflicting feedforward (FF) signals, respectively. Specifically, we show that complex context-sensitive (CS)-TPNs flexibly integrate C moment-by-moment with the FF somatic current at the soma such that the somatic current is amplified when both feedforward (FF) and C are coherent; otherwise, it is attenuated. This generates the event only when the FF and C currents are coherent, which is then translated into a singlet or a burst based on the FB information. Spiking simulation results show that this flexible integration of somatic and contextual currents enables the propagation of more coherent signals (bursts), making learning faster with fewer neurons. Similar behavior is observed when this functioning is used in conventional artificial networks, where orders of magnitude fewer neurons are required to process vast amounts of heterogeneous real-world audio-visual (AV) data trained using backpropagation (BP). The computational findings presented here demonstrate the universality of CS-TPNs, suggesting a dendritic narrative that was previously overlooked.
Cooperation Is All You Need
May 16, 2023Going beyond 'dendritic democracy', we introduce a 'democracy of local processors', termed Cooperator. Here we compare their capabilities when used in permutation-invariant neural networks for reinforcement learning (RL), with machine learning algorithms based on Transformers, such as ChatGPT. Transformers are based on the long-standing conception of integrate-and-fire 'point' neurons, whereas Cooperator is inspired by recent neurobiological breakthroughs suggesting that the cellular foundations of mental life depend on context-sensitive pyramidal neurons in the neocortex which have two functionally distinct points. We show that when used for RL, an algorithm based on Cooperator learns far quicker than that based on Transformer, even while having the same number of parameters.
Unlocking the potential of two-point cells for energy-efficient training of deep nets
Oct 24, 2022Context-sensitive two-point layer 5 pyramidal cells (L5PC) were discovered as long ago as 1999. However, the potential of this discovery to provide useful neural computation has yet to be demonstrated. Here we show for the first time how a transformative L5PC-driven deep neural network (DNN), termed the multisensory cooperative computing (MCC) architecture, can effectively process large amounts of heterogeneous real-world audio-visual (AV) data, using far less energy compared to best available `point' neuron-driven DNNs. A novel highly-distributed parallel implementation on a Xilinx UltraScale+ MPSoC device estimates energy savings up to $245759 \times 50000$ $\mu$J (i.e., $62\%$ less than the baseline model in a semi-supervised learning setup) where a single synapse consumes $8e^{-5}\mu$J. In a supervised learning setup, the energy-saving can potentially reach up to 1250x less (per feedforward transmission) than the baseline model. This remarkable performance in pilot experiments demonstrates the embodied neuromorphic intelligence of our proposed L5PC based MCC architecture that contextually selects the most salient and relevant information for onward transmission, from overwhelmingly large multimodal information utilised at the early stages of on-chip training. Our proposed approach opens new cross-disciplinary avenues for future on-chip DNN training implementations and posits a radical shift in current neuromorphic computing paradigms.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022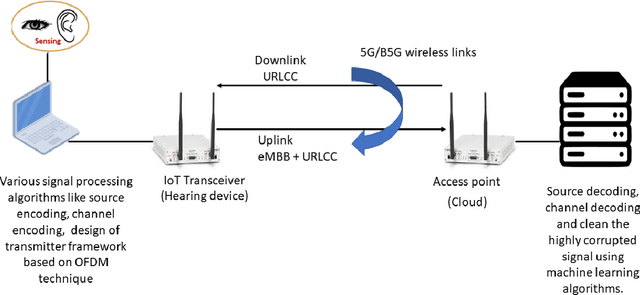
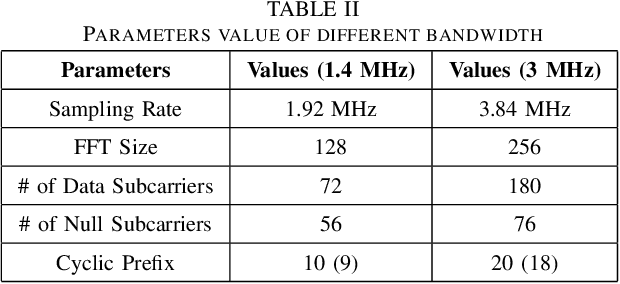
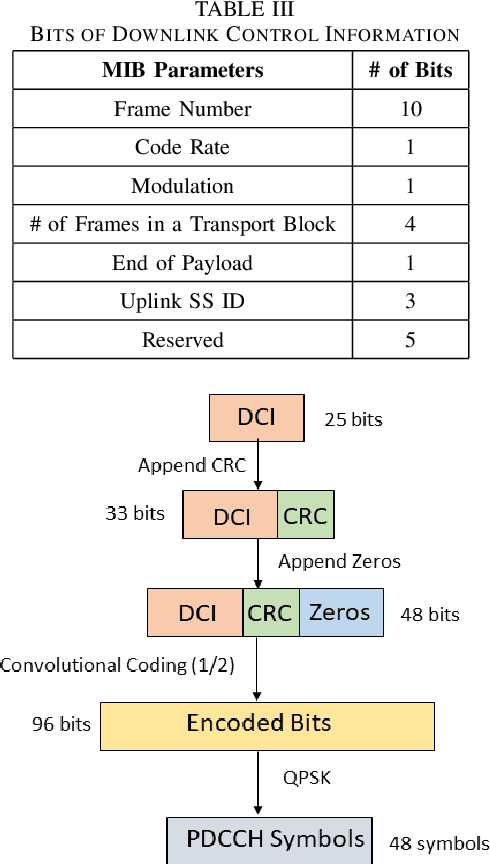
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
PL-kNN: A Parameterless Nearest Neighbors Classifier
Sep 30, 2022

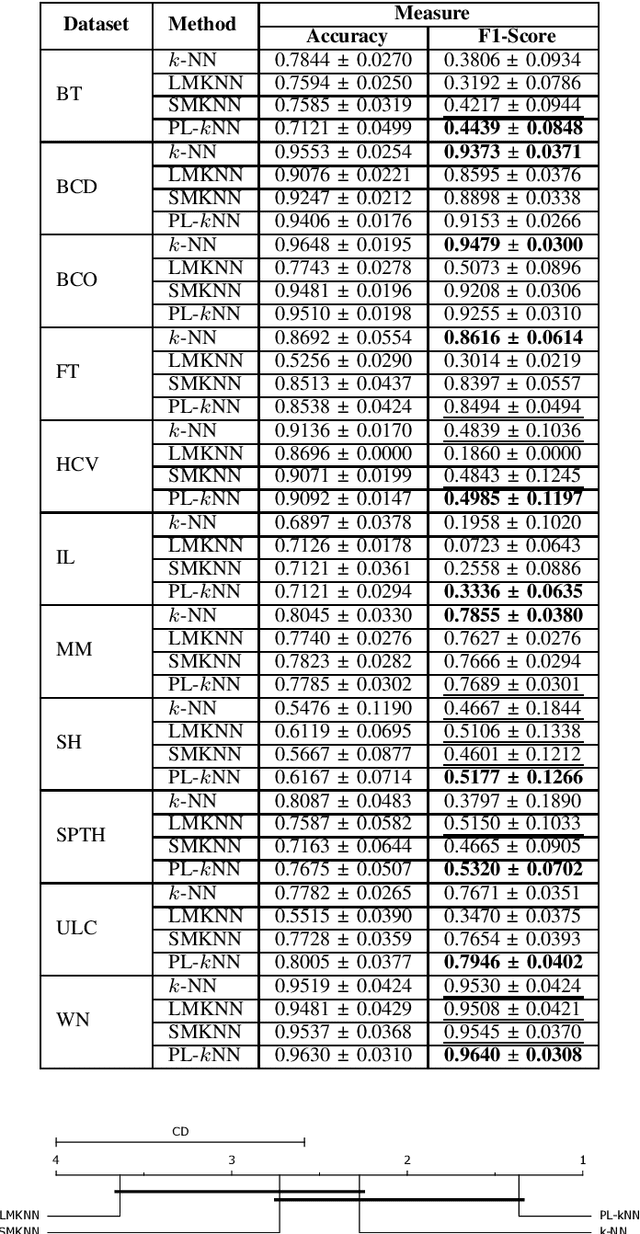
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.
Multimodal Speech Enhancement Using Burst Propagation
Sep 07, 2022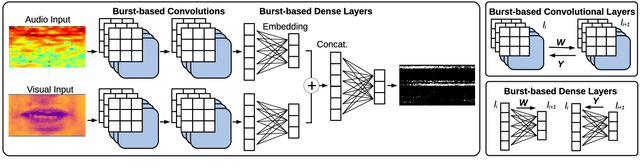
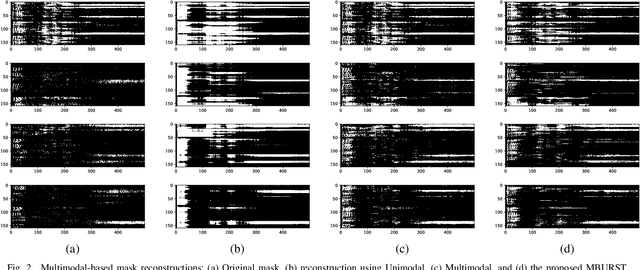
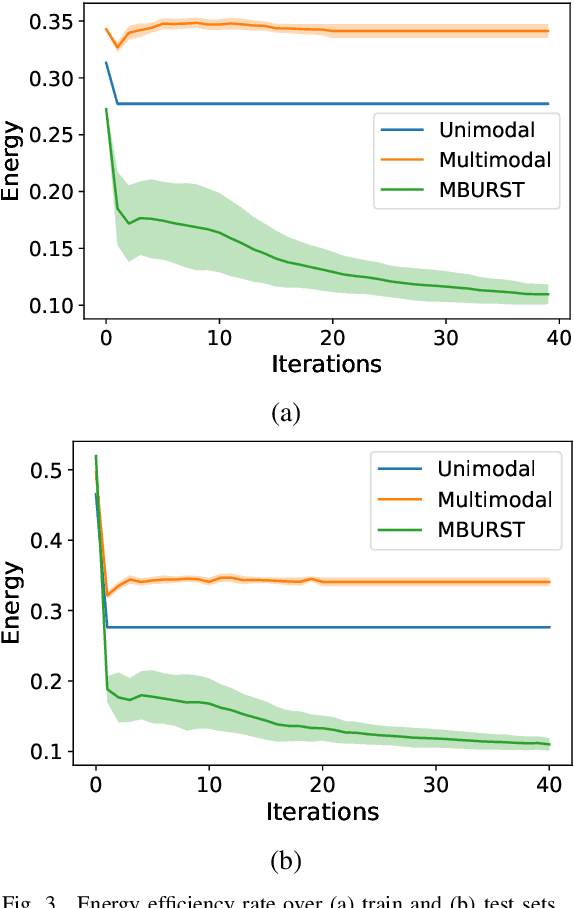
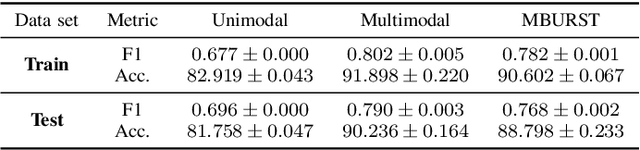
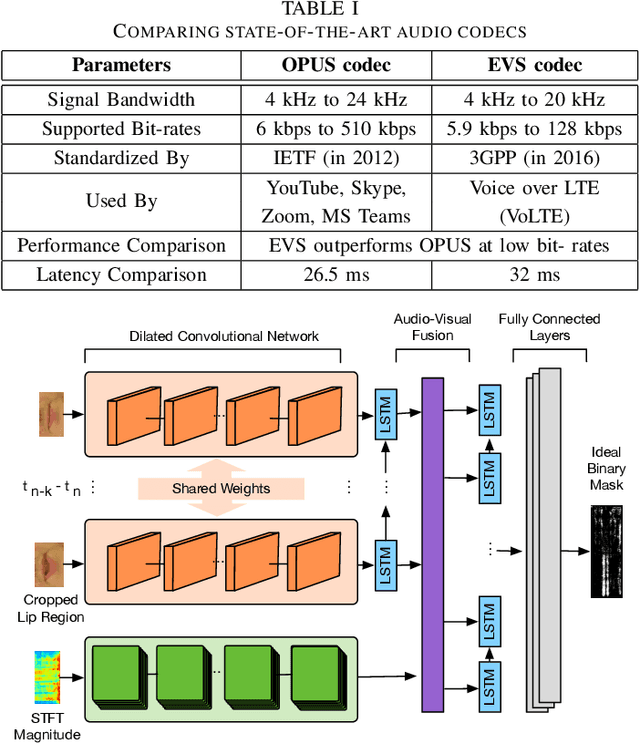
This paper proposes the MBURST, a novel multimodal solution for audio-visual speech enhancements that consider the most recent neurological discoveries regarding pyramidal cells of the prefrontal cortex and other brain regions. The so-called burst propagation implements several criteria to address the credit assignment problem in a more biologically plausible manner: steering the sign and magnitude of plasticity through feedback, multiplexing the feedback and feedforward information across layers through different weight connections, approximating feedback and feedforward connections, and linearizing the feedback signals. MBURST benefits from such capabilities to learn correlations between the noisy signal and the visual stimuli, thus attributing meaning to the speech by amplifying relevant information and suppressing noise. Experiments conducted over a Grid Corpus and CHiME3-based dataset show that MBURST can reproduce similar mask reconstructions to the multimodal backpropagation-based baseline while demonstrating outstanding energy efficiency management, reducing the neuron firing rates to values up to \textbf{$70\%$} lower. Such a feature implies more sustainable implementations, suitable and desirable for hearing aids or any other similar embedded systems.
Context-sensitive neocortical neurons transform the effectiveness and efficiency of neural information processing
Jul 15, 2022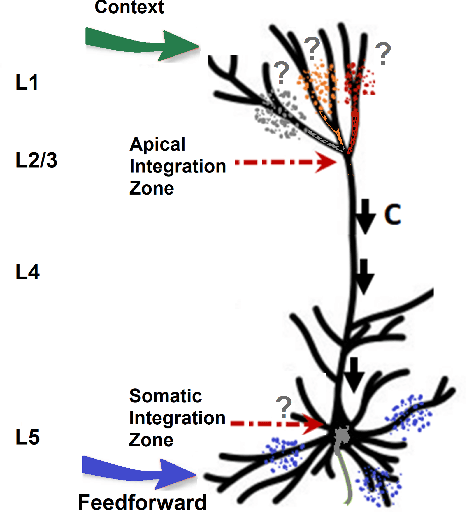
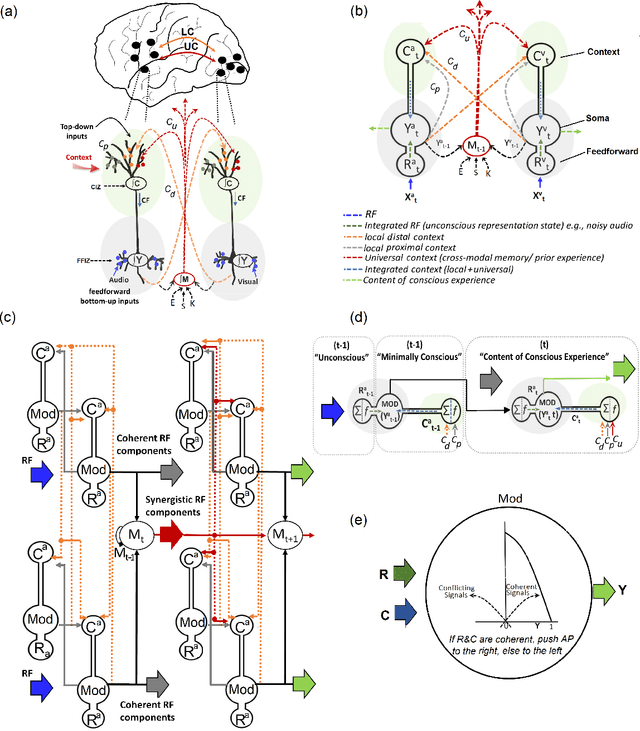
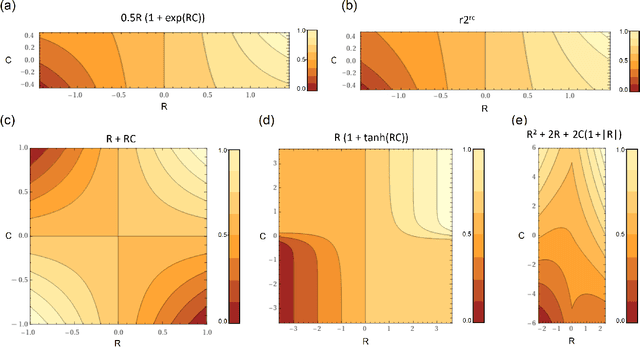
There is ample neurobiological evidence that context-sensitive neocortical neurons use their apical inputs as context to amplify the transmission of coherent feedforward (FF) inputs. However, it has not been demonstrated until now how this known mechanism can provide useful neural computation. Here we show for the first time that the processing and learning capabilities of this form of neural information processing are well-matched to the abilities of mammalian neocortex. Specifically, we show that a network composed of such local processors restricts the transmission of conflicting information to higher levels and greatly reduces the amount of activity required to process large amounts of heterogeneous real-world data e.g., when processing audiovisual speech, these local processors use seen lip movements to selectively amplify FF transmission of the auditory information that those movements generate and vice versa. As this mechanism is shown to be far more effective and efficient than the best available forms of deep neural nets, it offers a step-change in understanding the brain's mysterious energy-saving mechanism and inspires advances in designing enhanced forms of biologically plausible machine learning algorithms.
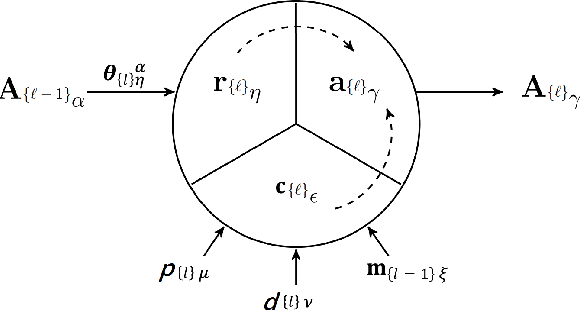
Canonical Cortical Graph Neural Networks and its Application for Speech Enhancement in Future Audio-Visual Hearing Aids
Jun 06, 2022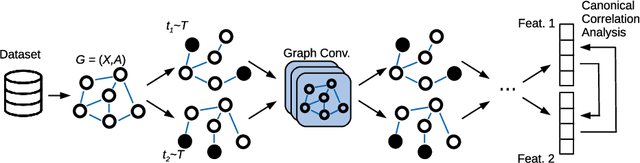
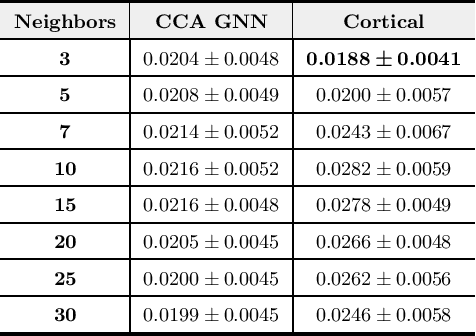
Despite the recent success of machine learning algorithms, most of these models still face several drawbacks when considering more complex tasks requiring interaction between different sources, such as multimodal input data and logical time sequence. On the other hand, the biological brain is highly sharpened in this sense, empowered to automatically manage and integrate such a stream of information through millions of years of evolution. In this context, this paper finds inspiration from recent discoveries on cortical circuits in the brain to propose a more biologically plausible self-supervised machine learning approach that combines multimodal information using intra-layer modulations together with canonical correlation analysis (CCA), as well as a memory mechanism to keep track of temporal data, the so-called Canonical Cortical Graph Neural networks. The approach outperformed recent state-of-the-art results considering both better clean audio reconstruction and energy efficiency, described by a reduced and smother neuron firing rate distribution, suggesting the model as a suitable approach for speech enhancement in future audio-visual hearing aid devices.
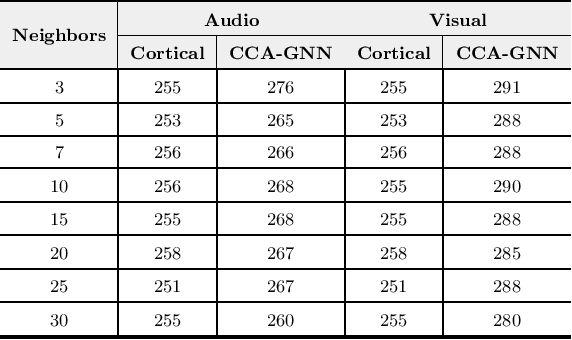
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022
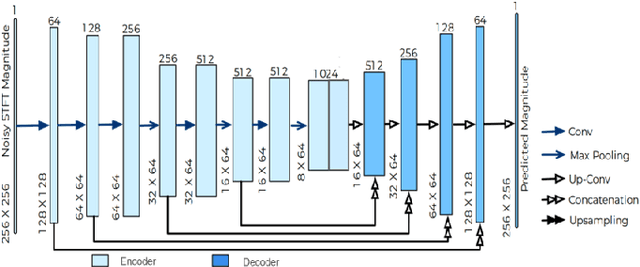
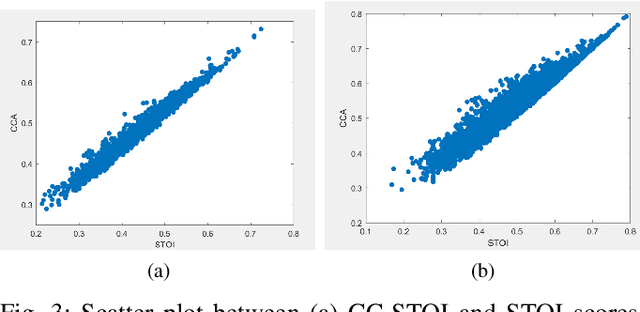
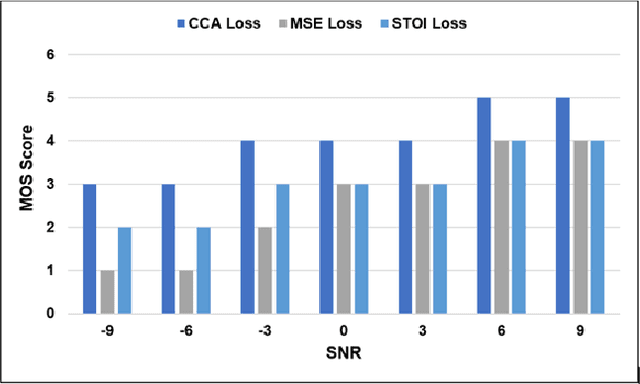
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022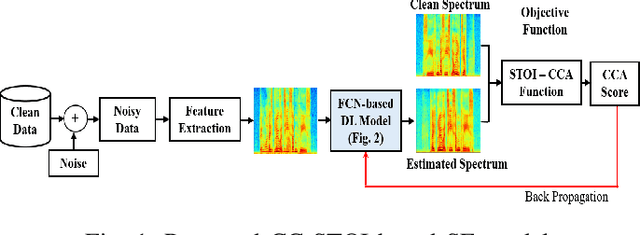

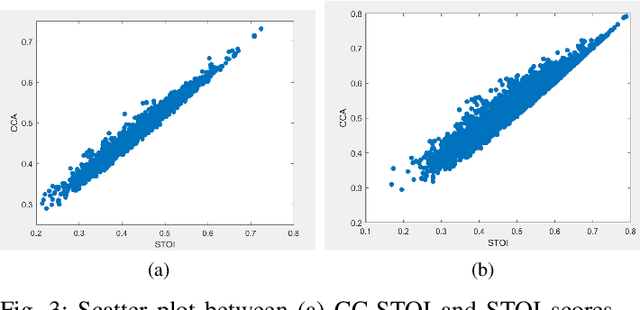
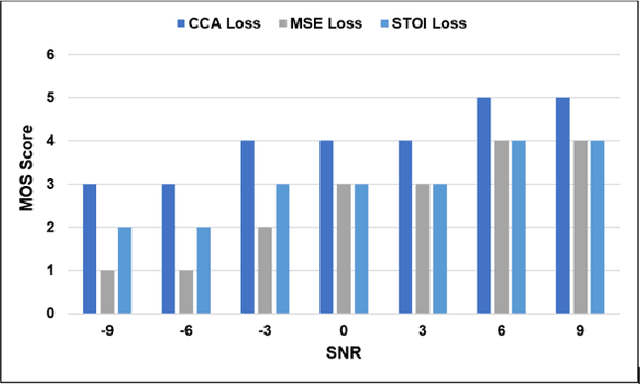
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.